前段时间在了解Android代码混淆和反编译原理的时候,都涉及到了dex文件,该文件中保存着app中重要的数据信息,例如源码中使用的系统api,或者是否含有广告,更甚者通过解析AndroidManifest.xml知晓activity、service、receiver等四大组件数据信息(未混淆的情况下),而且一个程序应用的所有数据信息都存储在一个dex文件中,可见该格式文件存储信息的强大优势!
说起信息存储,Android系统其实是基于Java语言上开发(此处暂且不谈kotlin),而Java源码编译后生成的是class字节码文件,该文件也是存储了Java源码的相关信息,不过一个class文件只能存储一个类相关数据信息。Android系统为何不采用使用class文件而使用dex文件呢?这两种格式文件的结构又是如何?优劣?
带着以上的疑问,此文章以一个简单Java源码生成的class、dex文件进行分析、对比。本篇博文涉及到的知识点如下:
- class文件的生成、执行、结构的深入解析
- dex文件的生成、执行、结构的深入解析
- class与dex文件对比
一. Class文件详解
1. Class基本理论
(1)class文件定义
就是一种文件格式,是一种能够被JVM识别、加载并执行的文件格式,类似于生活中常见的.mp4格式,只不过class文件里存储的是应用程序。
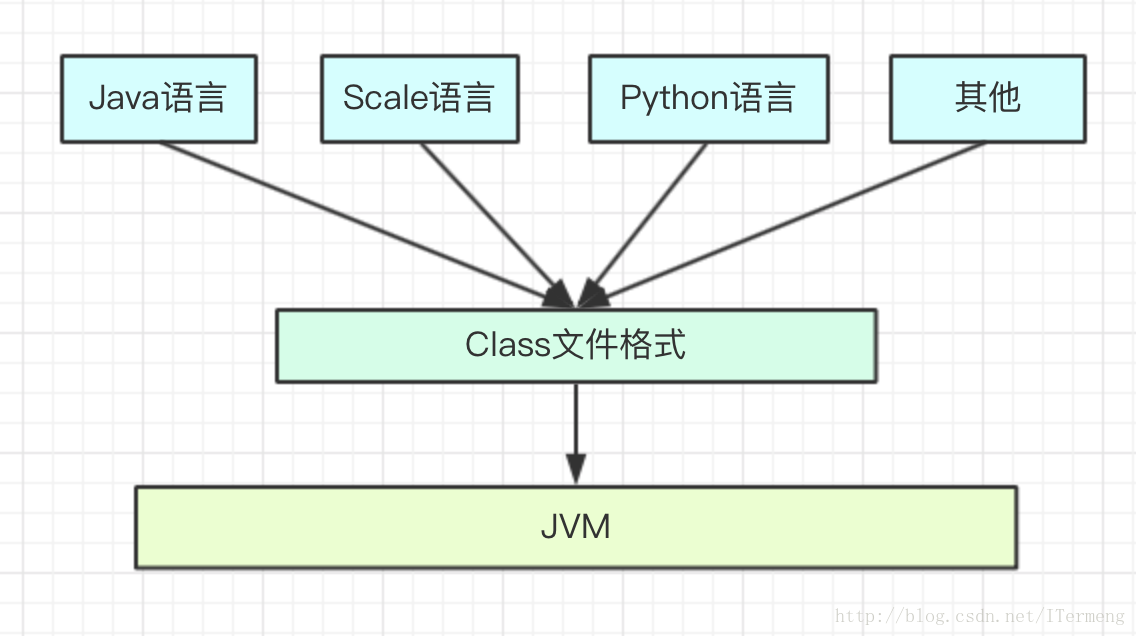
想必部分从事Java的开发者最初见识到class文件是来源于Java,但是只有Java代码可以生成class文件么?并非如此,见下图可知除去Java语言外,Scale、Python语言等皆可生产class文件,被JVM识别执行:
(2)如何生成class文件?
- 通过IDE自动build生成;
- 手动通过javac编译命令(即java compile)去生成class文件;(IDE内部也是通过此命令生产class文件)
(3)如何执行class文件?
- 通过IDE提供的可视化工具执行;
- 通过java命令去执行;
(4)使用命令生成并执行class文件的示例
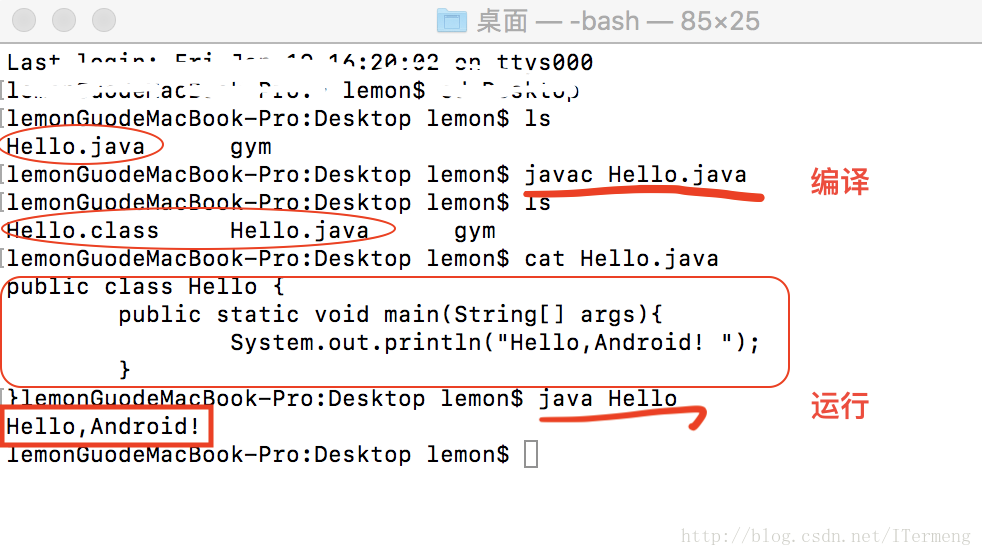
如上图,Java的初学者应该都体会过,使用终端命令而非IDE来编译运行程序。上图中使用javac name.java 编译程序后,除了原先的.java后缀文件,还产生了.class文件,再使用java name 命令即可运行程序,显示程序中的代码输出结果。以上,只是是生成执行class文件的简单示范。
(5)class文件的作用
class文件记录一个类文件的所有信息,包括类中所有的方法、变量名称等等,而且class文件所包含的信息远多于Java源码中可看到的信息。
简单思考一个问题,Java源码中没有定义this、super关键字,为何可以直接使用它们来调用当前类变量和父类方法?因为在生成字节码文件时,JVM已经记录这些关键字。从此问题可以看出class文件中记录的信息要多于Java源码中。
2. Class文件结构解析
(1)class文件特点
首先从整体来分析Class文件有哪些特点:
- class文件是一种8位字节的二进制流文件;(与大部分文件相同,例如音视频文件)
- 各个数据按顺序紧密排列,无间隙,减少文件体积,加载时更加迅速;(有的文件为了便于方便读取,使其固定字节位一行进行排列,会做一些填充)
- 每个类或借口都单独占据一个class文件,有便于类或借口可独自管理各自的内容,无须交叉;
(2)class文件内部结构及具体字段作用
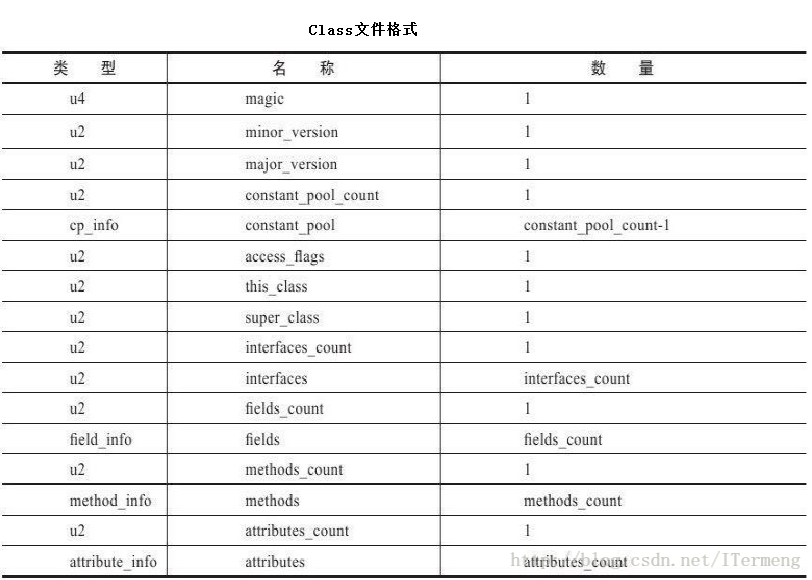
- magic:无符号4字节类型,是一个加密段,类似md5,用来判断class文件是否被篡改过;
- minor_version: class文件可被加载的最小适配JDK版本;
- major_version:该class文件生成时的JDK版本;
- constant_pool_count: 记录class文件中常量池的数量;
- constant_pool:常量池,总体数量为
constant_pool_count-1注意它的类型是cp_info,即结构体类型,其内部还包含其他类型,是class文件中的重点部分;(后续详解) - access_flags: class文件的作用域标志,例如public、public final类型等;
- this_class: 文章前面曾提出过问题,为何Java源码中未定义this关键字,却可以直接使用,就是因为JVM在生成class文件时,补充了此字段;
- super_class: 与上同理,JVM会默认填充此类的父类;
- interfaces_count: 记录当前类继承接口的数量,注意只统计当前类显示继承的接口,例如其父类继承的接口数不作统计;
- interfaces: 接口,数量为
interfaces_count; - fields_count: 记录类中所有变量数量;
- fields: 变量,数量为
interfaces_count,注意它的类型是field_info,即结构体类型,记录了每个变量名称、所在类、类型等; - methods_count: 记录类中所有方法数量;
