一、概述
1、背景故事
在2000年和2004年美国总统大选中,候选人的得票非常接近。任一候选人得到的普选票数最大百分比为50.7%,最小百分比为47.9%。如果1%的候选人将手中的票投给另一个候选人,那么选举结果就会发生根本性的转折。实际上,在妥善加以引导与吸引,少部分选民就会转变立场。尽管这部分选民的选票所占比例甚低,但当候选人的选票非常接近时,这些人的立场无疑会对选举结果产生非常大的影响。如何找出这类选民,以及如何在有限预算的情况下采取措施来吸引他们?结果是聚类(Cluster)。
2 、 相关概念
2.1 聚类(Cluster)
聚类是一种无间道学习,它将相似的对象归到同一个簇中,将不相似的对象归入不同的簇。而相似这一概念取决于所选择的相似度计算方法。
2.2 K-均值聚类算法
K-均值是发现给定数据集的k个簇的算法。簇的个数是用户给定的,每一个簇通过其质心(centroid),即簇中所有点的中心来描述。
K-均值算法的工作流程是: 首先,随机确定k初始点作为质心。然后将数据集中的每个点分配到一个簇中,即: 为每个点找距其最近的质心,并将其分配给该质心所对应的簇。最后,将每个簇的质心更新为簇中所有点的平均值。
2.3 簇
所有数据点集合,簇中所有对象都是相似的。
2.4 质心
簇中所有点的中心(计算所有点的均值)。

2.5 关于簇和质心的直观认识
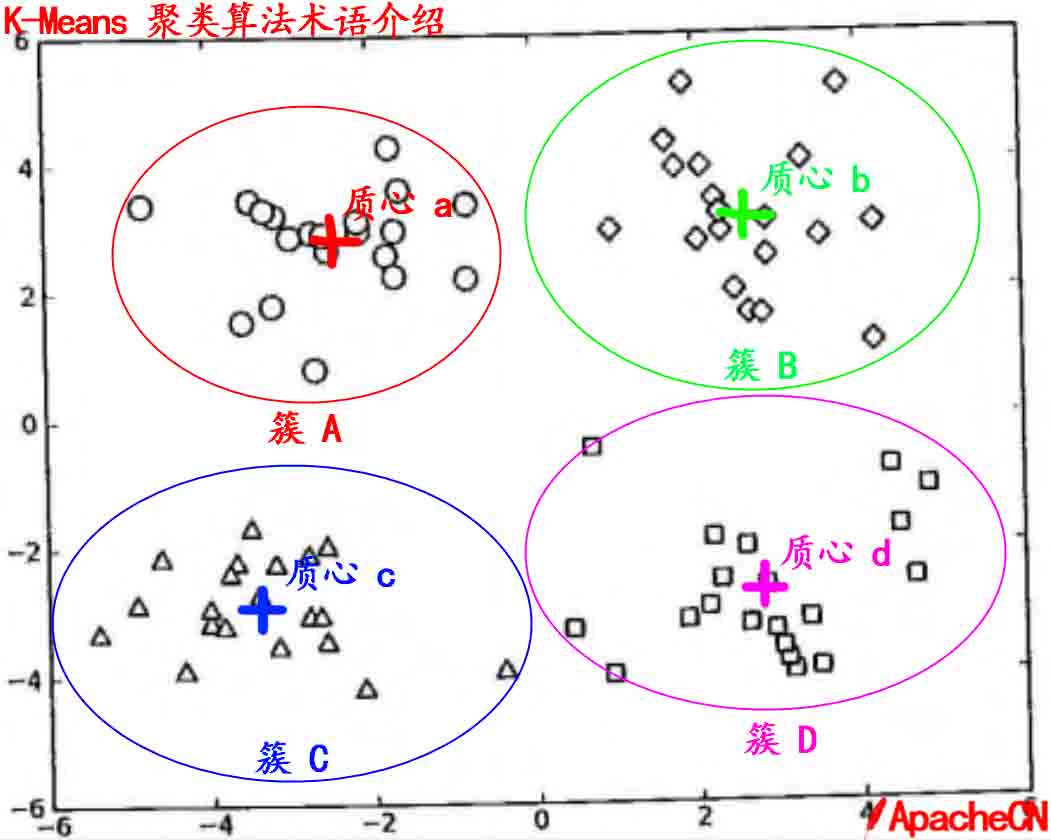
3、 聚类和分类的区别
最大区别在于: 分类的目标类别是已知,聚类的目标类别未知。
4、 K-均值聚类一般流程
(1) 收集数据: 使用任意方法
(2)准备数据: 需要数值型数据用来计算距离,也可以将数值型数据映射为二值型数据再来计算距离。
(3) 分析数据: 使用任何方法。
(4) 训练算法: 不适用于无监督学习,即无监督学习没有训练过程。
(5) 测试算法: 应用聚类算法、观察结果。可以使用量化误差指标(例如误差平方和)来评价算法效果。
(6) 使用算法: 可以用于所希望的任何应用。正常情况下,簇质心可以代表整个簇中的数据来做出决策。
5、 相关特性
优点: 容易实现
缺点: 可能收敛到局部最小值,在大规模数据集上收敛较慢。
适用数据类型: 数值型数据。
二、K-均值聚类分析案例一
1、项目简介
这里有一样本数据集,运用K-均值聚类算法给出聚类效果图示。
2、 样本数据样式
-3.156485 3.191137
3.165506 -3.999838
-2.786837 -3.099354
4.208187 2.984927
-2.123337 2.943366
0.704199 -0.479481
-0.39237 -3.963704
2.831667 1.574018
-0.790153 3.343144
2.943496 -3.357075
-3.195883 -2.283926
2.336445 2.875106
-1.786345 2.554248
2.190101 -1.90602
-3.403367 -2.778288
1.778124 3.8808323、K-均值聚类算法伪代码
创建k个点作为起始质心(一般是随机选择产生)
当任意一个点的簇分配结果发生改变时
对数据集中的每一个数据点
对每个质心
计算质心与数据点之间的距离
将数据点分配到距其最近的簇
对每一个簇,计算簇中所有点的均值并将该均值作为其质心
4、实现过程如下
4.1 质心随机初始化处理过程
4.1.1 操作代码
from numpy import *
import matplotlib.pylab as plt
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
#笔者使用的是python3,需要将map映射后的结果转化为list
fltLine = list(map(float , curLine))
dataMat.append(fltLine)
return dataMat
def distEclud(vecA , vecB):
return sqrt(sum(power(vecA - vecB , 2)))
def randCent(dataSet , k):
n = shape(dataSet)[1]
centroids = mat(zeros((k, n)))
for j in range(n):
minJ = min(dataSet[:,j])
rangeJ = float(max(dataSet[: , j]) - minJ)
centroids[: , j] = mat(minJ + rangeJ * random.rand(k , 1 ))
return centroids dataMat = mat(loadDataSet('testSet.txt'))#distMeans为计算距离函数
#createCent为初始化随机簇心函数
