刚接触python,一段代码中用到:pandas.read_table()函数,这是一个读取一般带分隔符的函数,返回一个DataFrame类型。
一开始代码写成这样:data = pandas.read_table(r'./ml-100k/u.data'),打印出来是这样一些数据:

然后我想设置一些列名,于是这样写: data = pandas.DataFrame(data=data ,columns=['userid','itemid','rating','timestamp']),打印data:

数据直接变成了NaN,一开始一直以为DataFrame是不是用错了,试了各种不同的写法都没用。突然想到read_table读取文件的时候是不是可以直接设置列名的。于是回头又重新看了下read_table函数的官方文档,发现这个函数有一堆参数,简直不忍直视:

大概瞟了一眼参数,发现有个names参数,心想有戏,很有可能就是它设置列名,继续看详细参数说明:

虽然英语水平一般般,但第一句话还是看懂了:用作列名的一个列表。心想八九不离十就是它,有点小激动,立马改代码:
data = pd.read_table(r'./ml-100k/u.data',names=['userid','itemid','rating','timestamp']),打印data:
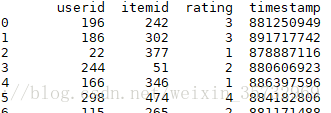
完美,就是这样!