- methods:变量,数量为
methods_count,注意它的类型是method_info,即结构体类型,记录了每个方法的名称、所在类、类型等; - attribute_count:记录类的相关属性数量,以上不曾包含的信息会放置此类型中,例如类上面的注解;
- attributes:属性,属性为
attribute_count,注意它的类型是attribute_info,即结构体类型;
以上是对Class文件中包含的所有字段解释,需要注意的是其中有的字段类型是结构体,代表着其又包含其他多种字段,层层嵌套,就像json数据一样。通过这些字段的详细定义规范,Java虚拟机可以轻易找到class文件中任意内容。
(3)重点字段详解
(笔者的JVM相关博文有详细分析class文件结构,在此篇文章中就不赘述,只挑取重点部分,读者可移驾阅读,链接如下:
VM高级特性与实践(五):实例探究Class类文件 及 常量池
JVM高级特性与实践(六):Class类文件的结构(访问标志,索引、字段表、方法表、属性表集合)
简单解释完class文件中字段含义后,下面挑出几个重点字段详细解释:
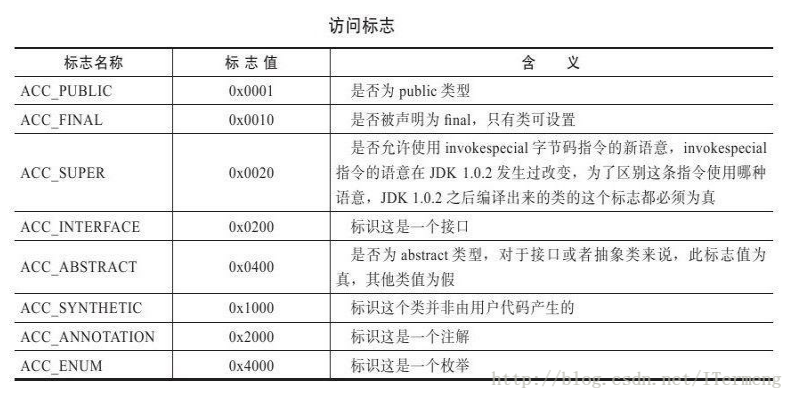
access_flags
access_flags访问标志主要用于识别一些类或者接口层次的访问信息,主要包括:
- 是否定义为public类型;
- 是否定义abstract类型;
- 这个Class是类还是接口;
- 如果是类的话是否被声明为final;
如下所示,访问标志中一共有16个标志位可以使用,当前只制定了8个。
constant_pool
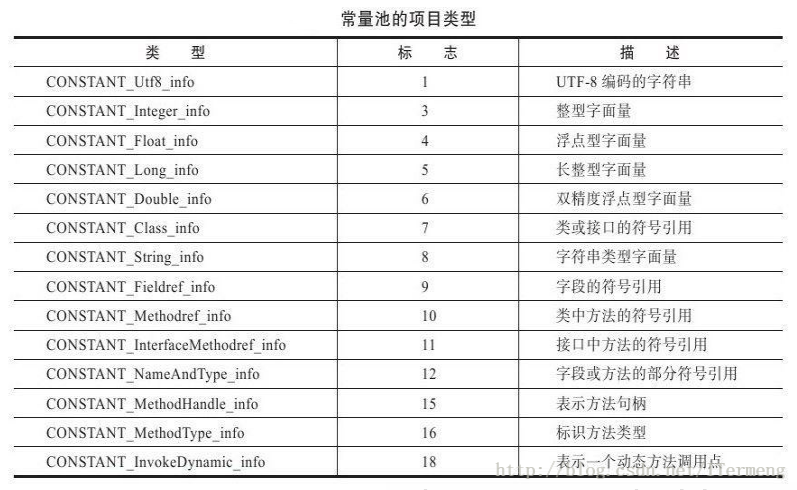
以上是线程池中的几种不同类型,需要注意的是这些类型可以大致分成两种:有的类型单纯存储值,而有的类型中存储的只是索引!例如CONSTANT_Integer_info 、CONSTANT_Long_info、CONSTANT_String_info分别存储class文件中的Integer、Long、String类型值,而CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info 这三个字段比较复杂,分别记录了类、类中变量、类中方法相关信息,它们存储的并不是真正内容,而是一些索引,最终指向的还是像CONSTANT_Integer_info这种单纯存储数据的值!因此,class文件的所有内容其实就是存储在常量池中CONSTANT_Integer_info等类型中的值。
(4)示例展示class文件中的字段
文章上面已经使用命令编译出Hello.java的 class文件,在学习过class文件几大类型的含义和作用后,这里使用010编辑器来验证。打开Hello字节码文件后,点击折起的“struct ClassFile classFile”部分,查看class文件中的详细信息:
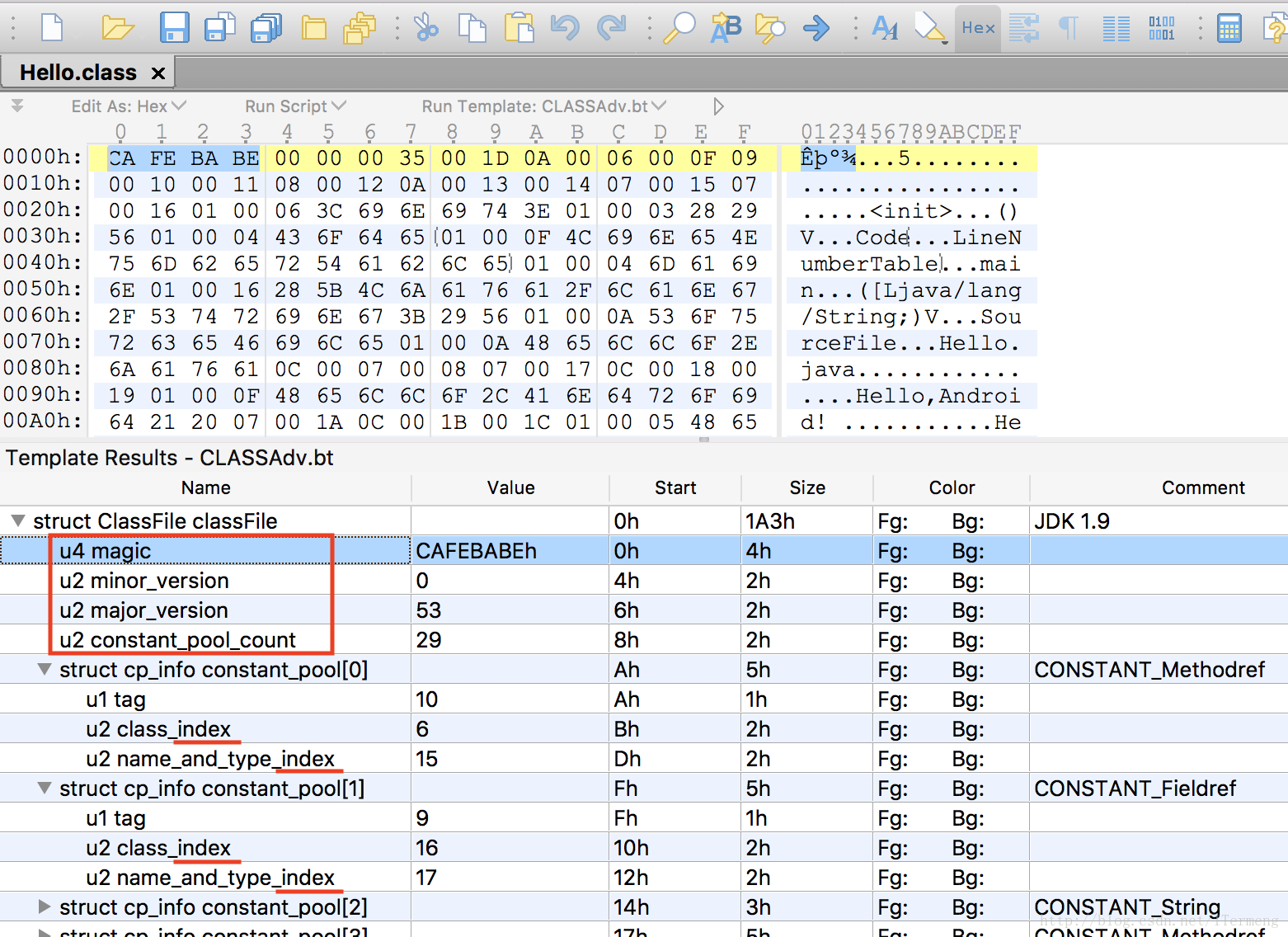
详情信息如上图,Name栏指的是字段,Value栏指的是值,Start栏指的是该值在class文件的起始位置,Size栏则是代表字段占据的位置大小,最后的Comment则备注字段含义,作以下分析:
- 首先第一个字段是 magic,起始位置从第0列h行开始,占据4个字节,值就是CAFEBABEh,其作用是加密段,因此值并无转化;
- 而后的字段 minor_version、major_version、constant_pool_count皆为2字节,在class文件中以16进制记录,在Value栏中被转化为10进制显示。
- 按照字段顺序,接下来就是常量池,根据constant_pool_count字段记录值为29,因此接下来就是数量为28的常量池值。(总数量是constant_pool_count-1,数组下标又是从0开始,因此数组max为27)数组中第一个值是CONSTANT_Methodref,是常量池中的一个类型,之前已经介绍过常量池的类型为结构体,因此将此值展开后,可看到其中又有tag、所属类class_index、方法名称和类型name_and_type_index这三个字段,需要注意的是后两者后缀带了一个_index,即这两个字段代表的不是一个真实值,而是一个索引、指针,其指向位置就是之前提过的CONSTANT_Integer_info这种单纯存储数据的值,这才是常量池真正存储数据的地方!数组中之后的数据原理也是如此,有的类型存储的是值,有的类型中存储的是指向基本类型的索引。
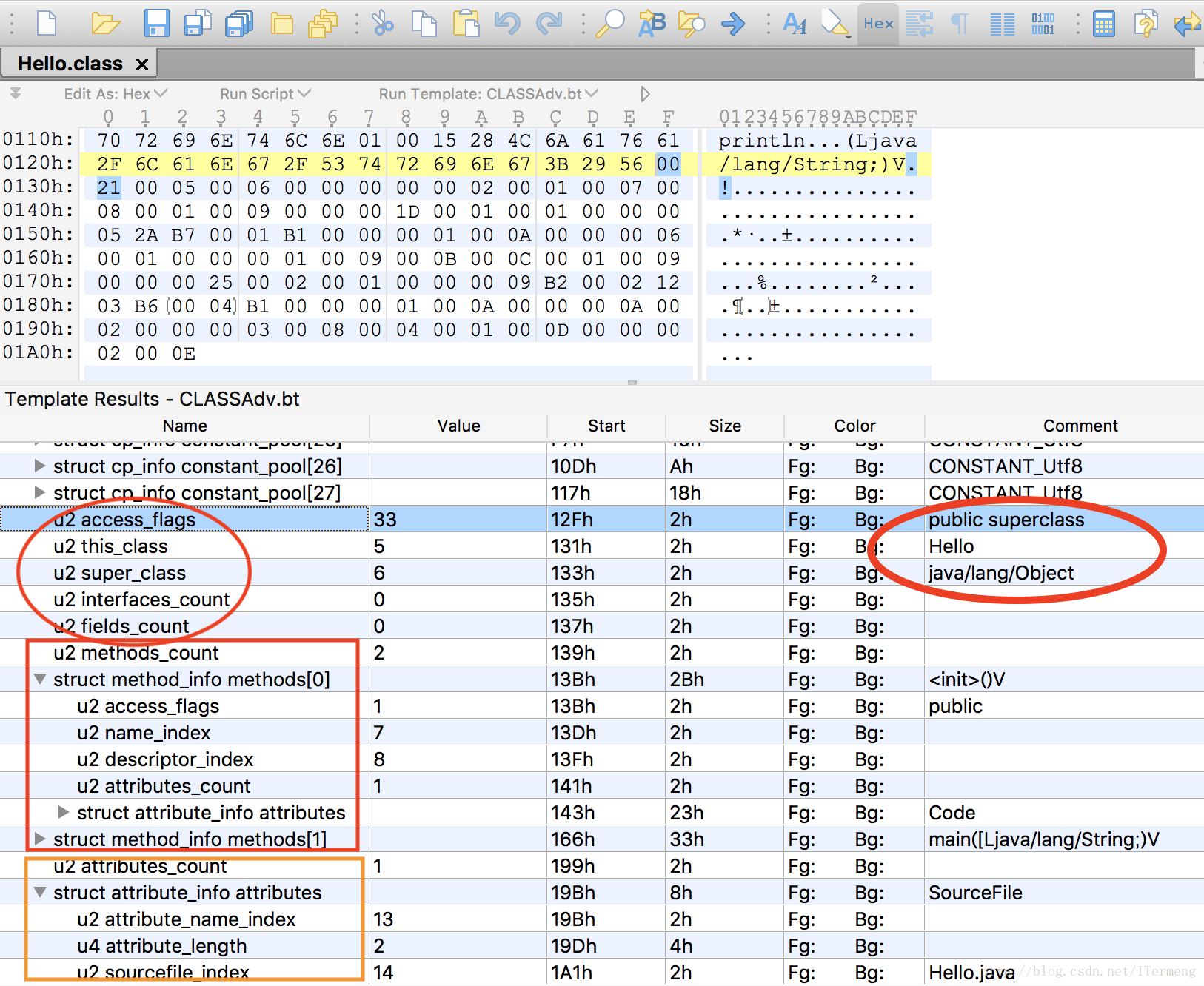
- 接下来就是access_flags访问标志,表明class文件的作用域,是public;
- 再者是之前一直强调的this和super关键字,class文件中默认补全了相关信息,this即Hello这个类,而super父类是Object,与之前推论符合。
- 而后就是实现的接口总数 interfaces_count,这里为0;
- 成员变量总数fields_count为0,因此无fields数组;