def kMeans(dataSet ,k , distMeans = distEclud , createCent = randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m, 2)))
centroids = createCent(dataSet ,k )
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = inf; minIndex = -1
for j in range(k):
distJI = distMeans(centroids[j, :] , dataSet[i , :])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,0] != minIndex :clusterChanged =True
clusterAssment[i ,: ] = minIndex, minDist**2
print(centroids)
for cent in range(k): #recalucate centroids
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]
centroids[cent, :] = mean(ptsInClust, axis = 0)
return centroids , clusterAssment myCentroids , clusterAssing = kMeans(dataMat , 4)4.1.2、 输出结果如下
[[-2.4072336 0.65055051]
[-3.87446815 4.55322739]
[-3.40256391 -2.67558429]
[-5.30746535 -1.24296148]]
[[ 1.54690239 1.68314582]
[-2.41083064 3.45476727]
[-1.19841963 -3.18106853]
[-4.599622 -2.185829 ]]
[[ 2.85333773 2.05148038]
[-2.46154315 2.78737555]
[ 1.0652737 -3.28518555]
[-3.89646064 -2.78844243]]
[[ 2.80642645 2.73635527]
[-2.46154315 2.78737555]
[ 2.44502437 -2.980011 ]
[-3.53973889 -2.89384326]]
[[ 2.6265299 3.10868015]
[-2.46154315 2.78737555]
[ 2.65077367 -2.79019029]
[-3.53973889 -2.89384326]]4.1.3、绘制聚类图形
执行如下代码
xArr = dataMat[: , 0].flatten().A[0]
yArr = dataMat[: , 1].flatten().A[0]
xArr01 = myCentroids[: , 0].flatten().A[0]
yArr01 = myCentroids[: , 1].flatten().A[0]
#绘制k均值聚类图形
def k_plot(xArr , yArr , xArr01 , yArr01):
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xArr , yArr , c = 'blue')
ax.scatter(xArr01 , yArr01 , c = 'red')
plt.show()
k_plot(xArr, yArr, xArr01, yArr01)
输出结果图示如下(图中红色点为每个簇的质心)
结果给出了4个质心,经过3次迭代之后K-均值算法收敛,这4个质心以及原始数据集的散点图如下。

4.2 二分K-均值聚类算法
4.2.1 实现过程
#二分k均值聚类分类方法
#distMeas为计算距离函数
def biKmeans(dataSet , k , distMeas = distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m, 2)))
centroid0 = mean(dataSet , axis = 0).tolist()[0]
centList = [centroid0]
for j in range(m):
clusterAssment[j, 1] = distMeas(mat(centroid0), dataSet[j , :])**2
while(len(centList) < k):
lowestSSE = inf
for i in range(len(centList)):
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:, 0 ].A==i)[0], :]
