Python内部很地方都使用着dict这种结构,在对象属性__dict__就是一个字典,所以对其效率要求很高。
dict采用了哈希表,最低能在 O(1)时间内完成搜索。同样的java的HashMap也是采用了哈希表实现,不同是dict在发生哈希冲突的时候采用了开放寻址法,而HashMap采用了链接法。
开放寻址法

优点
- 记录更容易进行序列化(serialize)操作
- 如果记录总数可以预知,可以创建完美哈希函数,此时处理数据的效率是非常高的
缺点
- 存储记录的数目不能超过桶数组的长度,如果超过就需要扩容,而扩容会导致某次操作的时间成本飙升,这在实时或者交互式应用中可能会是一个严重的缺陷
- 使用探测序列,有可能其计算的时间成本过高,导致哈希表的处理性能降低
- 由于记录是存放在桶数组中的,而桶数组必然存在空槽,所以当记录本身尺寸(size)很大并且记录总数规模很大时,空槽占用的空间会导致明显的内存浪费
- 删除记录时,比较麻烦。比如需要删除记录a,记录b是在a之后插入桶数组的,但是和记录a有冲突,是通过探测序列再次跳转找到的地址,所以如果直接删除a,a的位置变为空槽,而空槽是查询记录失败的终止条件,这样会导致记录b在a的位置重新插入数据前不可见,所以不能直接删除a,而是设置删除标记。这就需要额外的空间和操作。
想要自己实现一个dict可以继承 collection 的 UserDict,里面已经封装了常用的方法。
下面是我根据自己的理解去用python实现的字典,简化了很的功能,比如对象缓冲池、String哈希的优化等等,如果有错误的或者更好的实现方式请指出。因为python没有纯粹的数组结构,所以数组也是借用list实现的.
代码:
#python3.6
from collections import namedtuple
class SimpleArray(object):
#简单的数组类实现
def __init__(self, mix):
self.container = [None for i in range(mix)]
def __len__(self):
return len(self.container)
def __setitem__(self, key, value):
return self.container.__setitem__(key,value)
def __getitem__(self, item):
return self.container.__getitem__(item)
def __delitem__(self, key):
return self.container.__setitem__(key, None)
def __str__(self):
return str(self.container)
class SimpleDict(object):
#简单的字典类实现
Init_length = 8 # 初始化的大小
Load_factor = 2/3 # 扩容因子
def __init__(self):
self._array_len = SimpleDict.Init_length
self._array = SimpleArray(self._array_len)
self._used = 0
self.dictObj = namedtuple("dictObj","key value") # 这里其实可以用数组也可以的,namedtuple是为了让代码更可读
def __getitem__(self, item):
key = self._hash(item)
dictObj = self._array[key]
if dictObj is not None and dictObj.key == item:
return dictObj.value
else:
for new_key in self._second_hash(key):
if self._array[new_key] is not None and item == self._array[new_key].key:
return self._array[new_key].value
def __setitem__(self, key, value):
# 计算是否需要扩容
if (self._used / self._array_len) > SimpleDict.Load_factor:
self._new_array()
#根据键的hash值来计算得出位置索引
hash_key = self._hash(key)
new_key = self._second_hash(hash_key)
while True:
if self._array[hash_key] is None or key == self._array[hash_key].key:
break
# 发生哈希碰撞根据二次探查函数得出下一个索引的位置
hash_key = next(new_key)
if abs(hash_key) >= self._array_len:
self._new_array()
hash_key = self._hash(key)
# 找到空位将键值对象放入
self._array[hash_key] = self.dictObj(key, value)
self._used += 1
def __delitem__(self, key):
hash_key = self._hash(key)
if key != self._array[hash_key].key:
for new_key in self._second_hash(hash_key):
if key == self._array[new_key].key:
hash_key = new_key
self._array[hash_key] = None
self._used -= 1
def _hash(self, key):
# 计算哈希值
return hash(key) & (self._array_len-1)
def _second_hash(self, hash_key):
# 简单的二次探查函数实现
count = 1
for i in range(self._array_len):
yield hash_key + count**2
yield hash_key - count**2
count += 1
def _new_array(self):
# 扩容
old_array = self._array
self._array_len = self._array_len * 2 # 扩容2倍大小
self._array = SimpleArray(self._array_len)
for i in range(len(old_array)):
dictObj = old_array[i]
if dictObj is not None:
self[dictObj.key] = dictObj.value
def __str__(self):
result = ", ".join("%s:%s"%(obj.key, obj.value)
for obj in self._array
if obj is not None)
return "{" + result + "}"
if __name__ == '__main__':
d = SimpleDict()
for i in range(20):
d[str(i)] = i
print(d)
print(d["10"])
del d["11"]
print(d)链接法
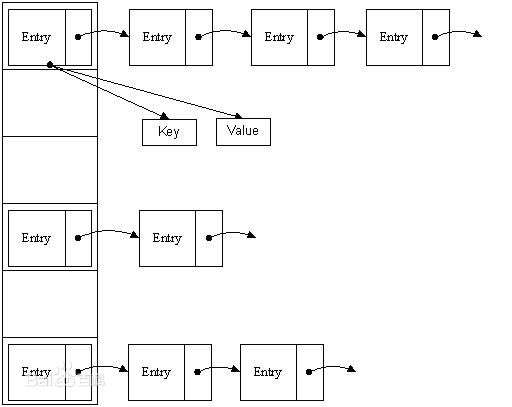
优点
- 对于记录总数频繁可变的情况,处理的比较好(也就是避免了动态调整的开销)
- 由于记录存储在结点中,而结点是动态分配,不会造成内存的浪费,所以尤其适合那种记录本身尺寸(size)很大的情况,因为此时指针的开销可以忽略不计了
- 删除记录时,比较方便,直接通过指针操作即可
缺点
- 存储的记录是随机分布在内存中的,这样在查询记录时,相比结构紧凑的数据类型(比如数组),哈希表的跳转访问会带来额外的时间开销
- 如果所有的 key-value 对是可以提前预知,并之后不会发生变化时(即不允许插入和删除),可以人为创建一个不会产生冲突的完美哈希函数(perfect hash function),此时封闭散列的性能将远高于开放散列
- 由于使用指针,记录不容易进行序列化(serialize)操作
其中有很重要的两个参数影响其性能: 初始容量和加载因子
dict:默认初始容量为8,加载因子为2/3
HashMap: 默认初始容量为16, 加载因子为0.75
两者相同的是扩容的长度必需是2的N次方