Hibernate关联映射---数据对象三种关系
Hibernate框架基于orm设计思想,它将关系型数据库中的表与我们的java中的类进行关联映射,一个对象对应着数据库表中的一条记录,而表中的字段对应着类中的数据.数据库中表与表之间存在着三种关系,也就是系统设计中的三种实体关系,分别为1对1,一对多,多对一。
1.1一对一
原则有两种:
- 唯一外键对应:在任意一方添加一个外键来描述对应关系
- 主键对应:一方的主键作为另一方的主键

Class Employee {
Private Archives archives;
}
Class Archives {
Private Employee employee;
}
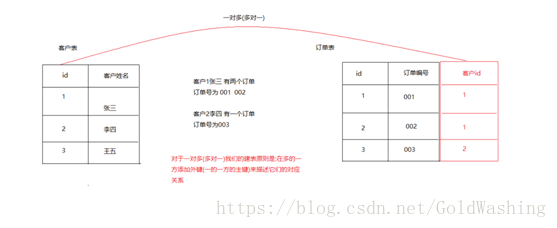
1.2一对多(多对一)
客户与订单之间一对多的关系(多对一)
建表原则:在多的一方添加外键来描述关联关系
Class Customer{
Private Set<Order> orders;
}
Class Order{
Private Customer customer;
}
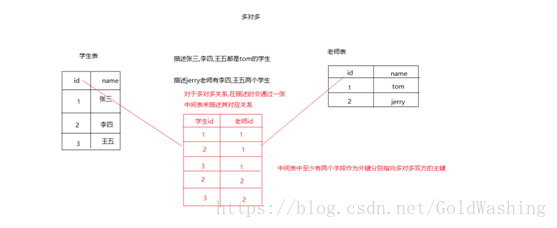
1.3多对多
例如学生与老师
建表原则:通过一张中间表来描述其对应关系
Class Student{
Set<Teacher> ts;
}
Class Teacher{
Set<Student> ss;
}
- hibernate关联映射---一对多(多对一)
我们以客户(Customer)与订单(Order)为例.
2.1实体类创建
客户

订单

2.2hbm映射文件编写
Order.hbm.xml

Customer.hbm.xml

2.3测试保存

上面的操作是一种双向关联
问题:我们可不可以只保存订单或者只保存客户完成所有对象保存操作?
2.4测试单项关联保存

org.hibernate.TransientObjectException: object references an unsaved transient instance-save the transient instance before flushing: com.whhp.one2many.Customer
..............
这个异常代表的是一个持久化对象在操作的时候关联了一个瞬时对象.
我们可以使用hibernate的级联操作来解决上述问题.
我们现在要做的是保存订单时保存客户,需要在订单的hbm配置文件中进行修改

设置cascade=save-update 那么在保存订单时就可以自动将客户保存
如果要完成保存客户,自动保存订单

2.5双向关联维护
我们在开发中要配置双向关联配置.-----------可以通过任意一方来操作对方.
在操作代码的时候,尽量要进行单项关联.---------可以尽量避免资源的浪费.
在双向关联中,会存在多余的update语句.
我们可以使用inverse属性来设置,双向关联时由哪一方来维护表与表之间的关系.

Inverse它的值如果为true代表,由对方来维护外键.
Inverse它的值如果为false代表,由本方来维护外键.
关于inverse的取值:
外键在哪一个表中(外键是哪一个表的其中一个字段),我们就让哪一方来维护外键.
2.6对象导航

2.7级联删除
我们在删除客户时,也要删除订单,如果没有做级联,那么这个操作是不允许的.
为了维护数据的完整性.