centroidMat , splitClustAss = kMeans(ptsInCurrCluster, 2 ,distMeas)
sseSplit = sum(splitClustAss[:, 1])#compare the SSE to the current minimum
sseNoSplit = sum(clusterAssment[nonzero(clusterAssment[: ,1].A !=i)[0],1])
print ("sseSplit and noSplit :" , sseSplit, sseNoSplit)
if(sseSplit + sseNoSplit ) < lowestSSE:
bestCentToSplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNoSplit
bestClustAss[nonzero(bestClustAss[:,0].A ==1)[0], 0] = len(centList)
bestClustAss[nonzero(bestClustAss[:,0].A ==0)[0], 0] = bestCentToSplit
print('the bestCentToSplit is ', bestCentToSplit)
print('the len of the bestCentToSplit is ', len(bestClustAss))
centList[bestCentToSplit] = bestNewCents[0 , :].tolist()[0]
centList.append(bestNewCents[1,:].tolist()[0])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0] ,:] = bestClustAss
return mat(centList) , clusterAssment dataMat03 = mat(loadDataSet('testSet2.txt'))
centList , myNewAssment = biKmeans(dataMat03, 3)
print (centList)
xArr03 = dataMat03[:, 0].flatten().A[0]
yArr03 = dataMat03[:, 1].flatten().A[0]
xArr0301 = centList[: , 0].flatten().A[0]
yArr0301 = centList[: , 1].flatten().A[0]
def k_plot03(xArr03, yArr03, xArr0301, yArr0301):
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xArr03, yArr03, c = 'blue')
ax.scatter(xArr0301, yArr0301, c = 'red')
plt.show()
k_plot03(xArr03, yArr03, xArr0301, yArr0301)4.2.2 输出结果及分析
[[-3.09420389 -0.44554111]
[-3.44816512 -0.0279717 ]]
[[ 1.21959613 0.06545838]
[-2.71560067 3.37937762]]
[[ 1.23710375 0.17480612]
[-2.94737575 3.3263781 ]]
sseSplit and noSplit : 570.722757425 936.619752085
the bestCentToSplit is 0
the len of the bestCentToSplit is 60
[[-0.99253233 -2.83980664]
[-1.33343486 -1.8112121 ]]
[[-0.15366667 -3.15354 ]
[ 2.071566 2.1718138 ]]
[[-0.45965615 -2.7782156 ]
[ 2.93386365 3.12782785]]
sseSplit and noSplit : 68.6865481262 570.722757425
[[-2.31955707 2.42664093]
[-3.06842022 2.15615703]]
[[-1.9062885 3.42271988]
[-3.64143392 3.26215025]]
[[-1.76576557 3.39794014]
[-3.58362738 3.28784469]]
sseSplit and noSplit : 22.9717718963 570.722757425
the bestCentToSplit is 1
the len of the bestCentToSplit is 20
[[ 1.23710375 0.17480612]
[-1.76576557 3.39794014]