- 方法数 methods_count为2,接下来是method数组,类型也为结构体,因此每一个数组中的数据又存储多个信息;
- 最后就是属性总数及属性数组,原理同上;
以上就是实例探究字节码文件中存储数据,也验证了class文件数据都存储在不同的字段中,每个字段都有其规范与作用,通过工具010 Editor可轻松查看到。
3. Class文件弊端
以上介绍了class文件中的数据规范分明,但它对于移动设备而言还是有以下弊端:
- 如上讲解的,class文件中包含各种数据如常量池、field等,而一个应用中有成百乃至更多的类,使用字节码文件存储类信息,内存占用过大,不适合移动端;
- class文件是堆栈的加栈模式,加载速度慢;
- 文件IO操作多,类查找慢;因为每个class文件中只存储了一个Java源文件信息。
以上只是3个比较明显的弊端,还有一些小的缺陷,因此针对移动端开发的特点而言,字节码class文件并不是存储数据的最佳选择,
接下来将介绍dex文件 ,它的特性摒除了class文件存在的缺陷,并做了相关优化,是目前移动端存储数据的最优解。
二. Dex文件详解
1. Dex基本理论
(1)dex文件定义
dex文件是一种能被DVM识别、加载并执行的文件格式。
在之前介绍class文件时已经说明,并非只有Java源码可以生成class文件,而对于dex文件而言同是,除了Java外,C和C++皆可生成dex文件,因此它们也可编写Android应用程序。
(2)如何生成一个dex文件
- 通过IDE(Android Studio、Eclipse)自动build生成;
- 手动通过dx命令去生成dex文件;(IDE内部也是通过dex命令生产dex文件)
如上图,dx命令程序位于 sdk/build-tools/27.0.3/dx 文件夹中,在编译dex文件时内部调用会使用到它。 需要注意的是在终端使用dex命令时,需要在电脑上配置Android相关的环境变量,否则会出现 dex: command not found 错误,配置方法如下:
Mac
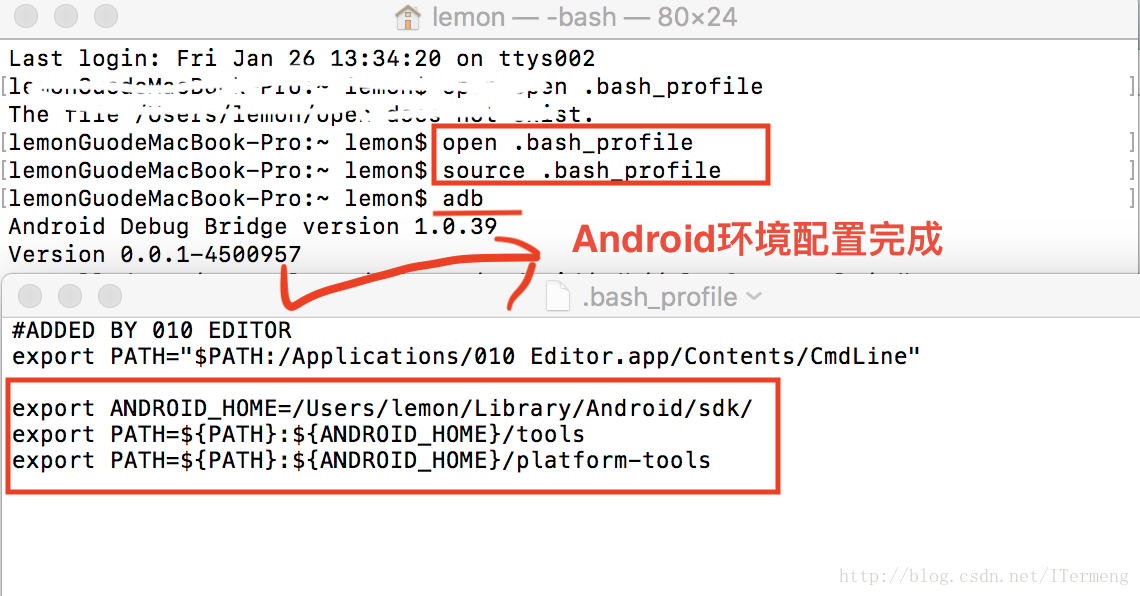
- 打开terminal终端,输入
open .bash_profile(若无此文件,则输入touch .bash_profile创建) - 在打开的文本编辑器中写入如下代码:
export ANDROID_HOME=/usr/local/opt/android-sdk
export PATH=${PATH}:${ANDROID_HOME}/tools
export PATH=${PATH}:${ANDROID_HOME}/platform-tools- 将以上步骤的 ANDROID_HOME 更换成自己sdk的路径。sdk路径可根据Android Studio,在preference(Windows的setting)中搜索sdk来查看。
- 在终端中输入
source .bash_profile使其生效,环境配置完成。
Windows
Go to 控制面板→ 系统安全 → 系统 → Change 设置 → 高级系统设置 → 环境变量 → 创建一个新的变量,变量名为ANDROID_HOME ,变量路径为 android sdk path。
(Windows环境下修改较简单,不赘述,以下链接是stackoverflow对于android: command not found 的详细解答:
stackoverflow解答———-android: command not found )
(3)dx命令生成dex文件
以上在配置好环境之后,接下里可使用dex命令生成dex文件,这里同使用javac 生成class文件相比,只在其基础上多一步:dx --dex -- output Hello.dex Hello.class,这行命令也好了解,output输出的格式为 Hello.dex ,而使用的字节码文件Hello.class,步骤如下:
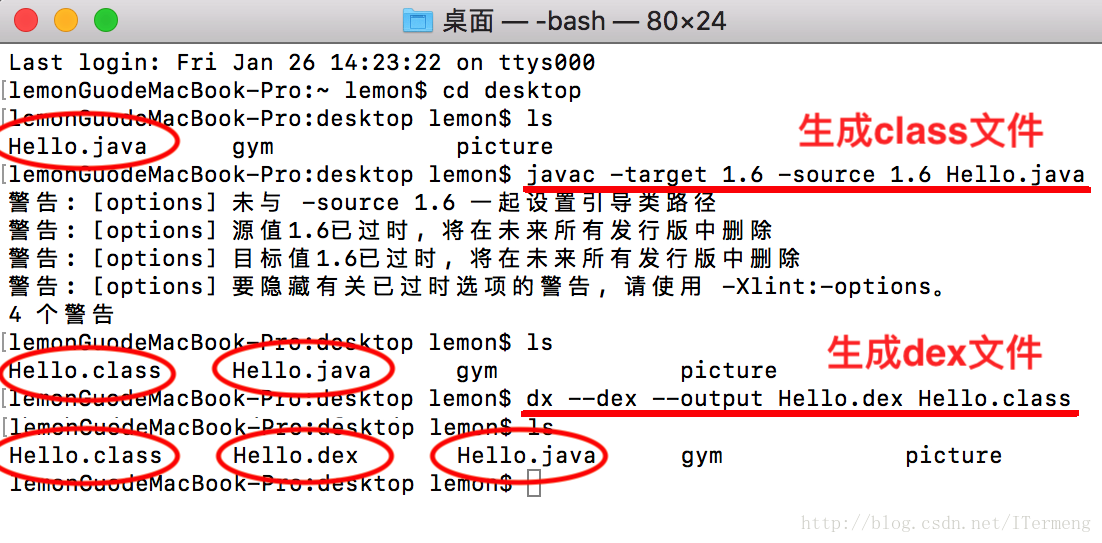
注意:生成dex文件就是基于生成class文件的基础上再使用dx命令编译,这里需要强调的是在生成字节码文件时最好指定JDK版本为1.6,以免本机JVM版本导致生成的class文件版本过高,从而部分安卓设备无法执行,JDK 1.6基本可以在所有手机上执行。
(4)执行dex文件
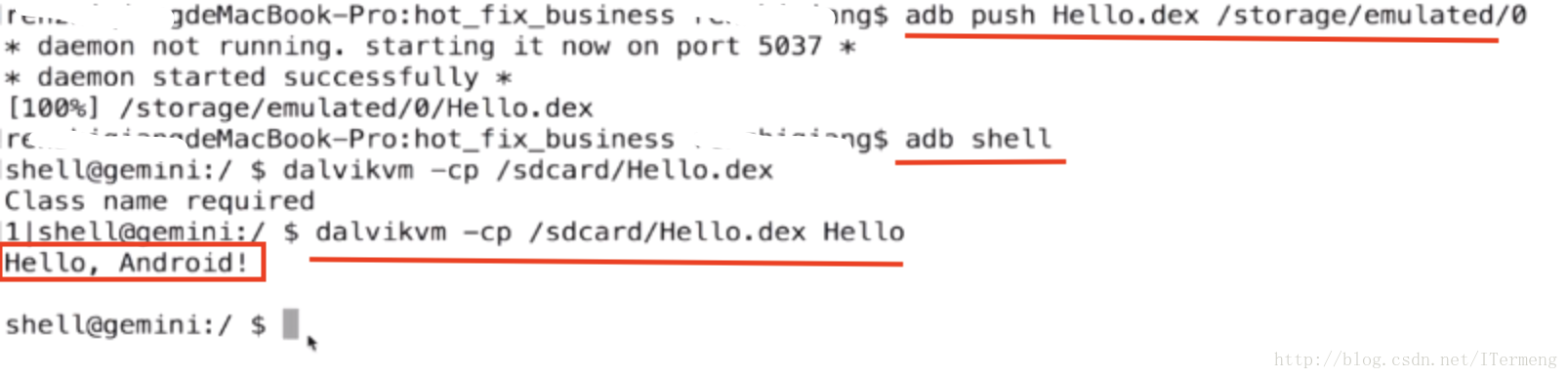
以上生成dex文件后,不同于class文件可直接使用java命令执行,这里需要使用真机或模拟卷测试:
- 要想执行dex文件,首先需要将文件push 到手机中,使用
adb push Hello.dex /storage/emulated/0命令。(注意后续的路径需要替换到实际存储路径) - 通过
adb shell命令进入到手机控制台。 - 通过
dalvik -cp /sdcard/Hello.dex - 此时终端会提示
class name required,即缺少一个参数,还需要指定其对应的class文件名称。 - 最后在终端成功显示Hello类中输出的“Hello, Android!”
