在上一篇文章《 InfluxDB vs TimeScaleDB 功能/性能对比 (一)》中,主要对比了两种数据库在功能方面的差异,以及不进行任何优化的情况下,数据批量写入的性能、存储空间的占用情况。
本篇主要对两种数据库在实际应用场景中的读写性能、空间占用进行对比,针对实际应用场景,两种数据库在表结构上都做了一些优化。
目录
测试目的及最终结论
本次测试主要为了对比两种数据库写入性能以及不同场景下的查询性能。
由于InfluxDB的数据查询架构和数据存储方式特殊(数据存储可参见《InfluxDB存储引擎—— TSM文件与数据写入》,数据查询流程可参见《InfluxDB存储引擎—— TSI文件与数据读取》),因此fields的数量在一定程度会影响数据查询性能,所以整理了查询单列和查询所有列的测试结果。
总的来说,InfluxDB在写入性能和存储空间上有明显优势,读取时单列查询速度较快,多列查询性能比TimeScaleDB差。
所有结论都基于本次所采用的测试数据,不同的测试数据会有不同的测试结果。
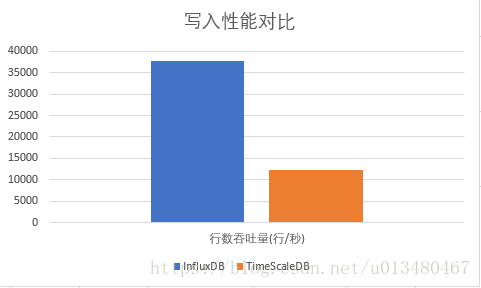
写入性能
InfluxDB的写入性能约为TimeScaleDB的3倍
存储空间占用
InfluxDB的存储空间占用不到TimeScaleDB的30%

读取性能
全表扫描性能对比
查询所有列时,TimeScaleDB的性能是InfluxDB的7倍左右
查询单列时,InfluxDB的性能是TimeScaleDB的2倍左右
详细数据见下文
条件查询性能对比
查询所有列时,TimeScaleDB的性能是InfluxDB的7倍左右
查询单列时,InfluxDB的性能是TimeScaleDB的2倍左右
详细数据见下文
聚合查询性能对比
聚合查询单列时InfluxDB的性能约为TimeScaleDB的2倍,聚合查询多列时TimeScaleDB性能几乎没有变化,InfluxDB的性能随着聚合查询列数的增加而降低,性能与聚合查询列数成反比。
详细数据见下文
测试环境
centos虚拟机
cpu: AMD Ryzen 5 1600 Six-Core(4线程)
内存:8G
磁盘:机械硬盘
TimeScaleDB配置
版本:PostgreSQL 10.4+TimeScaleDB 0.10
shared_buffers = 2g (推荐设置为机器内存的1/4,默认值为1g)
wal_buffers = 64m (推荐设置为shared_buffers的1/32,默认值为16m)
wal_writer_delay = 800ms(默认值200ms)
除上述修改之外均使用默认配置
InfluxDB配置
版本:1.6.0
cache-max-memory-size = "2g" (默认值为1g)
cache-snapshot-memory-size = "100m"(默认值为25m)
[http] log-enabled = false
wal与data目录指定不同磁盘
除上述修改之外均使用默认配置
测试数据
场景:
以1秒为时间间隔,采集机器资源消耗情况,并记录机器的操作系统以及所在城市。假设共4个数据源,采集9个指标,示例如图:

设计表结构:
CREATE TABLE test_function (
"time" timestamp with time zone,--以1秒递增
type text,--数据源属性,只有2个取值:windows/linux
address text,--数据源属性,只有2个取值:guangzhou/shenzhen
usage_system double precision,--以下其他字段全部为随机生成的double值
usage_idle double precision,
usage_nice double precision,
usage_iowait double precision,
usage_irq double precision,
usage_softirq double precision,
usage_steal double precision,
usage_guest double precision,
usage_guest_nice double precision
) tablespace with_index_ts;
总行数:1000万行
总数据量:900M
TimeScaleDB:时间分区跨度为7天,time/type/address三个字段带btree索引。
InfluxDB:时间分区跨度为7天,type/address设置为tag
测试方式
使用JAVA代码编写InfluxDB和TimeScaleDB的写入程序,在本地运行测试程序读写服务器的数据库。
测试用例及结果
写入性能
InfluxDB写入性能明显优于TimeScaleDB。
| 行数吞吐量(行/秒) | |
| InfluxDB | 37593 |
| TimeScaleDB | 12269 |
存储空间占用
InfluxDB对存储空间的占用明显小于TimeScaleDB。
| 空间占用(M) | |
| InfluxDB | 625 |
| TimeScaleDB | 2272 |
全表扫描性能
| sql | 符合条件的数据行数 | InfluxDB耗时(S) | TimeScaleDB耗时(S) | |
| 查询单列 | select count(usage_idle) from test_function; | 1000万 | 0.88 | 1.52 |
| 查询所有列 | select count(*) from test_function; | 1000万 | 6.759 | 1.04 |
条件查询性能
数据源维度查询