[-3.58362738 3.28784469]]
由于质心随机初始化导致K-均值算法效果一般,这就需要额外的后处理操作来清理聚类结果。在保持簇总数不变的情况下,可以将某两个簇进行合并。从上图可知,很明显将图中下面两个出错的簇进行了合并。
三、K-均值聚类分析案例之二对地理坐标进行聚类
1、 项目概述
你的美国女友今天晚上要过生日,希望你能带她去俄勒冈州Potland等城里庆生。由于还有其他一些朋友也要过来,需要你尽快指定一个可行的计划。女友给了你一些她希望去的地址,这些地址列表较长,有69个位置。也就是说,今天晚上这69个位置(特别说明,笔者在查阅书籍、网络文章,看到的均是70个位置,实际是69个位置,因为,笔者使用同样的样本数据集,代码运行结果或人工查看样本数目均是69,这里特做出说明)都有可能是要去的地方。现在你考虑利用K-均值聚类分析来制定一个最佳策略,这样你就可以合理安排交通工具抵达这些簇的质心,然后步行抵达簇内的具体地址(事先簇内每个地址都可能是目标地)。所以,你首要工作是要将这些地址的经纬度给标出,然后,对这些地址进行聚类分析以供你合理安排交通决策使用。
2、 关于经纬度数据获取说明
笔者进行两种Yahoo API接口尝试,均是服务器无效地址,如下:
(1) 'http://where.yahooapis.com/geocode?'
(2) 'http://query.yahooapis.com/v1/public/yql?'
错误如下:
URLError: <urlopen error [Errno -2] Name or service not known>
所以,这里,笔者不再给出调用Yahoo API获取样本中69个位置的经纬度实现过程,就直接使用这69个地址经纬度已经全部标注好的样本数据集。
3、 样本数据集样式如下
Boom Boom Room 8345 Barbur Blvd Portland OR 45.464826 -122.699212
Bottoms Up 16900 Saint Helens Rd Portland OR 45.646831 -122.842918
Cabaret II 17544 Stark St Portland OR 45.519142 -122.48248
Cabaret Lounge 503 W Burnside Portland OR 45.523094 -122.675528
Carnaval 330 SW 3rd Avenue Portland OR 45.520682 -122.674206
Casa Diablo 2839 NW St. Helens Road Portland OR 45.543016 -122.720828
Chantilly Lace 6723 Killingsworth St Portland OR 45.562715 -122.593078
Club 205 9939 Stark St Portland OR 45.519052 -122.56151
Club Rouge 403 SW Stark Portland OR 45.520561 -122.675605
Dancin' Bare 8440 Interstate Ave Portland OR 45.584124 -122.682725
4、 实现过程如下
在本项目中,由于要聚类的Party地址给出的信息是经纬度,对于要要直接计算距离信息还是不够的。在北极圈附近走几米带来的经度变化可能达10多度,而在赤道附近走相同的距离所导致经度的变化可能只是零点几度而已。所以,要计算两个地址的经纬度间的距离,这里就使用了球面余弦定理。
#利用球面余弦定理计算指定(经度,纬度)两点的距离
def distSLC(vecA, vecB):#Spherical Law of Cosines
a = sin(vecA[0,1]*pi/180) * sin(vecB[0,1]*pi/180)
b = cos(vecA[0,1]*pi/180) * cos(vecB[0,1]*pi/180) * \
cos(pi * (vecB[0,0]-vecA[0,0]) /180)
return arccos(a + b)*6371.0 #pi is imported with numpy
import matplotlib
import matplotlib.pyplot as plt
def clusterClubs(numClust=5):
datList = []
for line in open('places.txt').readlines():
lineArr = line.split('\t')
datList.append([float(lineArr[4]), float(lineArr[3])])
datMat = mat(datList)
myCentroids, clustAssing = biKmeans(datMat, numClust, distMeas=distSLC)