(5)dex文件的作用
记录整个工程中所有类文件的信息,注意是“整个工程”,即所有类文件信息。从这里可见dex文件的优势,不同于class文件,单一文件只记录单一类的信息,而dex是记录整个工程的所有类信息数据,也是其最大的优势体现了。
2. dex文件格式详解
(1)dex文件特点
首先从整体来分析dex文件有哪些特点:
- 一种8位字节的二进制流文件
- 各个数据按顺序紧密排列,无间隙
- 整个应用中所有Java源文件都放在一个dex文件中(此处暂不考虑Android为开发者提供的multidex技术)
(2)dex文件内部结构
接下来详解dex文件中的字段组成及各字段含义作用,
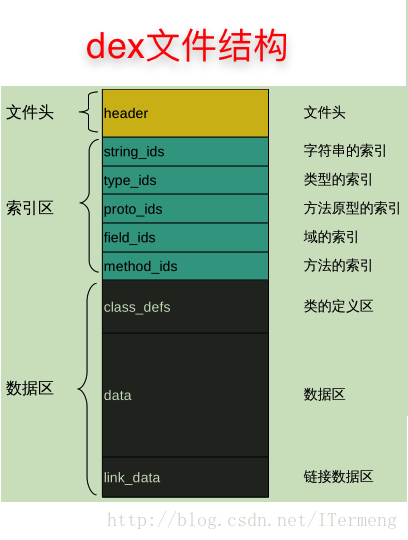
- 文件头:header记录了dex文件信息及所有字段大致的分布;
- 索引区:分别记录了字符串、类型、方法原型、域、方法的索引,这部分指定了dex文件中所有不同类型数据存储的位置,数据最终存储于“数据区”;
- 数据区:此块可分成普通数据区和链接数据区,后者听起来较为陌生,总所周知Android中常有一些动态链接库so的引用,而链接数据区就是对这个的指向。
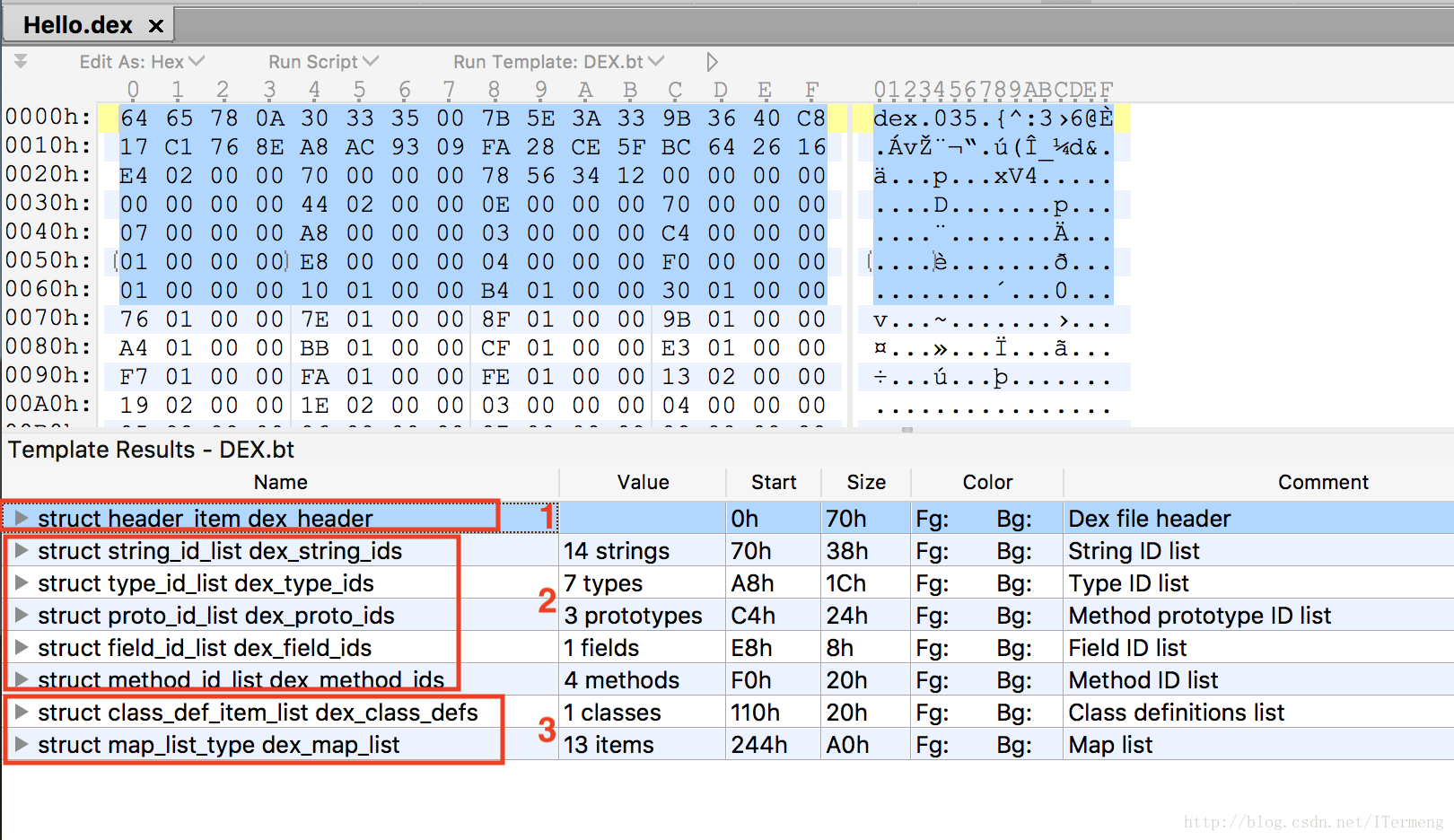
(3)字段详解
I. 文件头
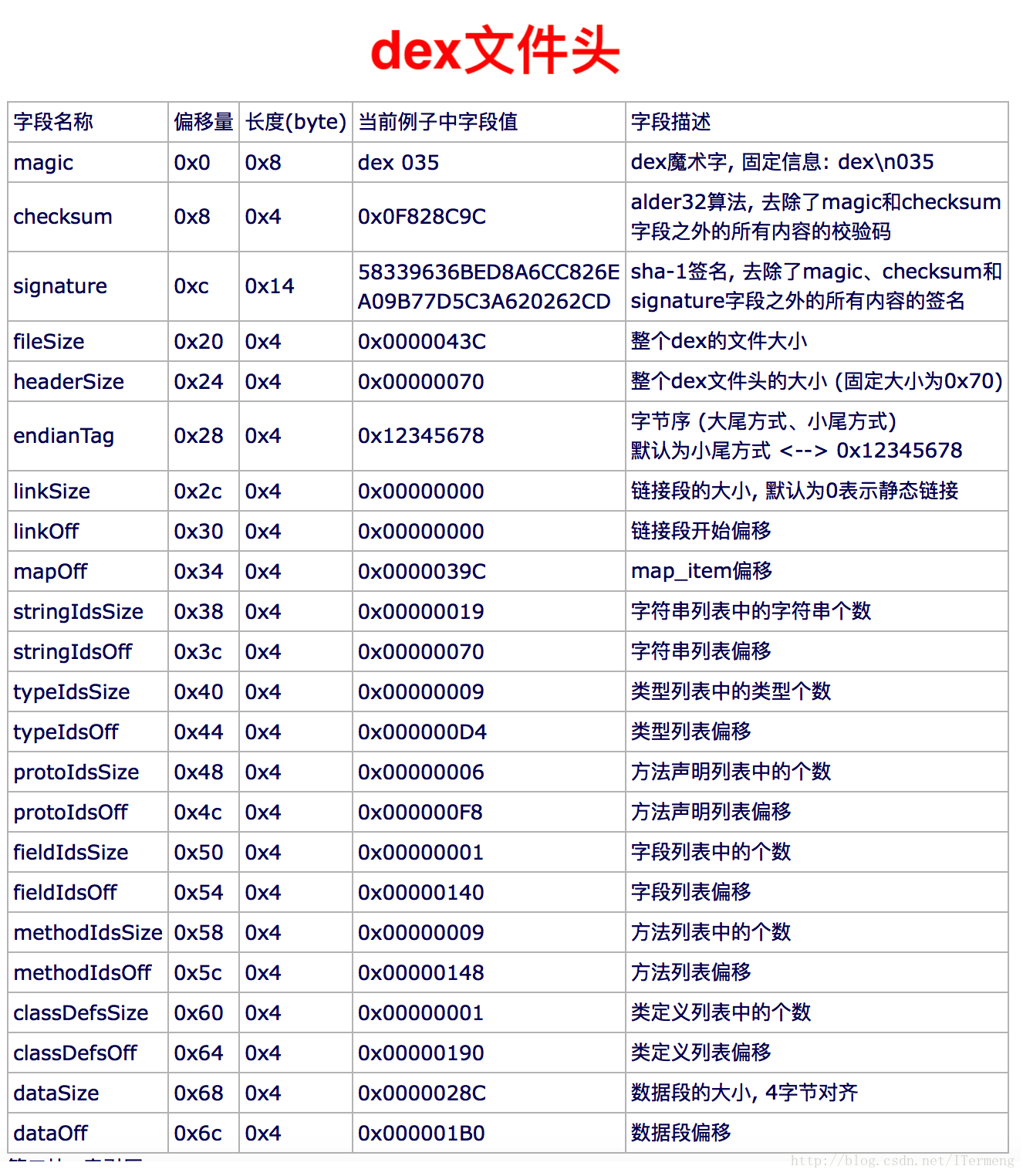
如上图是文件头中所有字段名称、长度和作用,列表中已详细说明,在此无需赘述。与class文件相比,仅仅是dex文件头就包含大量字段,可见其优势之大。