| sql | 符合条件的数据行数 | InfluxDB耗时(s) | TimeScaleDB耗时(s) | |||
| 数据源维度 | 数据源单个属性为条件 | 查询单列 | select count(usage_idle) from test_function where type = "windows"; | 500万 | 0.453 | 1.48 |
| 查询所有列 | select count(*) from test_function where type = "windows"; | 500万 | 3.43 | 1.43 | ||
| 数据源所有属性为条件 | 查询单列 | select count(usage_idle) from test_function where type = "linux" and address = "shenzhen"; | 250万 | 0.63 | 1.48 | |
| 查询所有列 | select count(*) from test_function where type = "linux" and address = "shenzhen"; | 250万 | 5.86 | 1.48 |
时间维度查询
| sql | 符合条件的数据行数 | InfluxDB耗时(s) | TimeScaleDB耗时(s) | ||
| 时间维度 | 查询单列 | select count(usage_idle) from test_function where time >= '2000-04-28' and time < '2000-04-29' | 345600行 | 0.09 | 0.11 |
| 查询所有列 | select count(*) from test_function where time >= '2000-04-28' and time < '2000-04-29' | 345600行 | 0.3 | 0.11 |
时间+数据源维度查询
| sql | 符合条件的数据行数 | InfluxDB耗时(s) | TimeScaleDB耗时(s) | |||
| 数据源+时间维度 | 时间+数据源单个属性为条件 | 查询单列 | select count(*) from test_function where type = 'linux' and time >= '2000-04-28' and time < '2000-04-29' | 172800行 | 0.09 | 0.09 |
| 查询所有列 | select count(*) from test_function where type = 'linux' and time >= '2000-04-28' and time < '2000-04-29' | 172800行 | 0.21 | 0.089 | ||
| 时间+数据源所有属性为条件 | 查询单列 | select count(*) from test_function where time >= '2000-04-28' and time < '2000-04-29' and address = 'guangzhou' and type = 'linux' | 86400行 | 0.06 | 0.09 | |
| 查询所有列 | select count(*) from test_function where time >= '2000-04-28' and time < '2000-04-29' and address = 'guangzhou' and type = 'linux' | 86400行 | 0.29 | 0.09 |
采集指标维度小范围查询
| sql | 符合条件的数据行数 | InfluxDB耗时(s) | TimeScaleDB耗时(s) | ||
| 小范围查询 | 查询单列 | select count(usage_idle) from test_function where usage_idle < 0.00001 | 109行 | 1.19 | 1.25 |
| 查询所有列 | select count(*) from test_function where usage_idle < 0.00001 | 109行 | 9.67 | 1.25 |
聚合查询性能
全表
| sql | 符合条件的数据行数 | InfluxDB耗时(s) | TimeScaleDB耗时(s) |
| select sum(usage_system) from test_function | 1000万 | 0.9 | 1.5 |
以数据源维度为聚合条件
| sql | 符合条件的数据行数 | InfluxDB耗时(s) | TimeScaleDB耗时(s) |
| select sum(usage_idle) ) from test_function group by type | 1000万 | 1.01 | 2.8 |
| select sum(usage_idle) from test_function group by type,address | 1000万 | 2.955 | 3.7 |
以时间维度聚合条件
| InfluxDB | TimeScaleDB | |
| sql | select count(usage_idle) from test_function group by time(1d) | select to_char(time, 'YYYY-MM-DD') as d , count(*) as cnt from test_function group by d |
| 耗时(S) | 0.9 | 9.2 |
| 符合条件的数据行数 | 1000万 | 1000万 |