这篇文章主要学习了python解析并读取PDF文件内容的方法,包括对学习库的应用,python2.7和python3.6中python解析PDF文件内容库的更新,包括对pdfminer库的详细解释和应用。主要参考了一些已有的博客内容,代码。
主要思路是首先利用一个做项目的形式,描述所做的问题,运行环境,和需要安装的库,然后写代码,此代码是在python2.7中运行,然后写出在python3.6中运行的代码,并详细解释python2.7和python3.6中python库的一些不同之处,最后详细的解释了代码的意思,和库的思路,最终的目的就让我们理解,并学会应用python解析并读取PDF文件内容的方法。
一,问题描述
利用python读取PDF文本内容
二,运行环境
python 3.6
三, 需要安装的库
| 1 |
|
四,实现源代码(其中代码1和代码2都是python2.7实现的)
代码1(win64)
| 1 2 3
扫描二维码关注公众号,回复:
2632852 查看本文章

4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
|
代码2(win32)
五,python3.6中如何改进python2.7实现的代码
问题一,reload的改进
| 1 2 3 |
|
以上是python2的写法,但是在python3中这个需要已经不存在了,这么做也不会什么实际意义。
在Python2.x中由于str和byte之间没有明显区别,经常要依赖于defaultencoding来做转换。
在python3中有了明确的str和byte类型区别,从一种类型转换成另一种类型要显式指定encoding。
但是仍然可以使用这个方法代替
| 1 2 |
|
问题二,pdfminer模块的安装
在python2.7中可以直接安装
| 1 |
|
在python3.6中就需要安装
| 1 |
|
六 python3.6的源代码
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
|
七 python读取PDF文档代码分析
PDF格式不是规范格式. 尽管它被叫做"PDF文档", 但并不像word或者html文档。PDF的表现更像一张图片。PDF更像是在一张纸的各个准确的位置上把内容都摆放出来。大部分情况下,没有逻辑结构,比如句子或段落,并且不能自适应页面大小的调整。PDFMiner尝试通过猜测它们的布局来重建它们的结构,但是不保证一定能工作。我知道这样很难看,但是,PDF确实不够规范。
下面这个图片是使用流程说明,我们将其分解来看
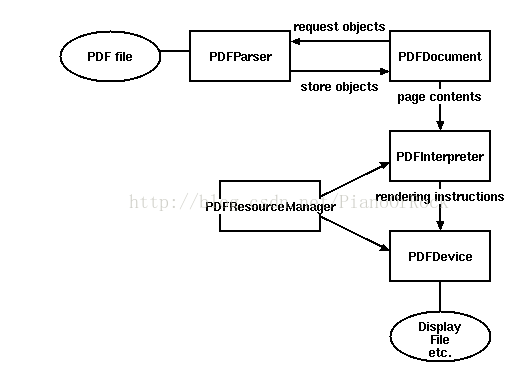
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
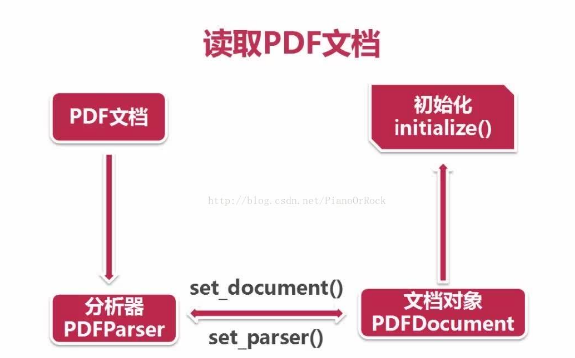
首先使用 open 方法或者 urlopen 打开本场文档或者网络文档(一般会这么做因为考虑到文档太大,对网络服务器负担也很大)生成文档对象,以下的方法之中的网络链接已经存在了。
| 1 2 3 |
|
然后创建 文档解析器 和 PDF文档对象 并将他们相互关联
| 1 2 3 4 5 6 7 8 9 |
|
对 PDF文档对象 进行初始化,如果文档本身进行了加密,则需要在加入 password 参数
| 1 2 |
|
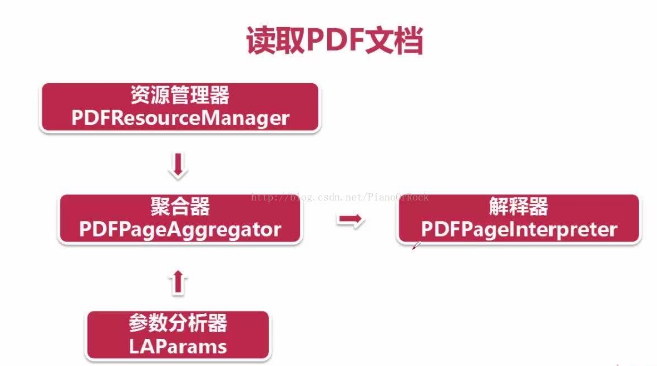
先创建 PDF资源管理器 和 参数分析器
| 1 2 3 4 5 |
|
再创建一个 聚合器 ,并接收 PDF资源管理器 参数分析器 作为参数
| 1 2 |
|
最后创建一个 页面解释器 ,将 PDF资源管理器 和 聚合器 作为参数
| 1 2 |
|
这样 页面解释器 就具有对PDF文档进行编码,解释成Python能够识别的格式
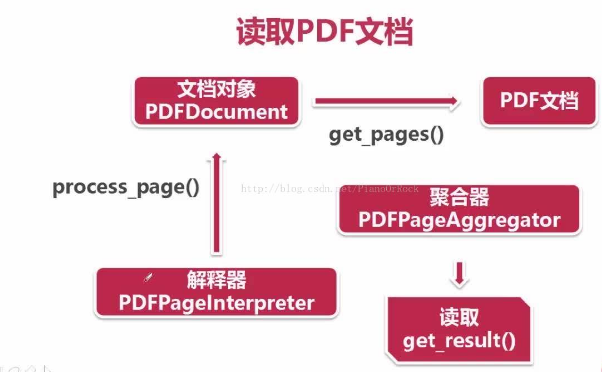
最后呢,使用 PDF文档对象 的 get_pages()方法 从PDF文档中读取出页面集合,接着使用 页面解释器 对页面集合逐一读取,再调用 聚合器 的 get_result()方法 将页面逐一放置到 layout 之中,最后商用 layout 的 get_text()方法 获取每一页的 text。
| 1 2 3 4 5 6 7 8 9 |
|
需要注意的是在PDF文档中不只有 text 还可能有图片等等,为了确保不出错先判断对象是否具有 get_text()方法
八,结果分析
如果PDF文件中仅仅是文字,那么会完全解析出来,读出文字,存在一个TXT文档里面,但是要是出现了图片等东西,则不会读取到东西。
本文做了三个实验,分别是PDF文档里面只存在文字,只存在图片,存在文字和图片。
结果显示:
| 只存在文字的PDF | 此程序会全部读取出文字 |
| 只存在图片的PDF | 此程序不会读取出任何东西 |
| 存在图片和文字 | 此程序只会读出文字,不会识别图片 |
所以说,图片的文字识别,不能只单纯的使用pdfminer这个库,还需要图片处理等相关技术。
不经一番彻骨寒 怎得梅花扑鼻香