文件头数据对照字段即可理解其含义,剩下来的还是采用010Editor 实际查看,打开Hello.dex文件的真实数据如下:
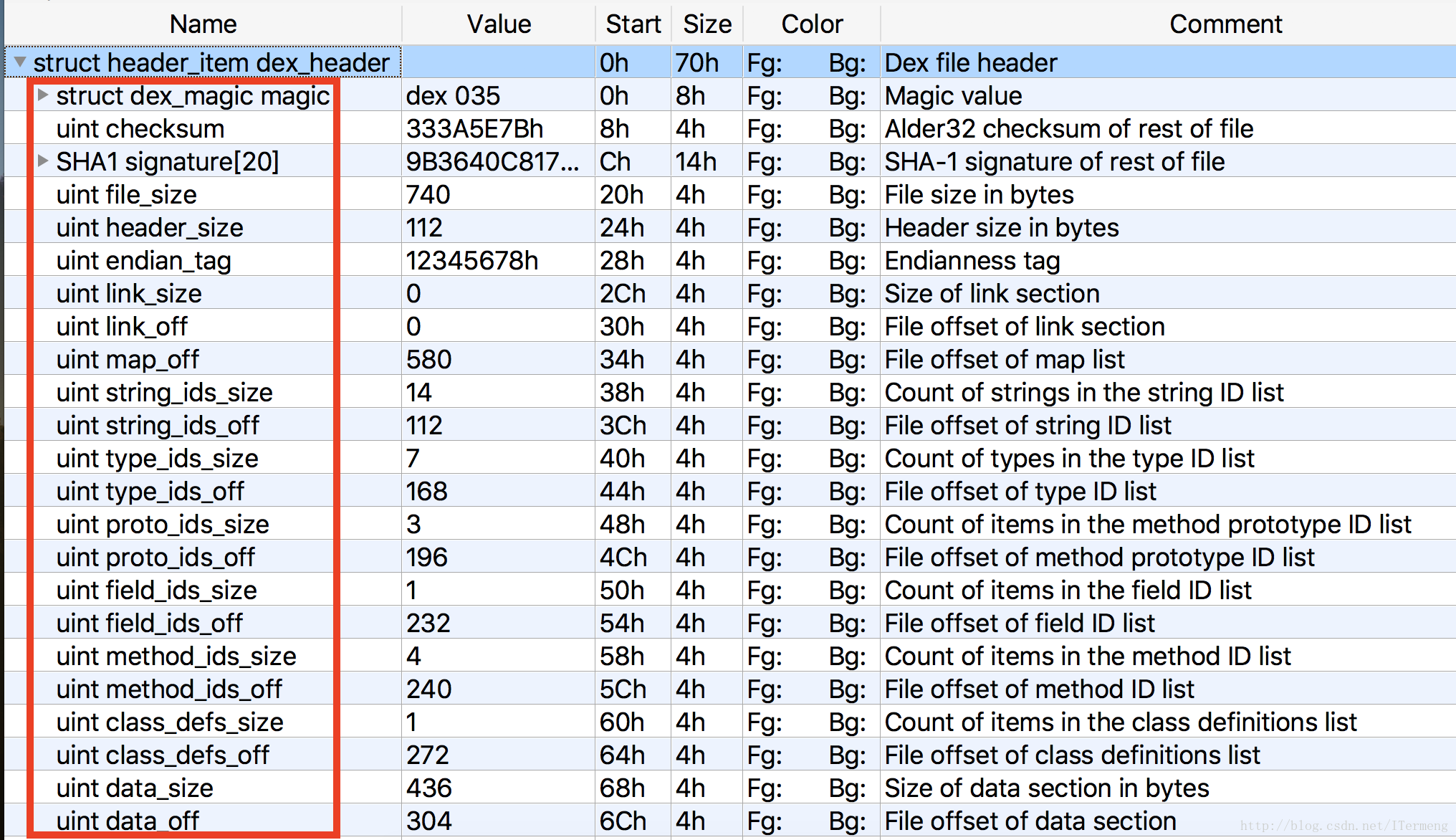
II. 索引区
分别记录了字符串、类型、方法原型、域、方法的索引,以下依次介绍:
① 字符串索引区:描述dex文件中所有的字符串信息
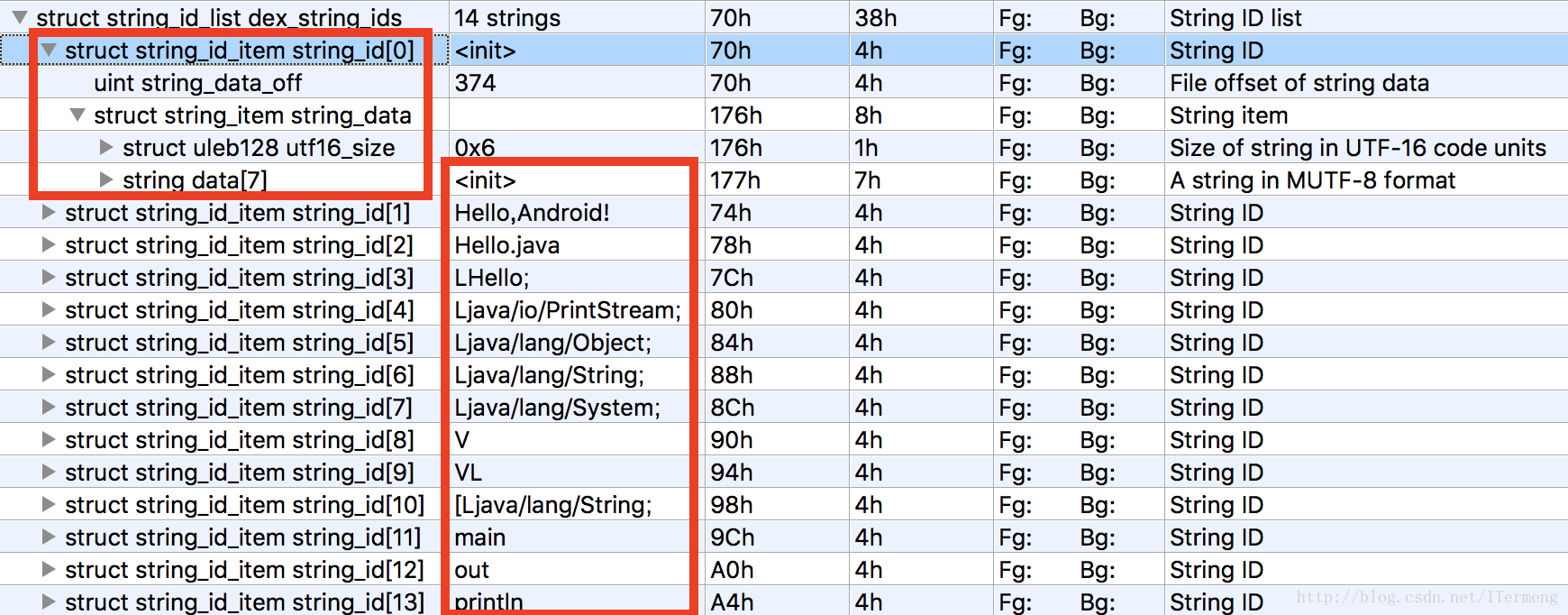
ubyte 8-bit unsinged int
uint 32-bit unsigned int
uleb128 unsigned LEB128, valriable length
struct string_ids_item
{
uint string_data_off;
}
struct string_data_item
{
uleb128 utf16_size;
ubyte data;
}如上经过010Editor自动分析数据后,可知字符串索引的结构体string_id_item :以上就是字符串索引结构体的组成,需要注意的是string_ids 是比较关键的,因为后续很多区段都是直接指向 string_ids 的 index。
大家可能会疑问Java源码中哪些“字符串”会被记录到dex文件中,见下图列举了源码中所有会被记录到字符串:

Java源码和dex对比
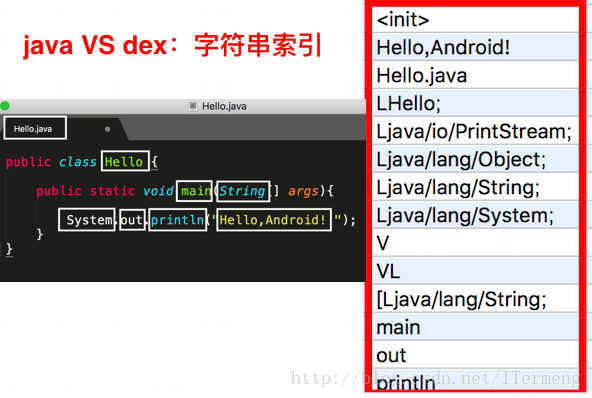
如上图,将Java源码和010Editor打开的dex文件中字符串列表对比,可以发现定义的类的 类名、方法名、 方法参数类型、字符串、调用的系统函数名 和源码的文件名 在字符串列表中都有对应的值!
