- 分布式服务跟踪:Spring Cloud Sleuth
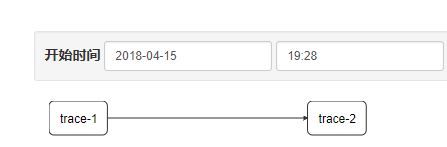
随着业务的发展,系统规模也会变得越来越大,各微服务间的调用关系也变得越来越错综复杂。通常一个由客户端发起的请求在后端系统中会经过多个不同的微服务调用来协同产生最后的请求结果,在复杂的微服务架构系统中,几乎每一个前端请求都会形成一条复杂的分布式服务调用链路,在每条链路中任何一个依赖服务出现延迟高或错误的时候都有可能引起请求最后的失败。这时候,对于每个请求,全链路调用的跟踪就变得越来越重要,通过实现对请求调用的跟踪可以帮助我们快速发现错误根源以及监控分析每条请求链路上的性能瓶颈等。
1. 准备工作,构建一些基础的设施和应用:
◆ 服务注册中心:demo-eureka-server,这里不做赘述,直接使用之前构建的工程即可。
◆ 微服务应用:demo-trace-1,实现一个REST接口/trace-1,调用该接口后将触发对trace-2应用的调用。具体如下:
1). 创建一个基础的sprigboot应用,命名为demo-trace-1,加入web、eureka、ribbon依赖。
2). 创建应用主类:

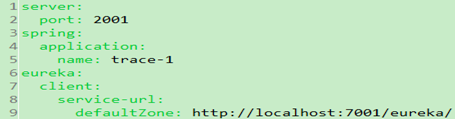
3). 在src\main\resources目录下创建application.yml文件:
4). 创建一个基础的sprigboot应用,命名为demo-trace-2,加入web、eureka、ribbon依赖。
5). 创建应用主类:
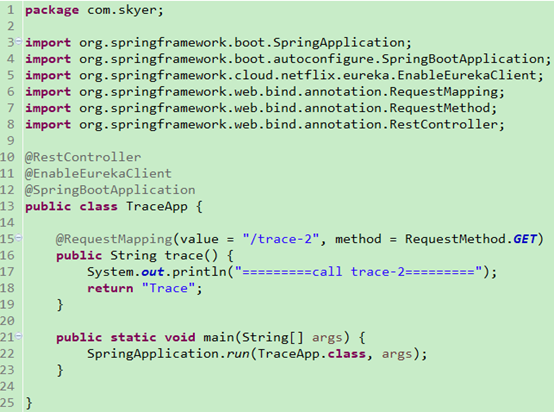
6). 在src\main\resources目录下创建application.yml文件:
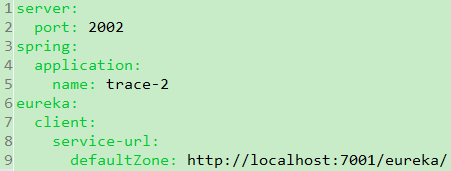
7). 将demo-eureka-server、demo-trace-1和demo-trace-2三个应用都启动起来。测试trace-1接口,确认返回无误:

2. 完成了准备工作之后,为上面的trace-1和trace-2添加服务跟踪功能。在trace-1和trace-2的pom.xml文件中添加相关依赖:

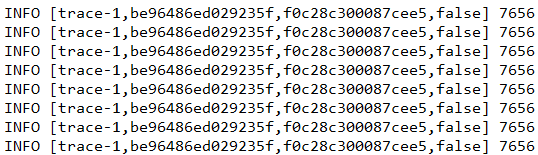
3. 重启trace-1和trace-2,再次调用trace-1接口,观察trace-1控制台,一些日志信息,这些元素正是实现分布式服务跟踪的重要组成部分:
- 与Zipkin整合
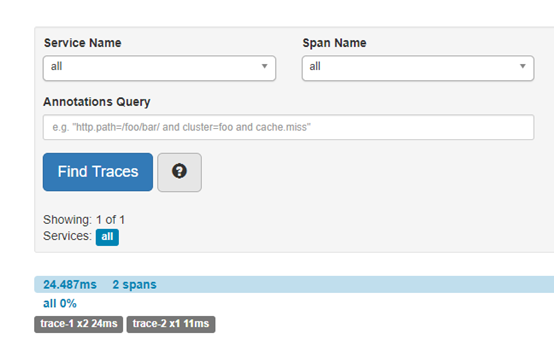
Zipkin是Twitter的一个开源项目,它基于Google Dapper实现。可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的REST API接口来辅助查询跟踪数据以实现对分布式系统的监控程序,从而及时发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源。除了面向开发的API接口之外,它还提供了方便的UI组件来帮助我们直观地搜索跟踪信息和分析请求链路明细,比如可以查询某段时间内各用户请求的处理时间等。
Zipkin主要的4个核心组件:
◆ Collector:收集器组件,它主要处理从外部系统发送过来的跟踪信息,将这些信息转化为Zipkin内部处理的Span格式,以支持后续的存储、分析、展示等功能。
◆ Storage:存储组件,它主要处理收集器接收到的跟踪信息,默认会将这些信息存储在内存中。也可以修改此存储策略,通过使用其他存储组件将跟踪信息存储到数据库中。
◆ RESTful API:API组件,它主要用来提供外部访问接口。比如给客户端展示工作信息,或是外接系统访问以实现监控等。
◆ Web UI:UI组件,基于API组件实现的上层应用。通过UI组件,用户可以方便而又直观地查询和分析跟踪信息。
1. 创建maven工程,骨架选择quickstart,命名为demo-zipkin-server
2. 加入相关依赖:

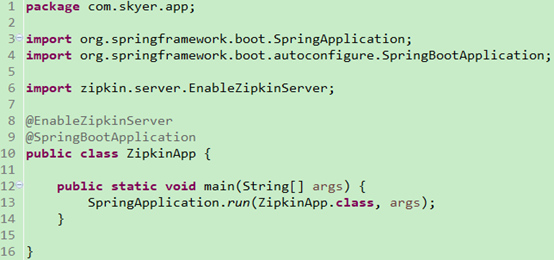
3. 创建启动类:
4. 在src\main\resources目录下创建application.properties文件:

5. 启动该工程(注:需要JDK1.8),并访问主页面:

6. 改造之前的trace-1和trace-2工程。在两个工程中都加入相关依赖:

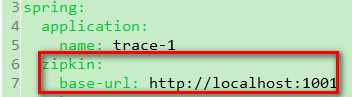
7. 在两个工程的配置文件中增加Zipkin Server的配置信息:
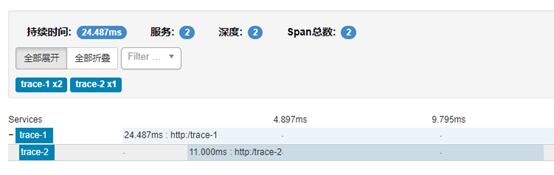
8. 重新启动两个工程,并访问trace-1接口,观察zipkin页面: