Redis其实就是一个用C语言写的一个程序,这个程序用来存储 key-value数据,数据先放在内存,然后写入磁盘指定位置。
这么理解十分肤浅,但tm好像就是这样啊。
下面我们梳理一下Redis存储两种方式: RDB和AOF
第一种方式:RDB(Redis DataBase)
RDB是将数据写入一个临时文件,持久化结束后,用这个临时文件替换上次持久化的文件,达到数据恢复。
在Redis中,默认开启RDB方式进行数据存储,redis.conf中的具体配置参数如下;
#dbfilename:持久化数据存储在本地的文件
dbfilename dump.rdb (dump.rdb为存储的文件名,redis通过io流将内存中的数据,写入该文档)
#dir:持久化数据存储在本地的路径,如果是在/redis/redis-3.0.6/src下启动的redis-cli,则数据会存储在当前src目录下
dir ./

#save时间,以下分别表示更改了1个key时间隔900s进行持久化存储;更改了10个key时间隔300s进行存储;更改10000个key时间隔60s进行存储。
save 900 1
save 300 10
save 60 10000
这里我们可以继续添加,也可以修改参数 比如 save 10 10000 10000个数据时间间隔10s就持久化
使用命令进行持久化save存储:
./redis-cli -h ip -p port save ./redis-cli -h ip 127.0.0.1 -p 6379 save
./redis-cli -h ip -p port bgsave ./redis-cli -h ip 127.0.0.1 -p 6379 bgsave
一个是在前台进行存储,一个是在后台进行存储。我的client就在server这台服务器上,所以不需要连其他机器,直接./redis-cli bgsave.
持久化过程:
当满足save的条件时,比如更改了1个key,900s后会将数据写入临时文件,持久化完成后将临时文件替换旧的dump.rdb。(存储数据的节点是到触发时间时的的节点,也就是对Key有个计数)
使用RDB恢复数据:
自动的持久化数据存储到dump.rdb后。实际只要重启redis服务即可完成(启动redis的server时会从dump.rdb中先同步数据),所以说当我们在关停redis服务的时候,只需要在/redis-3.2.12/src目录下查看是否存在dump.rdb,如果存在,则下次启动redis服务的时候,数据会由redis自动恢复。(如果不存在,那一定是配置文件 redis.conf出了错)
接上篇博客,我的RDB方式配置如下:

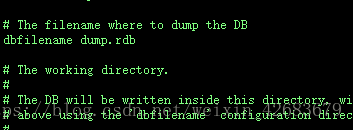

我的RDB 的dump.rdb存放在/var/redis/data目录下面的
第二种方式:AOF(appendonly file)
AOF是将执行过的指令记录下来,数据恢复时按照从前到后的顺序再将指令执行一遍,实现数据恢复。
其中,AOF默认关闭,开启方法,修改配置文件redis.conf:appendonly yes
其他相关配置项:
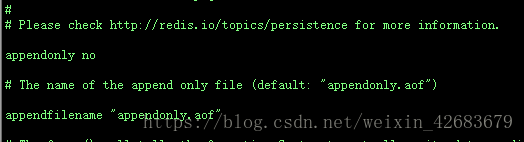
#AOF保存的文件名
appendfilename "appendonly.aof" (将执行的指令记录在appendonly.aof文件中)
以下为同步方式相关的配置:
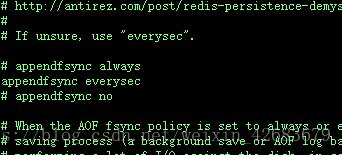
#一旦插入命令,立即同步到磁盘,保证了完全的持久化,但是速度慢,且浪费Redis的性能,不推荐
appendfsync always
#AOF每秒进行同步
appendfsync everysec
#不自动同步,性能最好,但是持久化没有保证
appendfsync no
在此必须说明,fsync是一个命令,在大多数的Linux系统下,每30s就会执行一次fsync,将数据持久化到磁盘,所以这里的appendfsync no其实是交给linux服务器,30s就持久化一次数据;另外,appendfsync everysec 每秒就持久化一次数据,如果数据量在这1s里面非常大呢,redis是持久化不过来的,那么redis就采取的是延迟持久化,会在2s后继续持久化未持久化完成的数据,在appendfsync everysec 每秒持久化的情况下,会造成写阻塞,所以会导致redis存储的数据丢失,这时候就必须采用分布式,让多台redis服务去处理。(由此可以看见,redis存储虽然很强大,但也不是完美无缺的)
存储过程:将快照内容以命令的形式追加到AOF文件中,所以随着追加AOF文件会越来越大
保存的AOF文件存储了执行的所有命令,所以可以进行修改文件来撤销输错的命令(在重写之前,如果重写了就没有办法了)
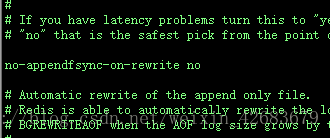
针对AOF文件越来越大的问题,可以对AOF文件进行重写,命令如下:
redis-cli -h ip -p port bgrewriteaof ./redis-cli -h 127.0.0.1 -p 6379 bgrewriteaof
重写命令的操作过程:在当前的快照保存工作结束后,开启一个子进程,将AOF文件进行重写,合并set命令等操作到一个临时文件,达到缩小文件大小的目的。重写结束后后将临时文件替换为新的AOF文件(重写过程中如果有新的redis操作命令,会提交到缓存中,重写结束后追加到AOF文件内)
说明:redis2.4以上版本,重写机制自动触发。触发的相关redis.conf配置如下:
auto-aof-rewrite-percentage 100(当目前的AOF文件大小超过上一次重写文件大小的百分之几时进行重写,如果没有重启过,则以启动时的AOF文件大小为依据);
auto-aof-rewrite-min-size 64mb(允许重写的最小AOF文件大小);
数据恢复:
重启redis服务,前提是配置文件必须设置了appendonly yes,然后会从appendfile的文件加载文件。反之是从RDB中加载数据的。
cluster集群的配置,使用的存储方式就必须是AOF方式。
从appendfile加载数据:我们先来看一下appendfile的内容是什么。下面的一条记录摘取自appendfile:SET $9 olylakers $3 oly。很显,appendfile保存的就是redis server接收到的各种命令,那么从appendfile加载数据就是redis server从appenfile里面读取这些命令的记录,然后重新把这些命令执行一遍即可。需要注意的是,如果开启了VM,那么在从appendfile加载数据的时候可能要涉及swap操作。
从redisdb加载数据:如果没有开启appendonly,那么则需要从db file加载数据到内存,其过程是:
1.通过处理select命令,选择DB
2.然后从db file读取key和value
3.检查key是否过期,如果过期则跳过这个key,如果不过期,则把数据Add到对应的db的dict中
4.如果开启了VM,则从db file中load数据,也可能涉及到swap操作


总结:RDB存储是默认的存储方式,小数量,不在乎是否有并发,数据是否会丢失,安全性最好,占用的空间也最小。AOF方式在分布式下,可应对大量数据处理问题,但也会存在数据丢失。
本来第一次编辑得还可以看,但是Csdn尿性瞬间崩溃了,所以这篇博客,排版啥的几乎没有,望见谅!!!