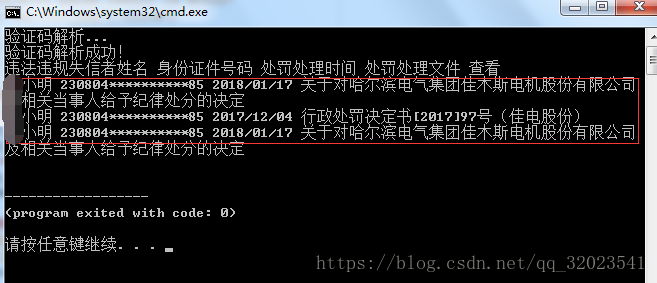
这里我们要通过实际展示爬取证券期货市场失信记录平台上的搜索数据。
页面:http://shixin.csrc.gov.cn/honestypub 如下:
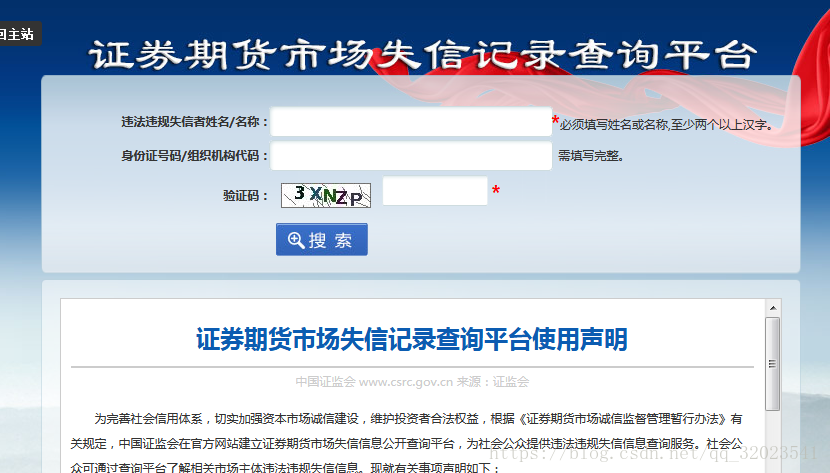
我们现在要通过爬虫给定一个 姓名,机构代码 ,爬取获得的结果。
这里主要说明两点:
1. 这是一个动态网页,因此我采用 selenium 方法。
2.这里的验证码图片并不在源码内,因此前面的通过 css 选择器直接下载的方式是不行的。并且给定的验证码图片的连接即使一样,生成的验证码也是随机的,因此我们并不能通过源码中给定链接下载验证码这种方式。
验证码部分在源代码解析如下:

这是一个链接,并且这个链接生成的验证码是会变动,并不能通过这个链接下载到我们要的验证码图形。因此我的处理方案是直接截图下来进行解析。解析采用 pytesseract 模块,但其实里面源码就是调用 tesseract ,因此要安装这个。
爬虫完整代码如下:
# -*- coding:utf-8 -*-
from PIL import Image
import pytesseract
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
# 隐藏浏览器的显式启动,在调试过程中不要隐藏
from selenium.webdriver.firefox.options import Options
ff_option = Options()
ff_option.add_argument('-headless')
# 指定驱动程序
chromedriver = "C:\Program Files\Mozilla Firefox\geckodriver.exe"
# 火狐驱动
driver = webdriver.Firefox(executable_path=chromedriver,firefox_options = ff_option)
# 想要在选定的浏览器中加载网页,可以调用 get() 方法,进入查询网页
driver.get("http://shixin.csrc.gov.cn/honestypub")
# 定义解析验证码的函数
def parse_ycode():
# 先截取整个页面保存为 screenshot.png
driver.get_screenshot_as_file("screenshot.png")
# 获取验证码位置
captchaElem = driver.find_element_by_xpath('//*[@id="captcha_img"]')
captchaX = int(captchaElem.location['x'])
captchaY = int(captchaElem.location['y'])
captchaWidth = captchaElem.size['width']
captchaHeight = captchaElem.size['height']
captchaRight = captchaX + captchaWidth
captchaBottom = captchaY + captchaHeight
# 打开图片并按照验证码的位置截取验证码图形
imgObject = Image.open("screenshot.png")
im = imgObject.crop((captchaX, captchaY, captchaRight, captchaBottom))
# 处理验证码图形便于解析
gray = im.convert('L')
gray = gray.point(lambda x: 0 if x < 100 else 255,'1')
yanzhengma = pytesseract.image_to_string(gray). \
