Replication
MySQL能够将一个 MySQL Server的 Instance 中的数据完整的复制到另外一个 MySQL Server 的 Instance 中。虽然复制过程并不是实时而是异步进行的,但是延时非常之少。
MySQL 的Replication 功能在实际应用场景中被非常广泛的用于保证系统数据的安全性和系统可扩展设计中。
Replication 文件
master.info 文件
Slave 端的数据目录下,里面存放了该 Slave 的 Master 端的相关信息,包括 Master 的主机地址,连接用户,连接密码,连接端口,当前日志位置,已经读取到的日志位置等信息。
relay log 和 relay log index
mysql-relay-bin.xxxxxn 文件用于存放 Slave 端的 I/O 线程从 Master 端所读取到的 Binary Log 信息,然后由 Slave 端的 SQL 线程从该 relay log 中读取并解析相应的日志信息,转化成 Master 所执行的 SQL 语句,然后在 Slave 端应用。
mysql-relay-bin.index 文件的功能类似于 mysql-bin.index ,同样是记录日志的存放位置的绝对路径,只不过他所记录的不是 Binary Log,而是 Relay Log
relay-log.info 文件:
类似于 master.info,它存放通过 Slave 的 I/O 线程写入到本地的 relay log 的相关信息。供 Slave 端的 SQL 线程以及某些管理操作随时能够获取当前复制的相关信息。
my.cnf
系统配置文件,Unix/Linux 下默认存放在”/etc”目录下,Windows 环境一般存放在“c:/windows” 目录下面。
my.cnf文件中包含多种参数选项组(group ),每一种参数组都通过中括号给定了固定的组名,如 “[mysqld] ” 组中包括了 mysqld
服务启动时候的初始化参数,“[client]”组中包含着客户端工具程序可以读取的参数,此外还有其他针对于各个客户端软件的特定参数组,如 mysql
pid file
pid file 是 mysqld 应用程序在 Unix/Linux 环境下的一个进程文件,和许多其他Unix/Linux 服务端程序一样,存放着自己的进程 id。
socket file
socket 文件也是在 Unix/Linux 环境下才有的,用户在 Unix/Linux 环境下客户端连接可以不通过 TCP/IP 网络而直接使用 Unix Socket 来连接MySQL
Replication 过程
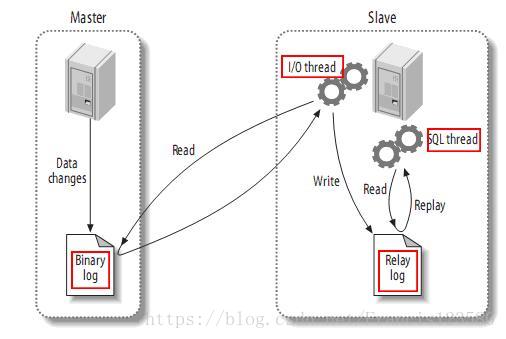
打开 Master 端的 Binary Log(mysql-bin.xxxxxx)功能;
Slave 上面的 IO 线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
Master 接收到来自 Slave 的 IO 线程的请求后,通过负责复制的 IO 线程根据请
求信息读取指定日志指定位置之后的日志信息,返回给 Slave 端的 IO 线程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息在 Master 端的 Binary Log文件的名称以及在 Binary Log 中的位置;Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的Relay Log 文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的 Master 端的 bin-log 的文件名和位置记录到 master-info 文件中,以便在下一次读取的时候能够清楚的高速 Master“我需要从某个 bin-log 的哪个位置开始往后的日志内容,请发给我”
Slave 的 SQL 线程检测到 Relay Log 中新增加了内容后,会马上解析该 Log 文件中的内容成为在 Master 端真实执行时候的那些可执行的 Query 语句,并在自身执行这些 Query。这样,实际上就是在 Master 端和 Slave 端执行了同样的 Query,所以两端的数据是完全一样的。
Replication 实现级别
Row Level - 记录级别