想要完成级联删除操作:我们可以在客户的映射配置文件中配置cascade=”delete”

delete-orphan用法


2.8cascade总结
使用cascade可以完成级联操作
它的常用取值:
- none 这是一个默认值
- save-update 当我们配置它时,底层使用save update或者save-update完成操作.级联保存(save)临时对象,如果是游离对象,会执行update.
- delete级联删除
- delete-orphan删除与当前对象解除关系的对象.
- all 它包含了save-update delete操作
- all-delete-orphan 它包含了delete-orphan与all操作
笔试题:cascade与inverse有什么区别?
cascade它是完成级联操作
inverse它是只有在双向关联的情况下使用,用它来制定由哪一方维护外键.
3hibernate注解开发
在hibernate中我们使用注解,可以帮助我们简化hbm文件的配置.
3.1PO类注解配置
@Entity 声明一个实体
@Table 来描述类与表的对应关系
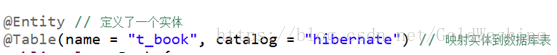
@Id 来声明一个主键
@GeneratedValu 用它来声明一个主键生成策略

默认情况下相当于native
可以选择的主键生成策略 AUTO IDENTITY SEQUENCE
@Column 来定义列
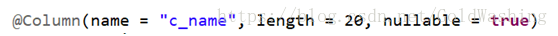
注意:对于PO类中的所有属性,如果你不写注解,默认情况下也会在表中生成对应的列,列的名称就是属性的名称.
@Temporal 来声明日期类型

取值可以选择
TemporalType.DATE 只有年月日
TemporalType.TIME 只有时分秒
TemporalType.TIMESTAMP 有年月日和时分秒
我们最终要在hibernate.cfg.xml文件中将我们类中的注解配置引用生效
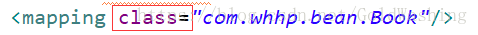
问题:如果我们主键生成策略想使用uuid类型怎么办?

问题:如何设定类中的属性不在表中映射?

对于我们以上讲解的关于属性配置的注解,我们也可以在其对应的getXXX方法上去使用,如果在属性上配置,那么所有的注解都需要配置在属性上,如果在getXXX方法上使用,那么所有的注解都需要配置在getXXX方法上.
3.2一对多(多对一)
@OneToMany
@ManyToOne
Customer类

Order类

示例:在保存客户时保存订单
对于这个示例,我们需要在customer中配置cascade操作,save-update
第一种方式,可以使用JPA提供的注解

第二种方式,可以使用hibernate提供的注解

示例代码

执行的结果

订单中没有关联客户的id,为什么?
原因:我们在customer中配置了mappedBy=”customer”,它代表的是外键的维护是有order方来维护,而customer不维护,这时你在保存客户是,级联保存订单是可以的,但是不能维护外键,所以我们必须在代码中添加订单与客户的关系.
扩展:关于hibernate注解@cascade中的delete-orphan过时

使用下面的方案来替换过时方案

4.hibernate关系映射多对多
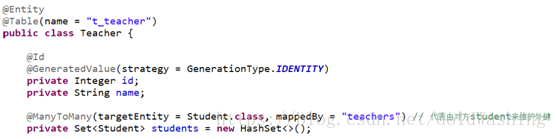
我们是用注解的方式完成多对多的配置,描述学生与老师的关系.
使用@ManyToMany来配置多对多,只需要在一端配置中间表,另一端使用mappedBy表示放弃外键维护权.
4.1创建PO类
Teacher类
Student类
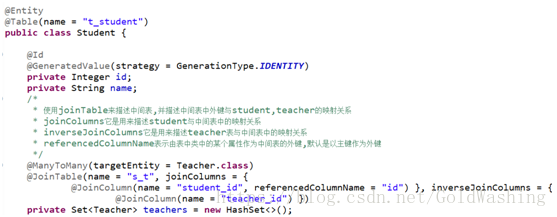
4.2级联保存测试
因为我们将外键的维护权利交由student来维护,我们在操作保存学生时,将老师也级联保存.

我们在student类中配置级联

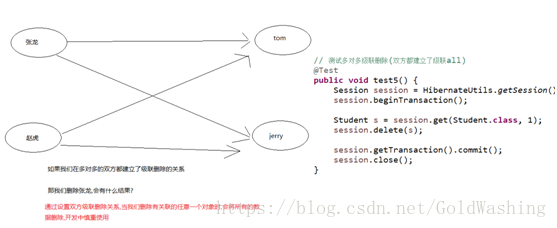
4.3级联删除操作
5.Hibernate关系映射一对一
以人与省份证号为例
一对一操作中有两种映射方式
- 在任意一方添加外键(外键映射)
- 主键映射
5.1外键映射
创建实体
User类

上述配置,t_user表放弃对外键维护的权利
IDCard类

joinColumn指定外键名称,当前配置外键是在t_idcard中,并且在IDcard中配置了级联关系,保存IDcard时级联保存user
级联保存测试代码

5.2主键映射(了解)
以husband与wife为例
Wife类

Wife的主键生成策略是identity
@PrimaryKeyJoinColumn 说明husband与wife是使用主键映射

Husband类
Husband的主键我们设置成参考wife的主键方式.
测试操作

6.Hibernate检索方式概述
对数据库操作中,最常用的是select,使用hibernate如何进行select操作.
分为五种:
- 导航对象图检索方式,根据已经加载的对象导航到其他对象.
- OID检索方式,按照对象的OID来检索对象.
- HQL检索方式,使用面向对象的HQL查询语言
- QBC检索方式,使用QBC(query by criteria)API来检索对象,这种API封装了基于字符串形式的查询语句,提供了更加面向对象的查询接口
- 本地SQL检索方式,使用本地数据库的SQL查询语句
6.1导航对象图检索方式
Customer c = session.get(Customer.class,2);
c.getOrders().size();
通过在hibernate中进行关系映射,在hibernate操作时,可以通过对象导航方式得到其关联的持久化对象信息.
6.2OID检索方式
Session.get(Customer.class,3);
Session.load(Order.class,2);
Hibernate中通过get/load方法查询指定的对象,要通过OID来查询
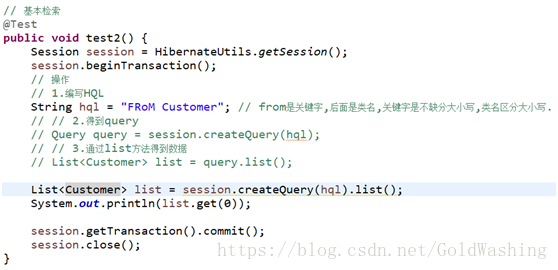
6.3HQL
HQL是我们在hibernate中常用的一种检索方式.
HQL是Hibernate Query Language的缩写,提供更加丰富灵活、更为强大的查询能力;HQL更接近SQL语句查询语法。
因此Hibernate将HQL查询方式立为官方推荐的标准查询方式,HQL查询在涵盖Criteria查询的所有功能的前提下,提供了类似标准SQL语句的查询方式,同时也提供了更加面向对象的封装。完整的HQL语句形式如下: Select/update/delete…… from …… where …… group by …… having …… order by …… asc/desc 其中的update/delete为Hibernate3中所新添加的功能,可见HQL查询非常类似于标准SQL查询。
基本步骤:
- 得到session
- 编写hql语句
- 通过session.createQuery(hql)得到一个query对象
- 为query对象设置条件参数
- 执行list()查询所有,它返回的是list集合,uniqueResult()返回一个查询结果.
准备数据

基本检索
From 类名;
排序检索

条件检索

分页检索

分组统计检索
分组 group by
统计 count sum max min avg

投影检索
我们主要讲解是关于部分属性的查询,可以使用投影将部分属性封装到对象中.
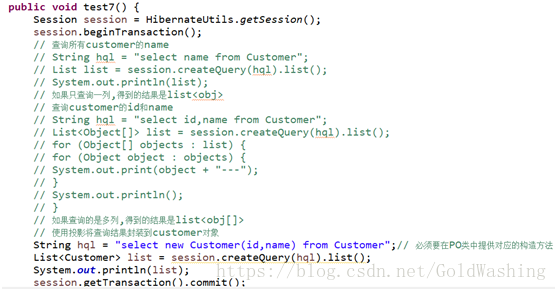
注意:我们必须在PO类中提供对应属性的构造方法,也要有无参构造.
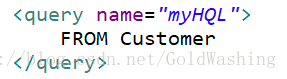
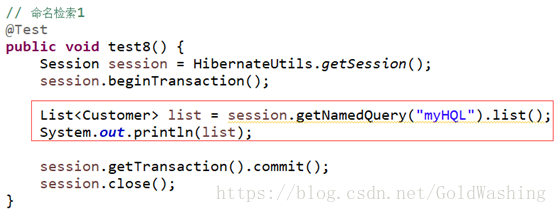
命名检索
我们可以将hql语句先定义出来,在使用的时候通过session.getNamedQuery(hqlName)得到一个query对象,然后再执行.
问题:hql定义在什么位置?
- 如果我们使用hbm配置文件,那么我们操作哪一个对象,就在哪一个对象的映射配置文件中进行配置申明
- 如果我们使用注解开发,我们直接在操作的对象上使用注解配置

问题:如何使用?


6.4QBC
QBC(query by criteria),它是一种更加面向对象的检索方式.
QBC操作步骤;
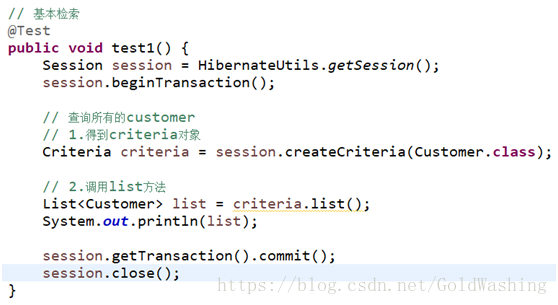
- 通过session得到一个criteria对象 session.createCriteria()
- 设定条件 Criterion实例,它的获取可以提供restrictions类提供的静态方法获取 criteria的add方法用于添加查询条件.
- 调用list方法进行查询 criteria.list();
基本检索
排序检索

注意:criteria.addOrder()方法的参数使用的Order是hibernate中的对象
条件检索

分页检索

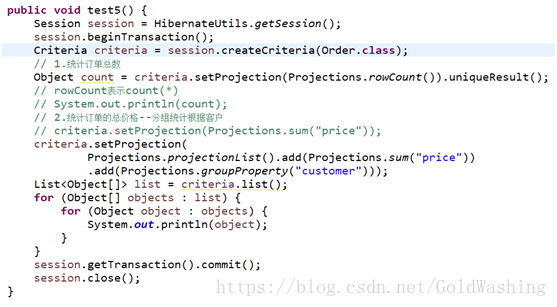
统计分组检索
Count sumavg max min
Group by
离线条件检索
它支持在运行时动态生成查询语句
6.5本地SQL
本地sql也支持命名查询
可以将sql语句定义hbm映射文件中,也可以使用注解
本地命名sql注解定义

执行这个命名sql,结果封装在obj[]数组中

因为hibernate不知道执行select * from t_customer后如何将结果封装
可以进行如下配置,将查询结果封装到customer对象中

6.6多表操作
SQL多表操作
1.交叉连接 CROSS JOIN 会产生笛卡尔积
SELECT * FROM t_customer CROSS JOIN t_order;
2.内连接 INNER JOIN ON
SELECT * FROM t_customer AS c INNER JOIN t_order AS o ON c.id = o.customer_id;
使用内连接它只能将有关联的数据查询得到.
隐式内连接 使用'逗号'将表分开,使用where来消除笛卡尔积
SELECT * FROM t_customer c,t_order o WHERE c.id = o.customer_id;
3.外连接 左外 LEFT OUTER JOIN 右外 RIGHT OUTER JOIN
OUTER是可以省略的
SELECT * FROM t_customer c LEFT JOIN t_order o ON c.id = o.customer_id;
HQL多表操作
hql多表操作分类:
- 交叉连接
- 内连接
- 显式内连接
- 隐式内连接
- 迫切内连接
- 外连接
- 左外链接
- 迫切左外链接
- 右外连接
注意:在hibernate中有迫切连接的概念,而sql中没有
内连接
显示内连接
显示内连接使用的是 inner join with

