传智播客大数据day08
1、mapreduce框架设计思想
mapreduce结构一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、mapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程
运行流程:以wordcount(单词统计)为例
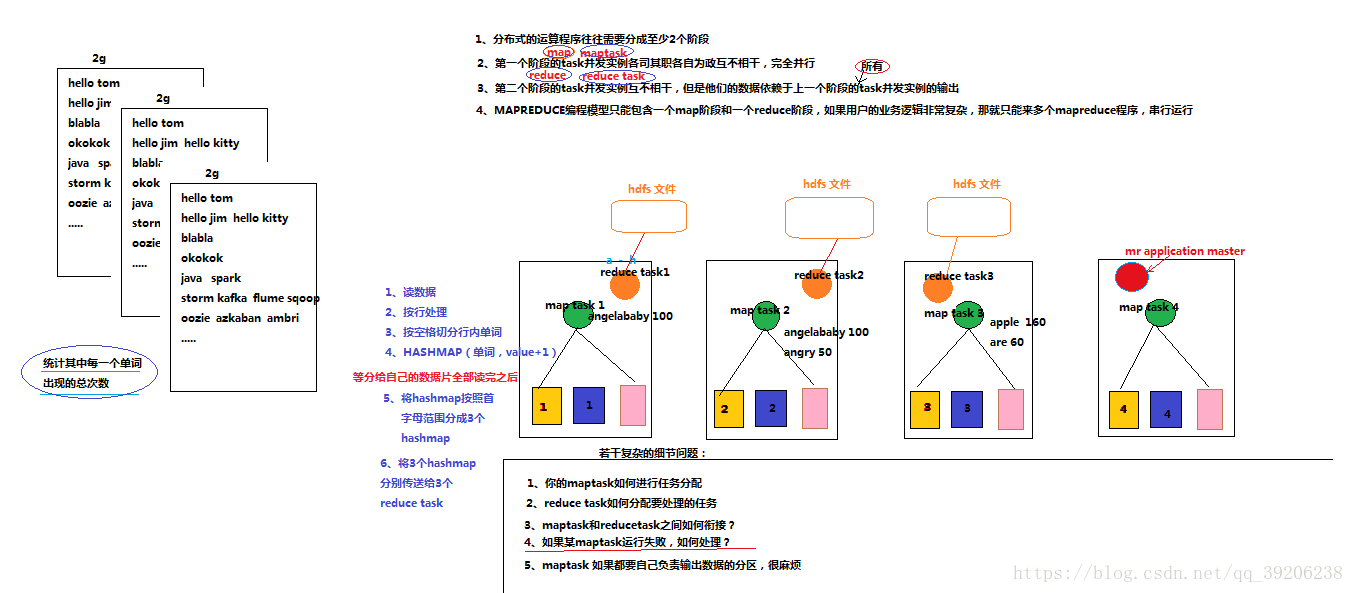
分析:
假如要统计三个文件中每个单词出现的次数
将文件上传到hdfs后,以图为例假设每个文件被切分为了4个block存在了4台机器上,mapreduce application master假设在第四台机器上,它来进行map task和reduce task的调度,如图示,每台机器上运行一个map task程序,每个map task分别计算自己所在机器上的三个block中每个单词出现的次数,最后每个map task将读到的a-h开头的单词与次数提交到第一台机器的reduce task,h-p开头的提交到第二台机器的reduce task,p-z开头的提交到第三台机器的reduce task,最后输出到三个hdfs文件。而对于调度问题都是由mapreduce application master来解决。
计算机制可以做如下思考。
1、每个map task 按行读取block中的数据,每行按照空格分开,然后存入到一个hashmap中,key为单词,value为数量,每读到相同的单词,value+1,读到以前没读过的单词,则新增key,value。
2、等到自己这台机器上的三个block都读完后,再创建三个hashmap将a-h的单词放到第一个hashmap,h-p开头的放到第二个hashmap,p-z开头的放到第三个hashmap。最后提交到对应的三个reduce task。
注:这样说只是为了更简单易懂,实际上存在一些差异的,比如是不是a-h就一定交给第一个reduce task,所有a开头的都会交给第一个reduce task?答案是否定的,实际上提交给哪个是根据每个单词的hashcode以及reduce task的数量决定的(参考 HashPartitioner类)。比如application单词以及出现次数就会交给第一个reduce task,而angry就可能交给第二个reduce task了。