一、LSH 介绍
LSH(Locality sensitive hashing)是局部敏感性hashing,它与传统的hash是不同的。传统hash的目的是希望得到O(1)的查找性能,将原始数据映射到相应的桶内。
LSH的基本思想是将空间中原始数据相邻的2个数据点通过映射或者投影变换后,这两个数据点在新的空间中的相邻概率很大,不相邻的点映射到同一个桶的概率小。我们可以看到将一个在超大集合内查找相邻元素的问题转化为了在一个很小的集合内查找相邻元素的问题,显然计算量下降了很多。下面借用一幅图来表示:

LSH满足如下条件:
•其中d(x,y)表示x和y之间的距离,d1 < d2,h(x)和h(y)分别表示对x和y进行hash变换。
•满足以上两个条件的hash functions称为(d1,d2,p1,p2)-sensitive。而通过一个或多个(d1,d2,p1,p2)-sensitive的hash function对原始数据集合进行hashing生成一个或多个hash table的过程称为Locality-sensitive Hashing.
二、Simhash 算法
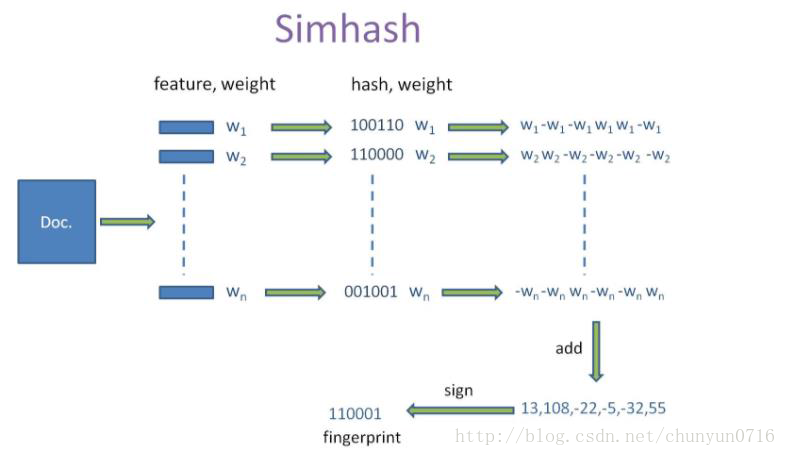
SimHash 算法的输入是一个向量,输出是一个
Simhash 算法如下:
- 将一个
f 维向量v⃗ 初始化为0⃗ ,f 位的二进制数S 初始化为0- 对每一个特征:
用传统的hash算法对该特征产生一个f 位的签名b .
对于i=1tof:
如果 b 的第i 位为1,则v⃗ S 加上该特征的权重
否则, v⃗ 的第i 个元素减去该特征的权重- 如果
v⃗ 的第i 个元素大于0,S 的第i 位为1,否则为0- 输出
S 作为签名
如下图所示:
SimHash是由随机超平面hash算法演变而来的,对于一个
1.随机产生
f 个n 维的向量r⃗ 1,r⃗ 2,…,r⃗ f
2.对每一个向量r⃗ i ,如果v⃗ 与r⃗ i 的点积大于0 ,则最终签名的第i 位为1 ,否则为0
上述算法相当于随机产生了f个n维超平面,每个超平面将v所在的空间一分为二。v在这个超平面上方则得到一个1,否则得到一个0,然后将得到的f个0或1组合起来成为一个f维的签名。
如果两个向量
在simhash中并没有直接产生用于分割空间的随机向量,而是间接产生的:第k个特征的hash签名的第i位拿出来,如果为0,则改为-1,如果为1则不变,作为第i个随机向量的第k维。由于hash签名是f位的,因此这样能产生f个随机向量,对应f个随机超平面。
simhash算法得到的两个签名的汉明距离可以用来衡量原始向量的夹角。这其实是一种降维技术,将高维的向量用较低维度的签名来表征。衡量两个内容相似度,需要计算汉明距离。汉明距离是两个字符串对应位置的不同字符的个数:
1011101 与1001001 之间的汉明距离是2。