隐式内连接
隐式内连接也和我们在sql中的操作不一样,它是通过”.”运算符来关联

迫切内连接
迫切内连接得到的结果是直接封装到PO类中,而内连接是得到的obj[]数组,数组中封装的是PO类对象

外连接

波切左外连接

注意:只有迫切左外链接,fetch不可以与单独条件with一起使用
7.hibernate事务管理
7.1事物介绍
问题:什么是事物?
事物就是逻辑上的一组操作,组成这组操作的各个单元要么全部成功,要么全部失败.
问题:事物有什么特性?
原子性:不能分割
一致性:事物在执行前后,要保证数据一致性
隔离性:一个事物在执行的过程中,不应该受到其他事物的干扰.
持久性:事物一旦结束,数据会持久化到数据库.
问题:不考虑事物的隔离性,会产生什么问题?
脏读:一个事物读取到另一个事物未提交的数据.
不可重复读:一个事物读取到另一个事物提交的数据(主要是指update),会导致两次读取的结果不一致.
虚读(幻读):一个事物读取到另一个事物提交的数据(主要是指insert),会导致两次读取的结果不一致.
问题:对于上述问题如何解决?
我们可以通过设置事物的隔离级别来解决
READ_UNCOMMITED 读取未提交 它引发所有的隔离问题
READ_COMMITED 读已提交 阻止脏读,可能发生不可重复读与虚读
REPEATABLE_READ 重复读 阻止脏读,不可重复读,可能发生虚读
SERIALIZABLE 串行化 解决所有的隔离问题 不允许两个事物,同事操作一 个目标数据(效率比较低下)
Oracle默认的事物隔离级别 READ_COMMITED
Mysql默认的事物隔离级别 REPEATABLE_READ
7.2hibernate中设置事物隔离级别
Hibernate.connection.isolation
它的取值有 1 2 4 8
1代表的是事物隔离级别为READ_UNCOMMITED
2代表的事物隔离级别为READ_COMMITED
4代表的事物隔离级别为REPEATABLE_READ
8代表的事物隔离级别为SERIALIZABLE
在hibernate.cfg.xml文件中配置

7.3hibernate中的session管理
Hibernate提供了三种管理session的方式:
- session对象的生命周期与本地线程绑定(ThreadLocal)
- Session对象的生命周期与JTA事物绑定.(分布式事物管理)
- Hibernate委托程序来管理session的生命周期.
我们之前使用的是第三种,通过程序去获得一个session对象,使用它,最后session.close().

在实际开发中我们一般使用的是前两种:
主要介绍关于本地线程绑定session
步骤:
- 需要在hibernate.cfg.xml文件中配置

- 在获取session时,不要再使用openSession,而是使用getCurrentSession方法


关于getSession使用时的注意事:

上述代码执行后,会产生问题
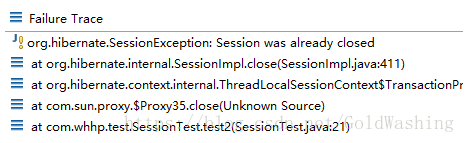
原因:使用getCurrentSession获取与线程绑定的session对象,在事物提交的时候,session对象也会close,简单说,就不需要我们再手动close
8.hibernate优化方案
8.1HQL优化
1.使用参数绑定
1.使用绑定参数的原因是让数据库一次解析SQL,对后续的重复请求可以使用用生成好的执行计划,这样做节省CPU时间和内存。
2.避免SQL注入
2.尽量少用NOT
如果where子句中包含not关键字,那么执行时该字段的索引失效。
3.尽量使用where来替换having
Having在检索出所有记录后才对结果集进行过滤,这个处理需要一定的开销,而where子句限制记录的数目,能减少这方面的开销
4.减少对表的查询
在含有子查询的HQL中,尽量减少对表的查询,降低开销
5.使用表的别名
当在HQL语句中连接多个表时,使用别名,提高程序阅读性,并把别名前缀与每个列上,这样一来,可以减少解析时间并减少列歧义引起的语法错误。
6.实体的更新与删除
在hibernate3以后支持hql的update与delete操作

8.2一级缓存优化
一级缓存也叫做session缓存,在一个hibernate session有效,这级缓存的可干预性不强,大多基于hibernate自动管理,但它提供清除缓存的方法,这在大批量增加(更新)操作是有效果的,例如,同时增加十万条记录,按常规进行,很可能会出现异常,这时可能需要手动清除一级缓存,session.evict以及session.clear.
9.检索策略(抓取策略)
9.1延迟加载
延迟加载 是hibernate为提高程序执行的效率而提供的一种机制,即只有真正使用该对象的数据时才会创建。
load方法采用的策略延迟加载.
get方法采用的策略立即加载。
检索策略分为两种:
- 类级别检索
- 关联级别检索
9.2类级别检索
类级别检索是通过session直接检索某一类对应的数据,例如
Customer c = session.load(Customer.class,1)
Session.createQuery(“from Order”)
类级别检索策略分为立即检索与延迟检索,默认是延迟检索,类级别的检索策略可以通过<class>元素的lazy属性来设置 ,默认值是true
在hbm文件中进行配置

在类中使用注解

如果将lazy设置为false,代表类级别检索也使用立即检索.这是load与get就 相同,都是一个立即检索.
如何对一个延迟代理对象进行初始化?

9.3关联级别检索
查询到某个对象,获得其关联的对象或属性,这种称为关联级别检索,例如
c.getOrders().size()
c.getName()
对于关联级别检索我们就要研究其检索策略(抓取策略)
9.4检索策略(抓取策略)
抓取策略介绍
指的是查找到某个对象后,通过这个对象去查询关联对象的信息时的一种策略.
一对一 <one-to-one>
一对多(多对一) <set>下有 <one-to-myany> <many-to-one>
多对多 <set>下有<many-to-one>
我们主要是在<set>与<many-to-one>或<one-to-one>上设置fetch lazy
例如:查询一个客户,要关联查询它的订单
客户是一的一方,在客户中有set集合来描述其订单,在配置中我们是使用
<set>
<one-to-many>
</set>
可以在set标签上设置两个属性 fetch lazy
Fetch主要描述的是SQL语句的格式(多条,子查询,多表联查)
Lazy控制SQL语句何时发送
例如:查询订单的时候,要查询客户的信息
<many-to-one>或者<one-to-one>也可以设置fetch lazy
Fetch主要描述的是SQL语句的格式(多条,子查询,多表联查)
Lazy控制SQL语句何时发送
总结:
讲解抓取策略
在两方面设置
<set fetch=”” lazy=””>
<many-to-one fetch=”” lazy=””> <one-to-one fetch=”” lazy=””>
注解配置抓取策略
问题:如何使用注解来设置
Set集合上设置fetch和lazy我们可以使用下面的注解进行描述

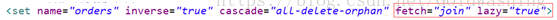
在<many-to-one>或者<one-to-one>上如何设置fetch与lazy


Set上的fetch与lazy
Set上的fetch与lazy它主要是用于设置关联的集合信息的抓取策略
Fetch的取值有:
- SELECT 多条简单的sql(默认值)
- JOIN 采用迫切左外链接
- SUBSELECT 将生成子查询sql
Lazy可取值有:
- TRUE 延迟检索(默认值)
- FALSE 立即检索
- EXTRA 加强版延迟检索(极其懒惰)