字符串混淆
在了解此部分知识后会发现,他人可通过你的dex文件字符串列表信息“偷窥”到源码信息,正所谓“魔高一尺,道高一丈”,我们也可进行字符串混淆,把当前有意义的字符串名称替换成像a b c这样无意义的名称,从而实现一个字符串混淆器。可是只依靠字符串列表就实现混淆是不够的, 因为系统函数的名称不能被混淆,例如System.out.print、main等,所以还需要借助其他索引区的信息将一些不能被混淆的字符串排除掉。(这里只是提出简单的想法,后续再详解)
② 类型索引区: 描述dex文件中所有的类型, 如类类型、基本类型、返回值类型等
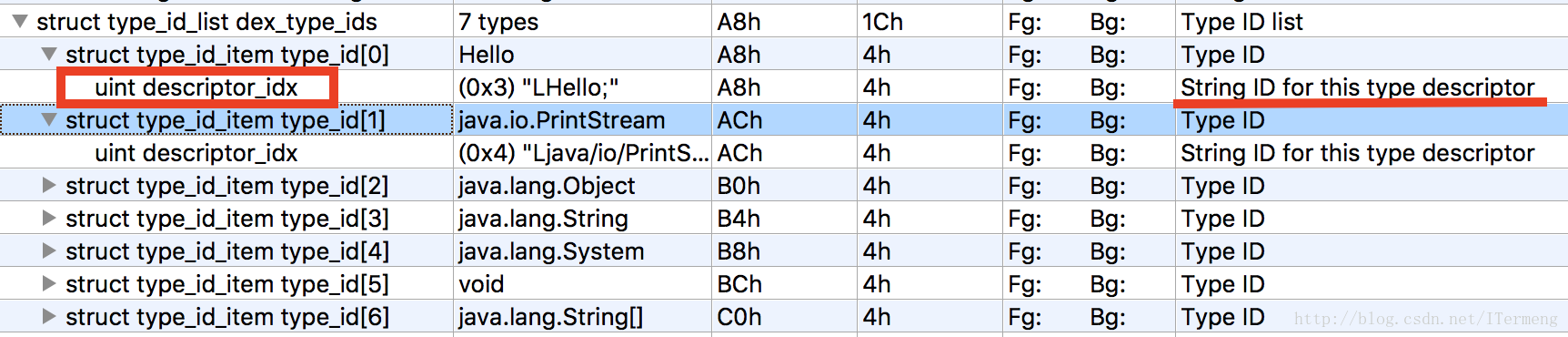
uint 32-bit unsigned int
struct type_ids_item
{
uint descriptor_idx; //-->string_ids
}类型索引的结构体type_ids_item 里面只有一个成员是指向字符串索引区的下标 descriptor_idx ,指 string_ids 里的 index 序号,是用来描述此 type 的字符串。
Java源码和dex对比
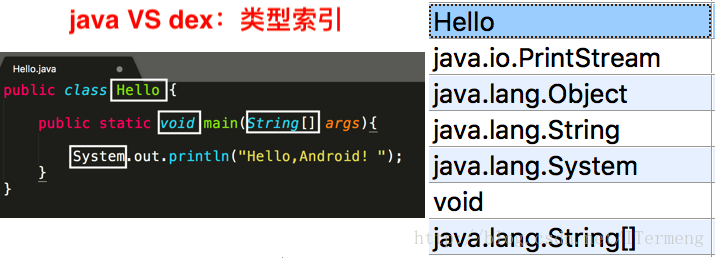
如上图可见,Java源码中的类类型、返回值类型 等在dex文件中的类型列表都有对应的值。
混淆
在讲解字符串索引时提到可对字符串数据进行混淆,但仅此还不够。在学习类型索引此部分, 可知在做dex字符串混淆时, 可通过类型索引区过滤掉描述系统类类型、返回值类型的字符串,当然这些工作依旧不够, 还需要借助其他索引区进行相应的排除。
③ 方法声明索引区: 描述dex文件中所有的方法声明

uint 32-bit unsigned int
struct proto_id_item
{
uint shorty_idx; //DexStringId中的索引下标
uint returnTypeIdx; //DexTypeId中的索引下标
uint parametersOff; //DexTypeList的偏移
}- shortyIdx:方法声明字符串。类似于 type_ids ,值是一个 string_ids 的 index 号 ,即一个用来说明该 method 原型的字符串描述。
- returnTypeIdx:方法返回类型字符串。值是一个 type_ids 的 index 号 ,表示该 method 原型的返回值类型。
- parametersOff:指向一个DexTypeList结构体, 存放了方法的参数列表, 如果方法没有参数值为0。(参数列表的格式是 type_list,下面会有描述。)
④ 字段索引区: 描述dex文件中所有的字段声明, 这个结构中的数据全部都是索引值, 指明了字段所在的类、字段的类型以及字段名称

ushort 16-bit unsigned int
uint 32-bit unsigned int
struct filed_id_item
{
ushort class_idx; //-->type_ids
ushort type_idx; //-->type_ids
uint name_idx; //-->string_ids
}- class_idx: 表示 field 所属的 class 类型,class_idx 的值是 type_ids 的一个 index,并且必须指向一个 class 类型。
- type_idx: 表示 field 的类型,它的值也是 type_ids 的一个 index 。
- name_idx: 表示 field 的名称,值也是 string_ids 的一个 index 。
⑤ 方法索引区: 描述Dex文件中所有的方法, 指明了方法所在的类、方法的声明以及方法名字

ushort 16-bit unsigned int
uint 32-bit unsigned int
struct filed_id_item
{
ushort class_idx; //-->type_ids
ushort proto_idx; //-->proto_ids
uint name_idx; //-->string_ids
}- class_idx: 表示 method 所属的 class 类型,class_idx 的值是 type_ids 的一个 index,并且必须指向一个 class 类型。注意:Android开发中著名的方法数65535限制的问题原因就在此字段:class_idx是ushort类型,2个字节,16位,2的16次方是65535,因此要求方法数最大为65535,过多则需要分包(multidex)。
- proto_idx: 表示 method 的类型,它的值也是 type_ids 的一个 index。
- name_idx:表示 method 的名称,它的值是 string_ids 的一个 index。
III. 数据区
在解析之前需要注意的是,数据区是dex文件最为核心且复杂的内容,但是这个dex文件中只有Hello源码的数据,因此有的字段中无数据,下面还是会具体介绍重点字段结构含义。
(我在分析完以下字段后,实在是头昏脑胀,遂画出以下DexClassDef的结构图,有助于理解归纳)
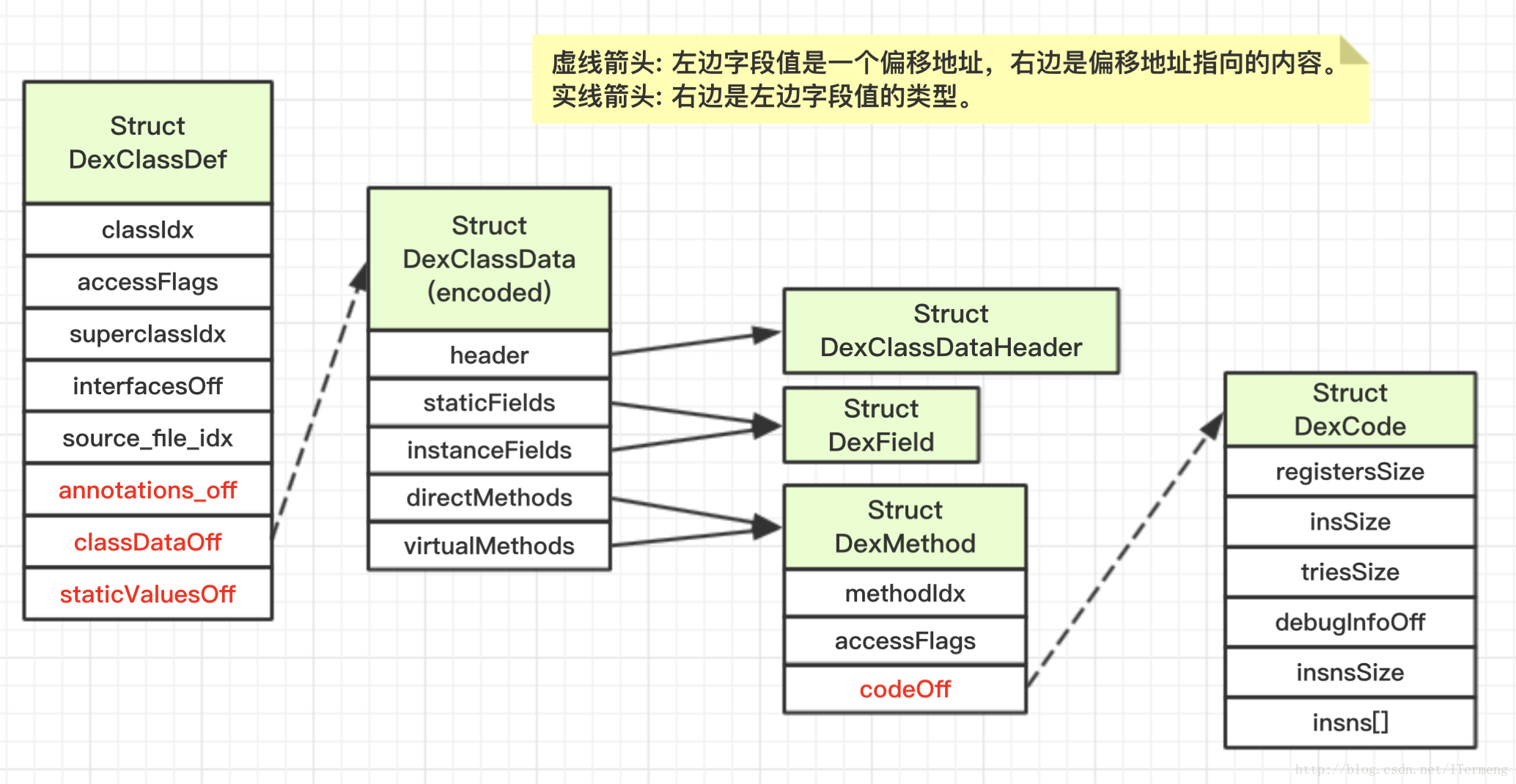
① class_def_item:由dex文件头中的classDefsSize和classDefsOff所指向, 描述Dex文件中所有类定义信息, 每一个DexClassDef中包含一个DexClassData的结构(classDataOff)
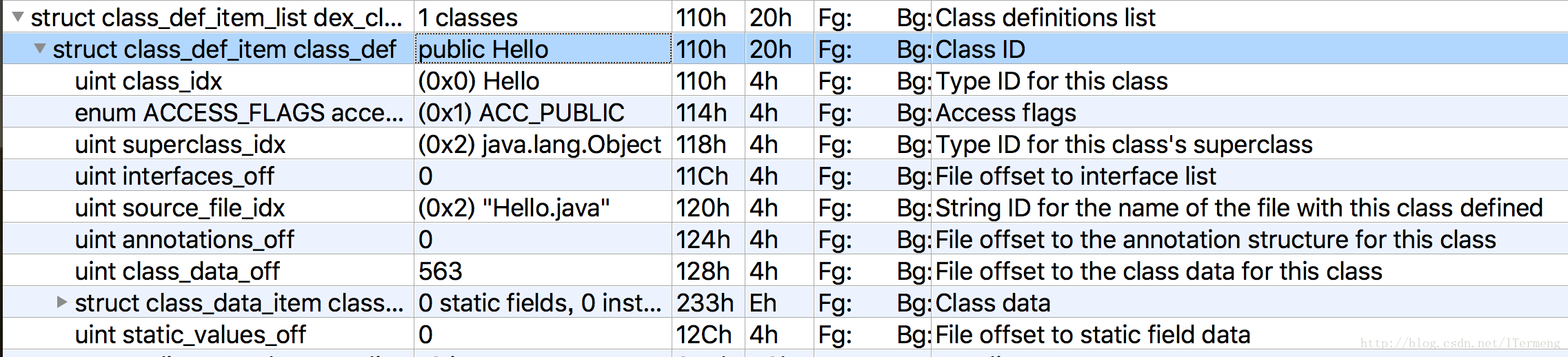
struct DexClassDef {
u4 classIdx; //类的类型, DexTypeId中的索引下标
u4 accessFlags; //访问标志
u4 superclassIdx; //父类类型, DexTypeId中的索引下标
u4 interfacesOff; //接口偏移, 指向DexTypeList的结构
u4 sourceFileIdx; //源文件名, DexStringId中的索引下标
u4 annotationsOff; //注解偏移, 指向DexAnnotationsDirectoryItem的结构
u4 classDataOff; //类数据偏移, 指向DexClassData的结构
u4 staticValuesOff; //类静态数据偏移, 指向DexEncodedArray的结构
};
- class_idx: 描述具体的 class 类型,值是 type_ids 的一个 index 。值必须是一个 class 类型,不能是数组类型或者基本类型。
- access_flags: 描述 class 的访问类型,诸如 public , final , static 等。
