Windows在默认情况下,将高地址的2GB空间分配给内核(也可配置1GB),而Linux默认情况下,将高地址的1GB空间分配给内核。这些分配给内核的空间叫内和空间,用户使用剩下的空间称为用户空间。
在用户空间里,有许多地址区间有特殊地位,一般来讲,应用程序使用的内存空间里有如下“默认”的区域;
(1)栈:栈用于维护函数调用的上下文,离开了栈函数调用就没法实现;栈通常在用户空间的做高位处分配;
(2)堆:用来容纳应用程序动态分配的内存区域,当使用malloc或new分配内存时,得到的内存来自堆里;堆通常存在栈的下方,堆一般比栈大很多;
(3)可执行文件映像:这里存储可执行文件在内存里的映像;(由于可执行文件在装载时实际上是被映射的虚拟空间,所以可执行文件很多时候又被称为映像文件)
(4)保留区:保留区并不是一个单一的内存区域,而是对内存中受到保护而禁止访问的内训区域的总称。例如0地址,是始终不能读写的。
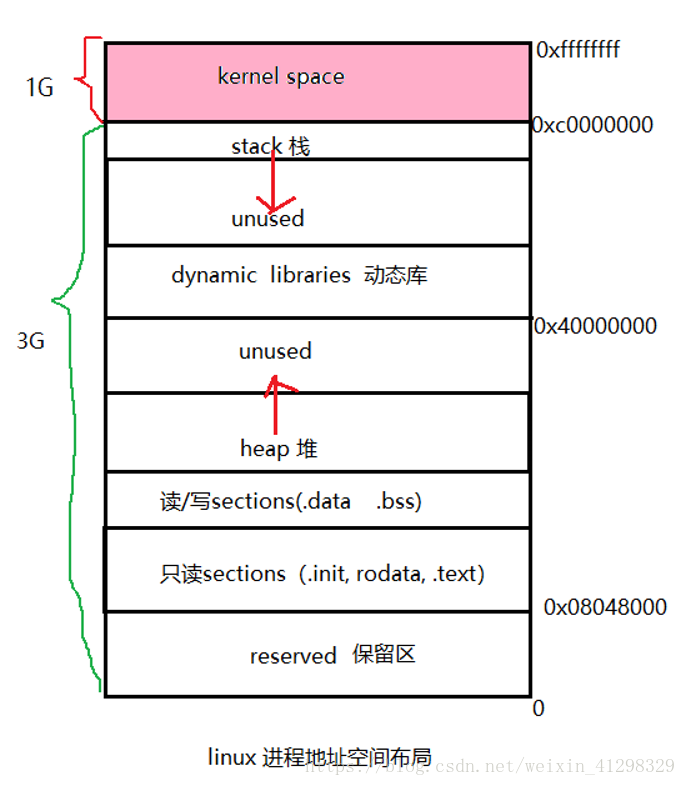
图中箭头标明几个大小可变的区的增长的方向,栈向低地址增长,堆向高地址增长,当栈或堆现有的大小不够用时,它将按照图中的增长方向扩大自身的尺寸,直到预留的空间被用完为止。
什么是栈?
定义:栈是一个特殊的容器,用户可以将数据压入栈中,(入栈push),也可以将已经压入栈中的数据弹出(出栈pop),但是栈必须遵循“先进后出”(first in last out )这个原则,就比如落成一叠的书。先叠上去的书在最下面,因此需要最后才能取出。
在经典操作系统里,栈总是向下增长的。栈顶由称为ESP的寄存器进行定位;
栈保存了一个函数调用所需要的维护信息,这常常被称为“堆栈帧”或活动记录;
堆栈帧一般保存:函数的返回地址和参数;
临时变量;
保存的上下文;
堆与内存管理
1、什么是堆:光有栈对于面向过程的程序设计是远远不够的,因为栈上的数据在函数返回的时候就会被释放掉,所以无法将数据传递至函数外部。而全局变量没有办法动态的产生,而堆是唯一选择。
堆是一块巨大的内存空间,常常占据整个虚拟空间的绝大部分,在这片空间里,程序可以请求一块连续的内存,并自由地使用,这块内存在程序主动放弃之前都一直有效。
例如:char *p=(char *)malloc(1000);
那么malloc到底是怎么实现的呢?
程序向操作系统申请一块适当大小的堆空间,然后由程序自己管理这块空间,具体来讲,管理着堆空间分配的往往是程序的运行库。
2、Linux进程堆管理
Linux下进程堆管理的两种堆空间分配的方式:即两个系统调用:一个brk()系统调用;一个是mmap();
3、Windows进程堆管理
(1)malloc申请的内存空间是不是连续的?
在分析这个问题之前,我们首先分清楚“空间”这个词所指的一意思,如果空间是指虚拟空间的话,那么答案是连续的,如果空间指的是物理空间的话,则答案是不一定连续,因为一块连续的虚拟空间有可能是若干个不连续的物理页拼凑而成。
(2)malloc申请的内存,进程结束以后还会不会存在?
答案是明确的,不会存在的,因为当进程结束后,所有与进程相关的资源,包括进程的地址空间,物理内存,打开的文件,网络链接等都被操作系统关闭或者收回,所以无论malloc申请了多少内存,进程结束以后都不存在了。