第一种组合

会首先查询客户信息,当需要订单信息时,才会关联查询订单信息
第二种组合

当查询客户信息时,就会立即将订单信息也查询,也就是说订单信息没有延迟加载
第三种组合

当查询客户信息时,不会查询订单信息,当需要订单的个数时,也不会查询订单信息,只会通过count来统计订单个数.
当我们使用size(),contains()或者isEmpty()方法时不会查询订单信息.
第四种组合
如果fetch使用的是join方案,那么lazy它会失效
生成的sql采用的是迫切左外链接(left outer join fetch)
会立即查询
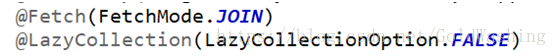
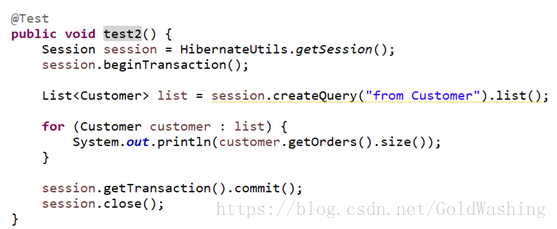
第五中组合

会生成子查询,但是在我们查询订单时采用的是延迟加载
第六种组合

会生成子查询,在查询客户时,就会立即将订单信息也查询出来
第七种组合

在查询订单时,只会根据情况来确定是否要订单信息,例如我们程序的size操作,那么就只会发送 select count(id) from t_order where customer_id =?
one的一方的fetch与lazy
<set fetch lazy>它主要是设置在获取到一的一方时,如何去查询多的一方
在<many-to-one>或者<one-to-one>如何去查询对方
对于程序,就是在多的一方如何查询一的一方的信息
例如:获取到一个订单对象,要查询客户信息.
Fetch可取值:
Select 默认值,代表发送一条或者多条简单的select语句
Join 发送一条迫切左外链接
Lazy可取值:
False 不采用延迟加载
Proxy 默认值, 是否采用延迟加载,需要依靠另一方的类级延迟策略决定
No-proxy 不用研究

第一种组合

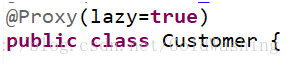
当我们执行时,会首先发送一条sql只查询订单信息,客户信息会延迟加载,只有真正需要客户信息时,才会sql来查询客户信息
第二种组合


注意:customer的类级别延迟策略
当查询订单时,就会将客户信息也查询到,原因是customer它的类级别延迟加载为false,也就是立即查询
第三种组合

当查询订单时,不会对客户信息进行延迟,立即查询客户信息
第四种组合

如果fetch为join,那么lazy失效
会发送一条迫切最外链接来查询,也就是立即查询
批量抓取
我们在查询多个对象的关联对象时,可以采用批量抓取的方式对程序进行优化.
要想实现批量抓取:
可以再配置文件中配置batch-size属性来设置
可以使用注解@BatchSize(size=4)
可以采用批量抓取来解决N + 1问题
查询客户,查询订单

可以在客户hbm配置文件中设置batch-size属性,是在<set>标签上
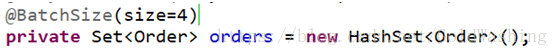
查询订单,查询客户

在订单与客户的查询中,客户它是一个主表,订单是一个从表
在设置批量抓取时,都是在主表中进行设置.
在配置文件中,需要在主表的<class>标签上设置batch-size
在注解中使用

注意:无论是根据哪一方来查询另一方,在进行批量抓取时,都是在复方来设置,
如果是要查询子信息,那么我们是在<set>上来设置batch-size,如果是从子方 查询父方,也是在复方<class>设置batch-size
父与子区分:
有外键的表是子(从),关联方就是父(主)表