Binary Log 中会记录成每一行数据被修改的形式,然后在 Slave 端再对相同的数据进行修改
优点:不记录上下文信息,仅记录被修改记录
缺点:会产生大量的日志内容
Statement Level - 语句级别
每一条会修改数据的 Query 都会记录到 Master 的 BinaryLog 中。Slave 在复制的时候 SQL 线程会解析成和原来 Master 端执行过的相同的 Query来再次执行
优点:减少BinaryLog日志量,节约IO成本,提高性能
缺点:需要记录语句上下文信息
Replication 常用架构
基本原则
- 每个slave只能有一个master;
- 每个slave只能有一个唯一的服务器ID;
- 每个master可以有很多slave;
- 如果设置log_slave_updates,slave可以是其它slave的master,从而扩散master的更新。
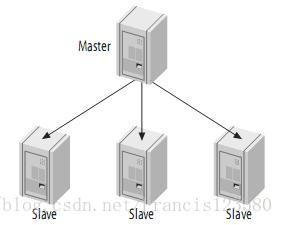
主从复制 - (Master-Slaves)
在实际应用场景中,MySQL 复制 90% 以上都是一个 Master 复制到一个或者多个Slave 的架构模式,主要用于读压力比较大的应用的数据库端廉价扩展解决方案。
通过廉价的 pc server 来扩展 Slave 的数量,将读压力分散到多台 Slave 的机器上面,即可通过分散单台数据库服务器的读压力来解决数据库端的读性能瓶颈。
多个Slave和单个Slave的实施并没有实质性的区别,Master端并不关心有多少个Slave连上自己,只要有Slave的IO线程通过了连接认证,向他请求指定位置之后的 Binary Log 信息,他就会按照该 IO线程的要求,读取自己的 Binary Log 信息,返回给 Slave 的 IO 线程。
建议:
- 不同的slave扮演不同的作用(例如使用不同的索引,或者不同的存储引擎);
- 多个slave用于读,分散读的压力;
- 用一个slave作为备用master,只进行复制;
- 用一个slave作为后台访问、脚本任务、数据分析,供开发人员使用;
- 用一个远程的slave,用于灾难恢复;
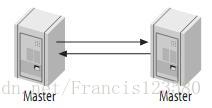
主主复制 - (Master-Master)
两个MySQL Server互相将对方作为自己的Master,自己作为对方的Slave来进行复制,这样,任何一方的变更,都会复制到另一方的数据库中。
主主复制有主动模式和被动模式两种
主动模式下两台服务器一样,被动模式下其中一台为只读服务器
优点:
- 停机无需重新搭建Replication架构;
- 系统重启后可以自动复制,节省维护成本;
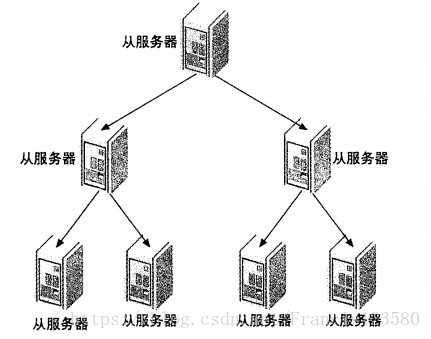
级联复制 - (Master-Slaves-Slaves)
通过少数几台 MySQL 从 Master 来进行复制,这几台机器我们姑且称之为第一级Slave 集群,然后其他的 Slave 再从第一级 Slave 集群来进行复制。从第一级 Slave 进行复制的 Slave,我称之为第二级 Slave 集群。
说明
- 缓解了更大的读写压力;
- 多级复制可能导致底层slave延时;
- 可以通过拆分成多个Replication集群来代替这种架构;
主主+级联复制 - (Master-Master-Slaves)
和 Master - Slaves - Slaves 架构相比,区别仅仅只是将第一级 Slave 集群换成了一台单独的 Master,作为备用 Master,然后再从这个备用的 Master 进行复制到一个Slave 集群。
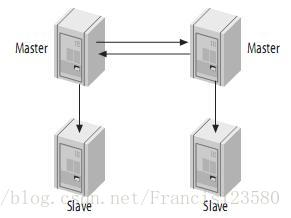
说明:
- 避免主Master的写入操作不会受到Slave集群的复制所带来的影响;
- 主Master需要切换的时候也基本上不会出现重搭Replication的情况;
- 备用Master可能会因为过多的SlaveIO线程请求而成为瓶颈;
- 如果备用Master级联复制的级别越多,Slave集群可能会出现数据延时;
小结
通过 MySQL 的 Replication 功能,我们可以非常方便的将一个数据库中的数据复制到很多台 MySQL 主机上面,组成一个 MySQL 集群,然后通过这个 MySQL 集群来对外提供服务。
这样,每台 MySQL 主机所需要承担的负载就会大大降低,整个 MySQL 集群的处理能力也很容易得到提升。