- superclass_idx: 描述 supperclass 的类型,值的形式跟 class_idx 一样 。
- interfaces_off: 值为偏移地址,指向 class 的 interfaces,被指向的数据结构为 type_list 。class 若没有 interfaces 值为 0。
- source_file_idx: 表示源代码文件的信息,值是 string_ids 的一个 index。若此项信息缺失,此项值赋值为 NO_INDEX=0xffff ffff。
- annotions_off: 值是一个偏移地址,指向的内容是该 class 的注释,位置在 data 区,格式为 annotations_direcotry_item。若没有此项内容,值为 0 。
- class_data_off: 值是一个偏移地址,指向的内容是该 class 的使用到的数据,位置在 data 区,格式为 class_data_item。若没有此项内容值为 0。该结构里有很多内容,详细描述该 class 的 field、method, method 里的执行代码等信息,后面会介绍 class_data_item。
- static_value_off: 值是一个偏移地址 ,指向 data 区里的一个列表 (list),格式为 encoded_array_item。若没有此项内容值为 0。
需要注意的是上述字段中多数值都是一个偏移地址,这意味着其真正指向的是另一个结构,以下将介绍上述偏移地址指向的真正内容:type_list、annotations_direcotry_item、class_data_item、encoded_array_item。
type_list

type_list 结构是class_def_item的interface_off 所指部分,数据结构如下:
uint 32-bit unsigned int
struct type_list
{
uint size; //类型个数
type_item list [size];
}
struct type_item
{
ushort type_idx //对应一个 type_ids 的 index
}annotations_directory_item

annotations_directory_item是class_def_item中的annotations_off 所指向的数据区段,定义了 annotation 相关的数据描述,数据结构如下:
uint 32-bit
struct annotation_directory_item
{
uint class_annotations_off; //此偏移指向了
uint fields_size; //表示属性的个数
uint annotated_methods_size; //表示方法的个数
uint annotated_parameters_size; //表示参数的个数
field_annotation field_annotations[fields_size];
method_annotation method_annotations[annotated_methods_size];
parameter_annotation parameter_annotations[annotated_parameters_size];
}
struct field_annotation
{
uint field_idx;
uint annotations_off; //-->annotation_set_item
}
struct method_annotation
{
uint method_idx;
uint annotations_off; //-->annotation_set_item
}
struct parameter_annotation
{
uint method_idx;
uint annotations_off; //-->annotation_set_ref_list
}encoded_array_item

encoded_array_item是class_def_item的static_value_off 偏移指向该区段数据,数据结构如下:
uleb128 unsigned LEB128
struct encoded_array_item
{
encoded_array value;
}
struct encoded_array
{
uleb128 size;
encoded_value values[size];
}class_data_item
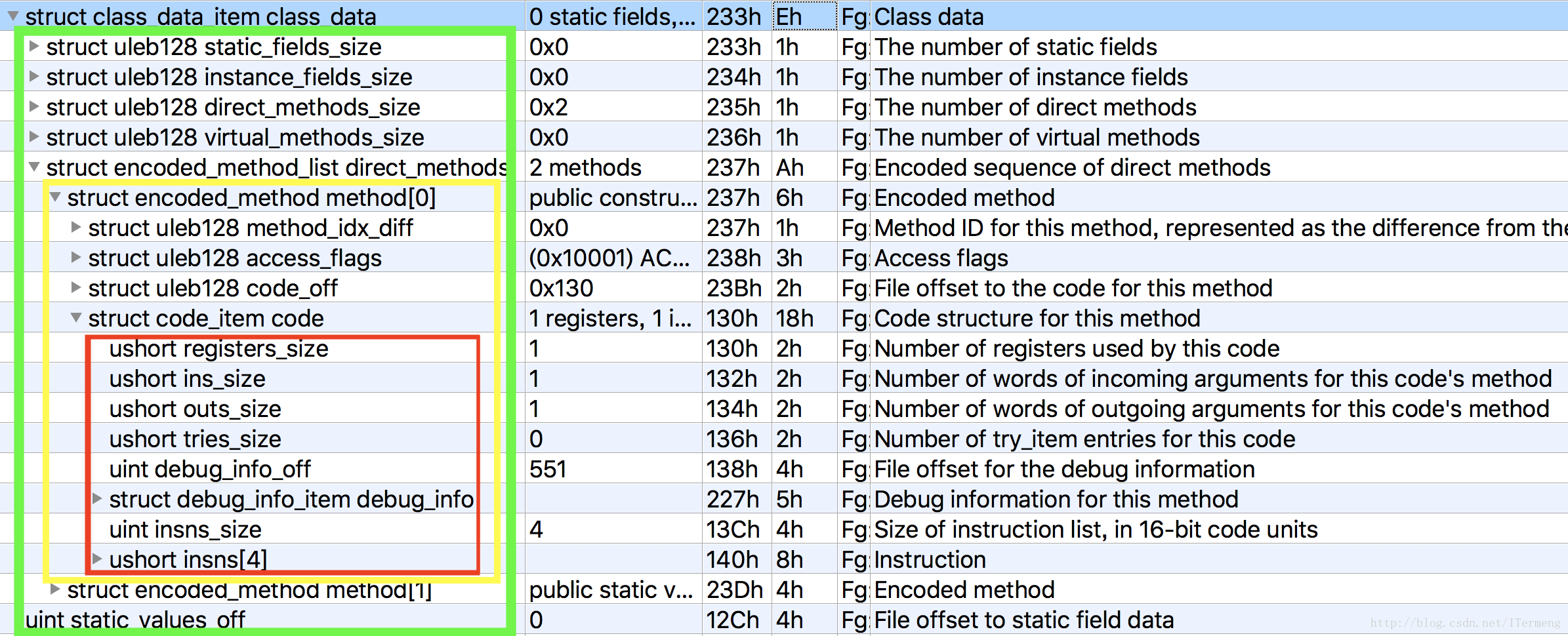
注意,此结构内含嵌套,可谓是数据区中最复杂的部分,每一个DexClassData中包含了一个Class的数据, Class数据中包含了所有的方法, 方法中包含了该方法中的所有指令。结构如下,搭配最下结构图理解:(此处为了助于理解,直接采用DexClassDef这种写法,并非010Editor中的class_data_item,同样可根据上图一一对应)
struct DexClassDef {
u4 classIdx; //类的类型, DexTypeId中的索引下标
u4 accessFlags; //访问标志
u4 superclassIdx; //父类类型, DexTypeId中的索引下标
u4 interfacesOff; //接口偏移, 指向DexTypeList的结构
u4 sourceFileIdx; //源文件名, DexStringId中的索引下标
u4 annotationsOff; //注解偏移, 指向DexAnnotationsDirectoryItem的结构
u4 classDataOff; //类数据偏移, 指向DexClassData的结构
u4 staticValuesOff; //类静态数据偏移, 指向DexEncodedArray的结构
};
struct DexClassData {
DexClassDataHeader header; //指定字段与方法的个数
DexField* staticFields; //静态字段
DexField* instanceFields; //实例字段
DexMethod* directMethods; //直接方法
DexMethod* virtualMethods; //虚方法
};
struct DexClassDataHeader {
uleb128 staticFieldsSize; //静态字段个数
uleb128 instanceFieldsSize; //实例字段个数
uleb128 directMethodsSize; //直接方法个数
uleb128 virtualMethodsSize; //虚方法个数
};
struct DexMethod {
uleb128 methodIdx; //指向DexMethodId的索引
uleb128 accessFlags; //访问标志
uleb128 codeOff; //指向DexCode结构的偏移
};
struct DexCode {
u2 registersSize; 使用的寄存器个数
u2 insSize; 参数个数
u2 outsSize; 调用其他方法时使用的寄存器个数
u2 triesSize; Try/Catch个数
u4 debugInfoOff; 指向调试信息的偏移
u4 insnsSize; 指令集个数, 以2字节为单位
u2 insns[1]; 指令集
//followed by optional u2 padding
//followed by try_item[triesSize]
//followed by uleb128 handlersSize
//followed by catch_handler_item[handlersSize]
};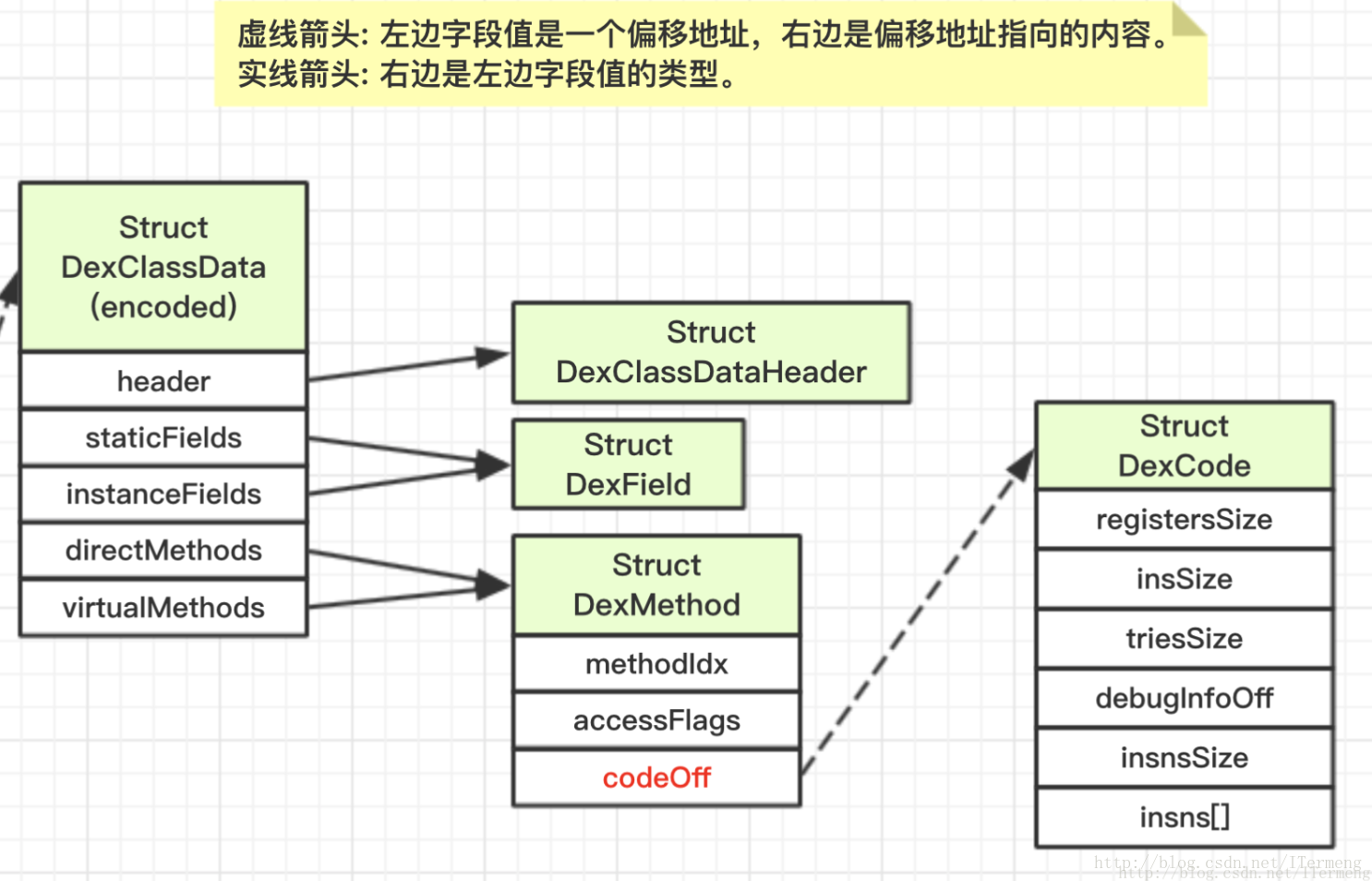
将以上DexClassData整体结构结合上图结构图共同理解,较为容易。
② map_list:其中多数 item 跟 header 中的相应描述相同,都是介绍了各个区的偏移和大小,但是 map_list 中描述的更加全面,包括了 HEADER_ITEM 、TYPE_LIST、STRING_DATA_ITEM、DEBUG_INFO_ITEM 等信息
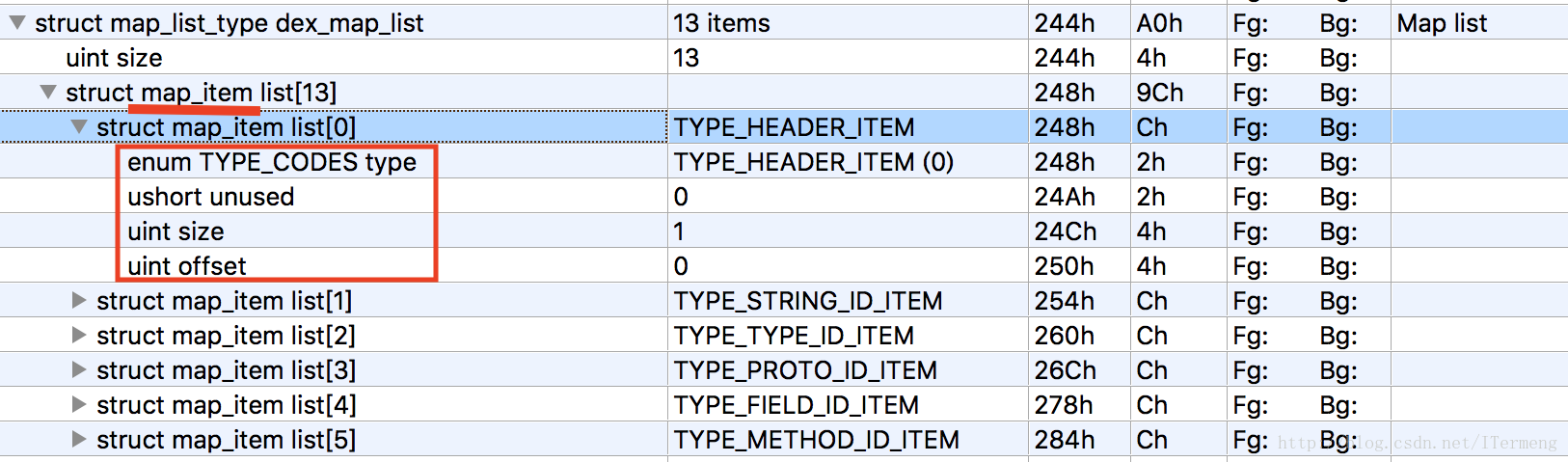
ushort 16-bit unsigned int
uint 32-bit unsigned int
struct map_list
{
uint size;
map_item list [size];
}
struct map_item
{
ushort type; // map_item 的类型,Dalvik Executable Format 里 Type Code 的定义
ushort unuse; //对齐字节的,无实际用处。
uint size; // size 表示再细分此 item,该类型的个数
uint offset; // 第一个元素的针对文件初始位置的偏移量
}map_list 里先用一个 uint 描述后面有 size 个 map_item,后续就是对应的 size 个 map_item 描述,map_item组成如上。
3. 补充点—— uleb128
以上在讲解 DexClassData等字段时多次提到uleb128,也就是unsigned LEB128。LEB128(little endian base 128)是一种变长的整数压缩编码形式,它是出自于DWARF debug file format。在Android的Dalvik Executable format中使用该编码用于表示32位整数。由于32位整数占用固定的4个字节,可能大多数整数并不需要4个字节,最高几个字节可能为0(正数)或者为1(负数),该编码就是不保存最高位的这些字节。
格式如下:

如上图,此处由2个字节表示,编码的每个字节有效部分只有低7bits,每个字节的最高bit用来指示是否是最后一个字节,非最高字节的bit7为0,最高字节的bit7为1。
leb128编码转换为可读数字的规则是:除去每个字节的bit7,将每个字节剩余的7个bits拼接在一起,即为数字。
一个简单例子如下:
LEB128编码的0x02b0 —> 转换后的数字0x0130
转换过程:
0x02b0 —> 0000 0010 1011 0000 –>去除最高位–> 000 0010 011 0000 –>按4bits重排 –> 00 0001 0011 0000 –> 0x130
(另还有转换代码,这里只做简单介绍,详细可自行查阅相关博文)
4.dex结构图
笔者认为dex文件内部结构着实有些复杂,结构体里又嵌套着另一层结构体,而且需要特别注意“偏移地址”这个概念,它相当于一个索引、指针,指向另外一个具体内容。
下图绘制归纳了dex文件的内部结构,整体分为文件头、索引区、数据区三个部分,文件头与索引区中字段类型较为单一,以上文章分析足以理解,只是数据区这一块数据类型嵌套较为复杂,这里详细绘制了数据区重点dexClassDef结构,供以理解:

三. 总结
根据010Editor解析,一个Hello.class数据就是一个结构体,而Hello.dex并不是,整体结构又分成三个区域 ,存储了整个工程的Java源文件信息。因此dex文件在类数量多多情况下优势愈加明显,它只需要一个dex文件记录数据并非多个class文件,区域复用,极大减少了dex文件内存占用大小。
class 与 dex 对比
- 同:本质上相同,dex是在class文件基础上编译而得,class文件是编译Java源文件而得。
- 异: class文件存在许多冗余信息,例如每个类的class文件中都有一个常量池,而dex会去除冗余,区域复用并整合,整个工程中的同类型数据存储在一个数据区域。
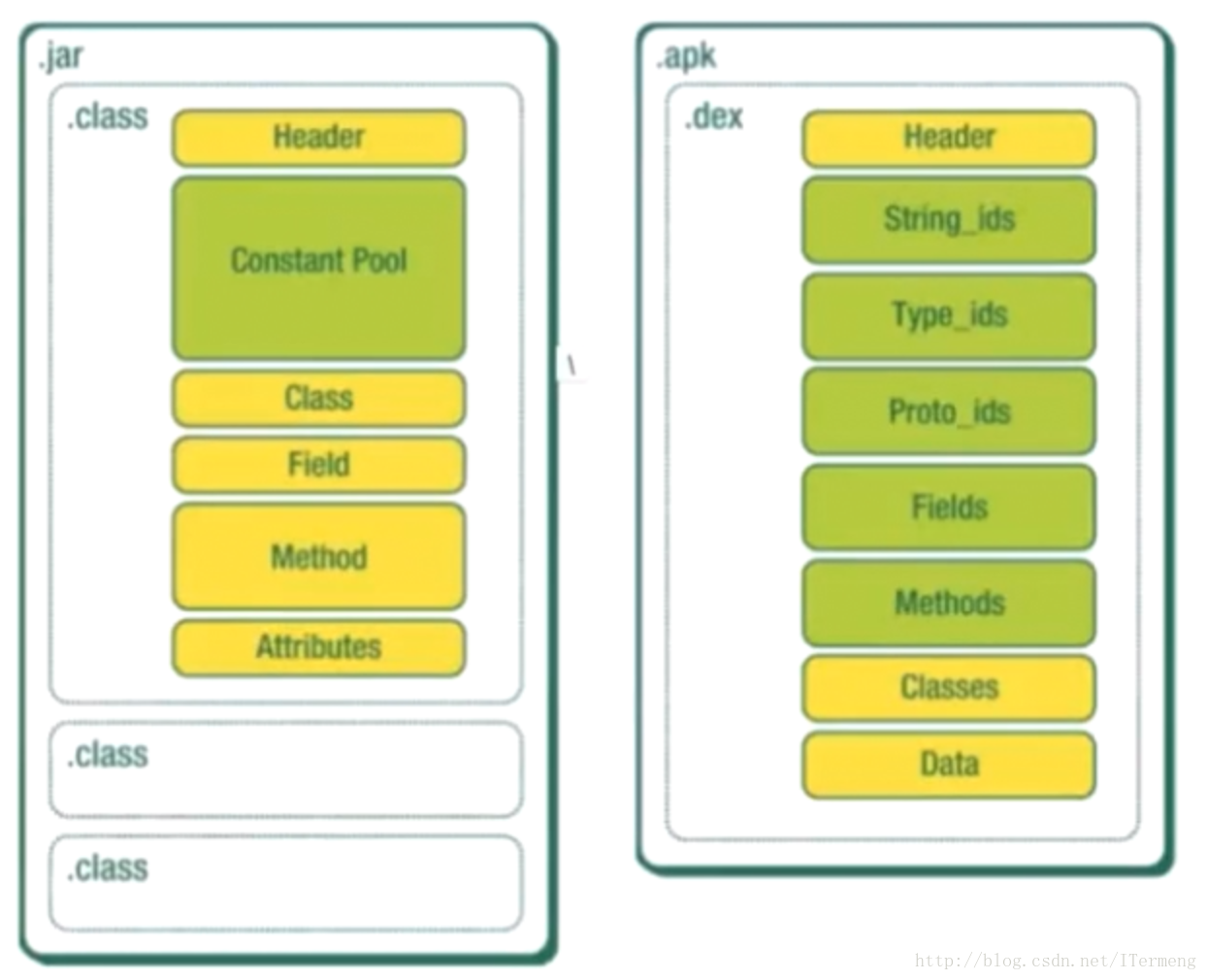
上图对比jar包和apk组成结构,可明显看出class和dex文件两者的差异!一个jar包中必定有多个类,因此编译后也有多个对应的class文件记录源文件信息;而apk中只有一个dex文件,此文件中有header、索引区、数据区这三个不同的区域来分类记录整个工程中的源文件信息。
此篇文章分析下来可见dex文件的强大之处和重要性,通过反编译可在dex文件中获取大量app中重要数据信息,因此也就凸显出了代码混淆的必要性!而上述dex字段讲解中也稍微涉及到了“混淆”之处及如何混淆,其实这就是混淆的原理,此篇文章重点还是文件结构解析,有关“代码混淆”和“反编译”以后再述。
注意:此篇文章的侧重点在 dex文件解析,而class在此篇文章是作为一个对比,毕竟解析class相关书籍较多,笔者的JVM相关博文有详细分析class文件结构,在此篇文章中就不赘述,只挑取重点部分,读者可移驾阅读,链接如下:
VM高级特性与实践(五):实例探究Class类文件 及 常量池
JVM高级特性与实践(六):Class类文件的结构(访问标志,索引、字段表、方法表、属性表集合)
https://source.android.com/devices/tech/dalvik/dex-format.html
在阅读了数篇其他类似题材的博文和官方网页知识理论后,结合自己的简单例子实践,得此篇博文,主要还是以分析dex、class两种格式文件结构为主。此篇博文分析下来着实有些心力交瘁,最大的原因还是因为笔者对dex的基础知识略生疏,后部分感觉稍浅,只是介绍了具体结构组成及含义,没有过多拓展,也未涉及到Dalvik指令,剖析未到位。再通过后续的学习会修改,基础真的是难啃啊,共勉~
若有错误,虚心指教~