1.前言
dubbo我们通常用zk作为注册中心,那你们有想过dubbo把什么东西注册过去了么?

2.dubbo框架
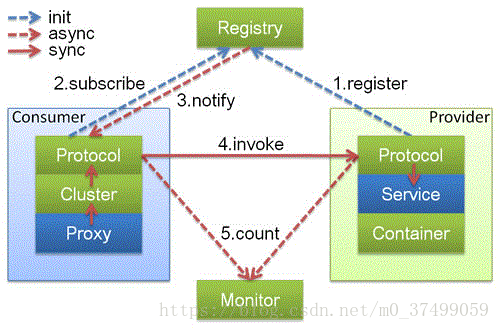
蓝色的表示与业务有交互,绿色的表示只对Dubbo内部交互。
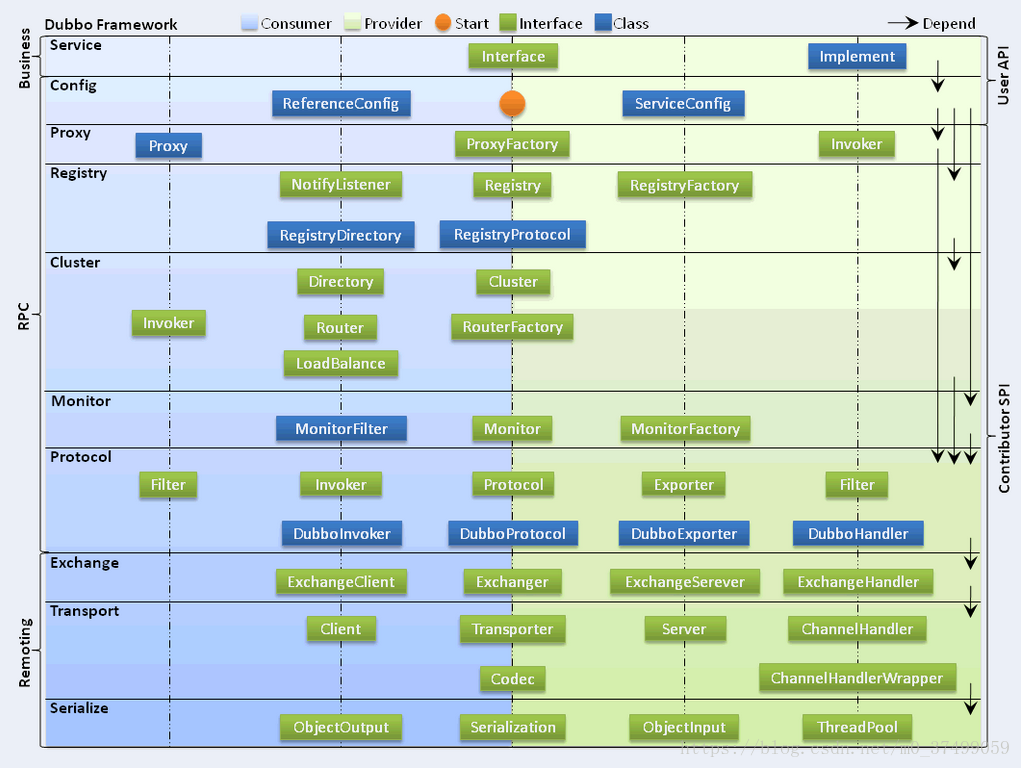
Dubbo框架设计一共划分了10个层,而最上面的Service层是留给实际想要使用Dubbo开发分布式服务的开发者实现业务逻辑的接口层:
1.服务接口层service :该层是与实际业务逻辑相关的
2.配置层 Config ;对外配置接口
3.服务代理层 Proxy :服务接口透明代理
4.服务注册层 Registry :封装服务地址的注册和发现
5.集群层 Cluster :封装多个提供者的路由及负载均衡,将多个服务提供方组合为一个服务提供方,实现对服务消费的透明
6.监控层 Monitor :RPC调用的次数和实际监控
7.远程调用层 Protocol :封装RPC调用,发起invoke调用
8.信息交换层 Exchange :同步,异步
9.网络传输层 Transport
10.数据序列化层 Serialize
Dubbo对于服务的提供方和服务消费方,从框架的10层中分别提供了个自需要关心和扩展的接口,构建整个服务生态系统.
