存储过程
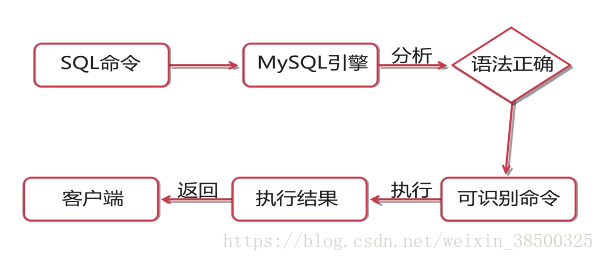
存储过程是SQL语句和控制语句的预编译集合,以一个名称存储并作为一个单元出来.
优点
- 增强SQL语句的功能和灵活性
- 实现较快的执行速度(省略了语法分析和识别)
- 减少了网络流量
创建存储过程
CREATE
[DEFINER = { user | CURRENT-USER )]
PROCEDURE sp_name ([ proc_parameter...J ])[ characteristic.. ] routine-body
proc_parameter:
[ IN | OUT | INOUT ] param_name type参数
- IN,表示该参数的值必须在调用存储过程时指定 ,
- OUT,表示该参数的值可以被存储过程改变,并且可以返回
- INOUT,表示该参数的调用时指定,并且可以被改变和返回
特性
- COMMENT:注释
- CONTAINS SQL:包含SQL语句,但不包含读或写数据的语句NO SQL:不包含SQL语句
- READS SQL DATA:包含读数据的语句
- MODIFIES SQL DATA:包含写数据的语句
- SQL SECURITY { DEFINER | INVOKER }指明谁有权限来执行
过程体
- 由合法的SQL语句构成
- 可以是任意的SQL语句
- 复合结构则使用BEGIN...END语句
- 复合结构可以包含声明,循环控制结构
//获取当前版本(不带参数)
CREATE PROCEDURE sp1() SELECT VERSION();//删除记录(带IN类型参数)
DELIMITER#解释命令是否结束
DELIMITER //
CREATE PROCEDURE removeUserById(IN D_id INT UNSIGNED)
BEGIN
DELETE FROM users WHERE id = D_id;
END
//
DELIMITER ;//删除记录并返回剩下记录(带OUT类型参数)
DELIMITER //
CREATE PROCEDURE removeUserAndReturnUserNums(IN D_id INT UNSIGNED,OUT userNums INT UNSIGNED)
BEGIN
DELETE FROM users WHERE id = D_id;
SELECT count(id) FROM users INTO userNums;
END
//
DELIMITER ;//根据年龄删除参数,返回剩下的参数(带多个OUT类型参数)
ROW_COUNT();//返回修改的行数
DELIMITER //
CREATE PROCEDURE removeUserByAgeAndReturnInfos(
IN D_age SMALLINT UNSIGNED,OUT deleteUsers SMALLINT UNSIGNED,
OUT userCounts SMALLINT UNSIGNED)
BEGIN
DELETE FROM users WHERE age = D_age;
SELECT ROW_COUNT INTO deleteUsers;
SELECT COUNT(id) FROM users INTO userCounts;
END
//
DELIMITER ;调用存储过程
- CALL sp_name([ parameter[,...]]) //带参数时,括号不可以省略
- CALL sp_name[()]
//调用存储过程sp1()
CALL sp1();//调用删除记录removeUserById()
removeUserById(3);//调用删除记录并返回剩下记录removeUserAndReturnUserNums()
CALL removeUserAndReturnUserNums(27,@nums);
SELECT @nums;//根据年龄删除参数,返回剩下的参数removeUserByAgeAndReturnInfos
CALL removeUserByAgeAndReturnInfos(20,@a,@b);修改存储过程
(不能修改过程体)
ALTER PROCEDURE sp name [characteristic ...
COMMENT 'string‘
I { CONTAINS SQL I NO SQL | READS SQL DATA | MODIFIES SQL DATA)
I SQL SECURITY { DEFINER | INVOKER}
删除存储过程
DROP PROCEDURE [IF EXISTS] sp_name;//删除removeUserById
DELETE PROCEDURE removeUserById;存储过程和自定义函数的区别

存储引擎
(表类型):以不同存储技术对数据进行存储
主要有
- MyISAM:适用于事务处理不多的情况
- InnoDB:适用于事务处理较多,需要外键支持的情况
- Memory
- CSV:不支持索引
- Archive
并发控制:控制同一时间多用户对数据访问,修改数据的一致性,完整性
- 共享锁(读锁)
- 排他锁(写锁):堵塞读写锁
锁颗粒
- 表锁:开销最小的锁策略
- 行锁:开销最大的锁策略
事务:用于保证数据库完整性
外键:保证数据一致性的策略
特性:(ACID)
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
索引:对表中一列或多列值进行排序的一种结构
- 普通索引
- 唯一索引
- 全文索引
- btree索引
- hash索引
各存储引擎的特点
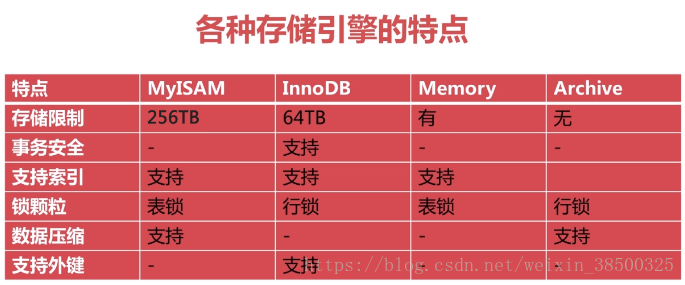
设置存储引擎
修改配置文件
-default-storage-engine = engine创建数据表命令实现
CREATE TABLE tb_name(
...
) ENGINE = engine;修改数据表命令实现
ALTER TABLE tb_name ENGINE [=] engine_name;//修改数据表引擎
ALTER TABLE tb1 ENGINE = InnoDB;