fig = plt.figure()
rect=[0.1,0.1,0.8,0.8]
scatterMarkers=['s', 'o', '^', '8', 'p', \
'd', 'v', 'h', '>', '<']
axprops = dict(xticks=[], yticks=[])
ax0=fig.add_axes(rect, label='ax0', **axprops)
imgP = plt.imread('Portland.png')
ax0.imshow(imgP)
ax1=fig.add_axes(rect, label='ax1', frameon=False)
for i in range(numClust):
ptsInCurrCluster = datMat[nonzero(clustAssing[:,0].A==i)[0],:]
markerStyle = scatterMarkers[i % len(scatterMarkers)]
ax1.scatter(ptsInCurrCluster[:,0].flatten().A[0], ptsInCurrCluster[:,1].flatten().A[0], marker=markerStyle, s=90)
#画出所有簇中心
ax1.scatter(myCentroids[:,0].flatten().A[0], myCentroids[:,1].flatten().A[0], marker='+', s=300)
plt.show()
clusterClubs(3)
5、聚类分析结果展示
这里以划分为3个簇为例做展示,读者也可以修改簇数来查阅。
[[-122.6485432 45.49558985]
[-122.4137682 45.54312134]]
[[-122.64533773 45.51357016]
[-122.4568086 45.4961344 ]]
[[-122.66149437 45.51440946]
[-122.50322869 45.50324862]]
[[-122.67273274 45.51397274]
[-122.52363268 45.50792237]]
[[-122.68917857 45.50793286]
[-122.54222807 45.51911044]]
[[-122.69551477 45.50729503]
[-122.54868607 45.51882187]]
sseSplit and noSplit : 3043.26331589 5290.9111333
the bestCentToSplit is 0
the len of the bestCentToSplit is 69 #这里也证明笔者观点:是69个地址而不是70个地址,笔者认为相关书本、博客文章沿用70有误。
[[-122.691933 45.40485897]
[-122.62610906 45.56299102]]
[[-122.7288018 45.45886713]
[-122.67471037 45.53756246]]
sseSplit and noSplit : 1321.04463239 3043.26331589
[[-122.46565865 45.51020354]
[-122.57277754 45.53693724]]
[[-122.48186875 45.49677212]
[-122.57298327 45.52683995]]
[[-122.48812733 45.49597933]
[-122.57463981 45.52861152]]
[[-122.49860291 45.49496564]
[-122.57768158 45.53263337]]
sseSplit and noSplit : 464.720598318 3043.26331589
the bestCentToSplit is 1
the len of the bestCentToSplit is 30
四、 小结
聚类是一种无监督学习方法。所谓无监督学习是指事先并不知道要寻找的内容,即没有目标变量。聚类将数据点归到多个簇中,其中相似数据点处于同一簇中,而不相似的数据点处于不同的簇中。聚类中可以使用多种不同的方法来计算相似度。
K-均值算法是一种广泛使用的聚类算法,这里K是用户自定义的簇数。K-均值聚类算法以k个随机质心开始,接下来计算每个数据点到质心的距离。每个数据点会被分配到距其距离最近的簇质心,然后基于新分配到簇的点更新簇心。以上过程重复多次,直到质心不再改变。当然,为了得到更好的效果,可以使用二分K-均值聚类算法。二分K-均值算法首先将样本数据划分一个簇,然后使用K-均值算法(k=2)对其划分。下一次迭代时,选择最大误差的簇进行划分,该过程重复直到K个簇创建成功为止。
这是笔者开展无监督学习算法的第一篇文章,水平有限,请各位大拿多提些宝贵意见,多谢。