3.zookeeper节点看到dubbo留下的注册信息
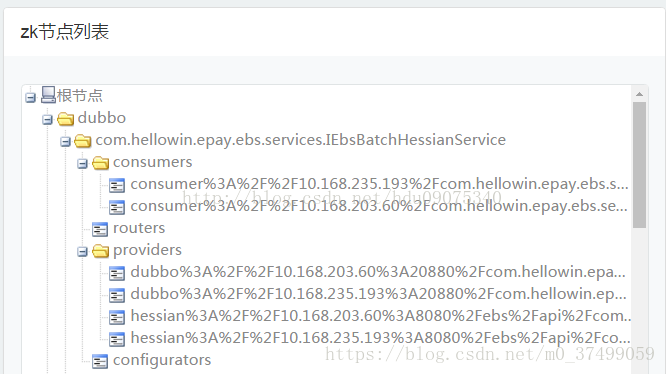
因为zookeeper中不能存特殊字符所以,子节点的内容做过转码
zookeeper用来注册服务和进行负载均衡,哪一个服务由哪一个机器来提供必需让调用者知道,简单来说就是ip地址和服务名称的对应关系。当然也可以通过硬编码的方式把这种对应关系在调用方业务代码中实现,但是如果提供服务的机器挂掉调用者无法知晓,如果不更改代码会继续请求挂掉的机器提供服务。zookeeper通过心跳机制可以检测挂掉的机器并将挂掉机器的ip和服务对应关系从列表中删除。至于支持高并发,简单来说就是横向扩展,在不更改代码的情况通过添加机器来提高运算能力。通过添加新的机器向zookeeper注册服务,服务的提供者多了能服务的客户就多了。
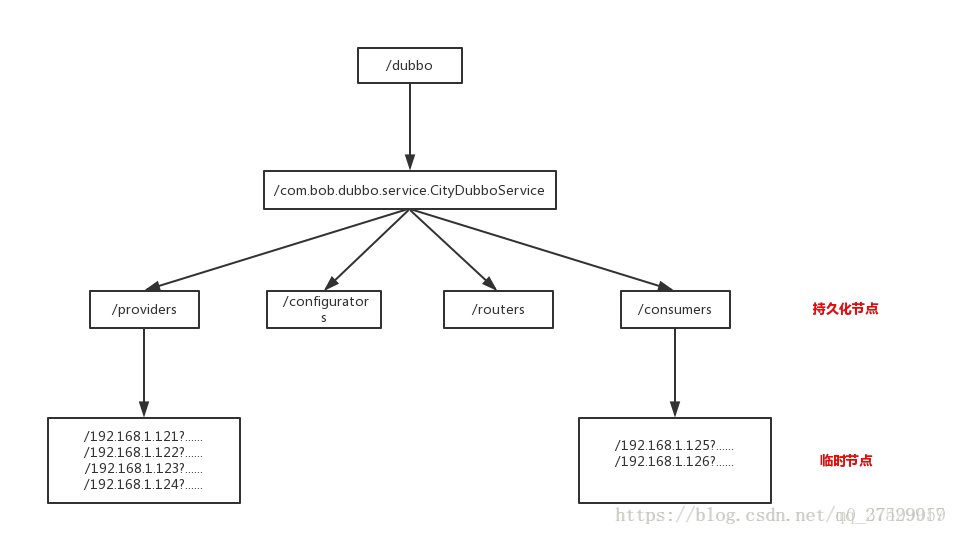
Dubbo启动时,Consumer和Provider都会把自身的URL格式化为字符串,然后注册到zookeeper相应节点下,作为一个临时节点,当连断开时,节点被删除。
Consumer在启动时,不仅仅会注册自身到 …/consumers/目录下,同时还会订阅…/providers目录,实时获取其上Provider的URL字符串信息。