strip(" ").replace(".","").replace("-","").replace("_","")
# 验证码的长度应该是 5 ,否则就是解析错误了,所以返回 None
if len(yanzhengma) == 5:
return yanzhengma
else:
return None
# 获取验证码函数,主要是在解析结果为 None 时重新刷新验证码进行解析
def get_ycode(name,card = ""):
# 先 click,不要直接 send_keys,否则会刷新验证码
driver.find_element_by_id("objName").click()
driver.find_element_by_id("objName").clear()
driver.find_element_by_id("objName").send_keys(name)
driver.find_element_by_id("realCardNumber").click()
driver.find_element_by_id("realCardNumber").clear()
driver.find_element_by_id("realCardNumber").send_keys(card)
print "验证码解析..."
while True:
ycode = parse_ycode()
if ycode is None:
# 如果解析错误,刷新验证码重新解析
driver.find_element_by_id("captcha_img").click()
else:
break
return ycode
def reparse():
print "flush ycode again,because parse result is error"
driver.find_element_by_id("captcha_img").click()
return get_ycode()
if __name__ == "__main__":
while True:
# 解析验证码
ycode = get_ycode("小明".decode("gbk"),card = "")
# 输入验证码
driver.find_element_by_id("ycode").click()
driver.find_element_by_id("ycode").clear()
driver.find_element_by_id("ycode").send_keys(ycode)
# 模拟点击搜索按钮 点击 search
driver.find_element_by_id("querybtn").click()
# 获取验证码输入的结果
res = driver.find_element_by_css_selector(".search_bg > table:nth-child(2)\
> tbody:nth-child(1) > tr:nth-child(3) > td:nth-child(4)")
res = res.text
# 如果解析出错,则重新刷新验证码解析
if res.strip() == "验证码错误!".decode("gbk"):
print "解析验证码不正确,重新刷新验证码..."
driver.find_element_by_id("captcha_img").click()
continue
else:
print "验证码解析成功!"
break
# 验证码正确后获取结果
result = driver.find_element_by_css_selector("#sorttab2")
print result.text
driver.close()浏览器查询结果如图:
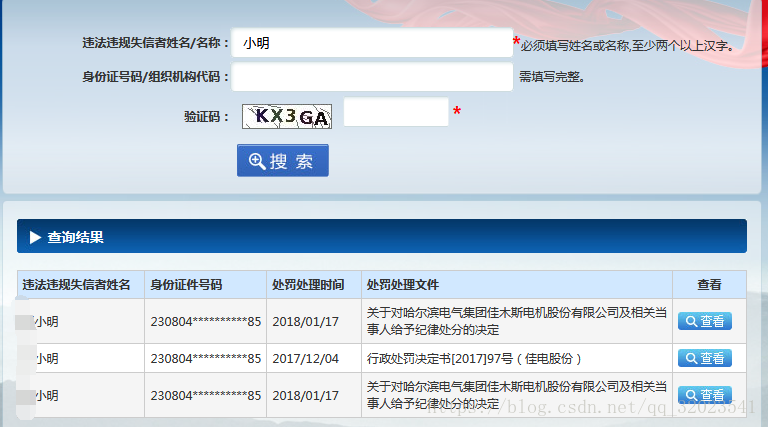
爬取结果如下: