序言
最近在公司做一个数据同步需求的时候,碰到了这样的场景。
客户端从服务器拉取用户账号数据,拿到数据后进行处理并对数据库进行更新操作,最后显示到UI上。
我们知道网络操作一般是异步处理的,在回调中拿到数据并进行处理。为了防止主线程阻塞,数据库的操作往往也会放到子线程中去执行,所以同样需要一个回调来判断数据库操作是否成功,最后由于安卓不允许在子线程中更新 UI,我们还需要将更新 UI 的操作切换到主线程来做。
这样的一个流程涉及到多级事件的回调和线程切换,熟悉响应式编程的人可能会第一时间想到用 RxJava 来实现,再搭配 Retrofit 实现网络部分的操作,简直分分钟搞定。但是考虑到公司的项目所依赖的第三方库并不多,并且这种场景也不是很多,于是最终考虑自己实现一个简易的 RxJava,来完成上述需求。
在实现自己的 RxJava 之前,肯定要提前弄懂 RxJava 的原理。我们不能只会用轮子而不知道怎么造轮子,拆轮子的一个高效的方法就是理解它为什么会被造出来。
项目地址:
https://github.com/CaptainRuby/MyRxJava
目录
1.理解临时任务对象
首先我们要理解一个概念,叫临时任务对象,它是 RxJava 的核心部分。我们将序言中提到的场景简化一下。
场景
- 从服务器拉取用户数据
- 处理数据
- 插入数据库
我们先看同步情况下的操作。
同步
创建一个网络请求的管理类,它实现了一个名为 getData(String param) 的方法,用于从服务器拉取数据,它返回一个 String 类型的列表,其中 param 是需要发送给服务器的参数。
public class HttpManager {
public static List<String> getData(String param) {
/*网络操作*/
return new ArrayList<>();//简化操作,模拟服务器返回的结果
}
}创建一个数据库的操作类,它实现了一个名为 insert(String value) 方法,将用户传入的参数 value 插入数据库。
public class DBHelper {
public static void insert(String value){
/*数据库操作*/
}
}创建一个用户账号的帮助类,实现了一个 process(List<String> data) 方法,将网络拉取的数据列表进行处理,返回一个 String 字符串,供数据库插入。
public class AccountHelper {
private static String process(List<String> data){
return data.get(0);
}
}整个过程的调用操作如下,看起来十分简单,我们再来看下异步情况下的代码。
//Main.java
public static void main(String[] args) {
List<String> data = HttpManager.getData("123");
String value = AccountHelper.process(data);
DBHelper.insert(value);
}异步
修改 HttpManager 类,新增一个回调接口,包含响应和错误的回调,并在 getData() 方法中传入 Callback 参数。
public class HttpManager {
interface Callback{
void onResponse(List<String> data);
void onError(Throwable e);
}
public static void getData(String param,Callback callback){
try {
callback.onResponse(new ArrayList<>());
}catch (Throwable e){
callback.onError(e);
}
}
}修改 DBHelper 类,新增一个回调接口,包含成功和错误的回调,并在 insert() 方法中传入 Callback 参数。
public class DBHelper {
interface Callback{
void onSuccess(int result);
void onError(Throwable e);
}
public static void insert(String value,Callback callback){
try {
callback.onSuccess(1);//返回1表示插入成功
}catch (Throwable e){
callback.onError(e);
}
}
}于是我们的调用是这样的。
//Main.java
public static void main(String[] args) {
HttpManager.getData("123", new HttpManager.Callback() {
@Override
public void onResponse(List<String> data) {
String value = AccountHelper.process(data);//数据处理
DBHelper.insert(value, new DBHelper.Callback() {
@Override
public void onSuccess(int result) {
System.out.println("成功");
}
@Override
public void onError(Throwable e) {
System.out.println("失败");
}
});
}
@Override
public void onError(Throwable e) {
System.out.println("失败");
}
});
}我们发现从同步到异步,代码突然间膨胀了好几行,多了很多大小括号和缩进,一眼看去眼花缭乱,虽然现在只有两个回调嵌套,看起来还不算太糟糕,但是假设再多一两个嵌套,可能阅读起来就不是那么心情愉快了。我们应该思考一下有什么办法可以对其简化。
泛型回调
观察上述代码,我们在修改 HttpManager 和 DBHelper 类的时候,分别定义了两个不同的 Callback 接口,事实上它们之间的差异并不大,只有命名和参数类型不一样,基本都是一个结果和错误的回调,因此我们可以将它们抽象成一个泛型的接口。
public interface Callback<T> {
void onSuccess(T t);
void onError(Throwable e);
}这样我们的代码就变成下面这个样子。
public class HttpManager {
//移除了内部接口,Callback泛型声明为List<String>
public static void getData(String param, Callback<List<String>> callback){
try {
callback.onSuccess(new ArrayList<>());
}catch (Throwable e){
callback.onError(e);
}
}
}public class DBHelper {
//移除了内部接口,Callback泛型声明为Integer
public static void insert(String value,Callback<Integer> callback){
try {
callback.onSuccess(1);
}catch (Throwable e){
callback.onError(e);
}
}
}//Main.java
public static void main(String[] args) {
HttpManager.getData("123", new Callback<List<String>>() {
@Override
public void onSuccess(List<String> data) {
String value = AccountHelper.process(data);
DBHelper.insert(value, new Callback<Integer>() {
@Override
public void onSuccess(Integer result) {
System.out.println("成功");
}
@Override
public void onError(Throwable e) {
System.out.println("失败");
}
});
}
@Override
public void onError(Throwable e) {
System.out.println("失败");
}
});
}现在,我们把回调接口统一改成泛型接口了,减少了多余接口的声明,但是咋一看我们的主函数似乎没什么变化,当然这不是我们最终的优化结果。
临时任务对象
上一步我们观察到接口的方法和参数存在共性可以抽象出相同的模式,事实上我们依旧可以利用这个思路将这些回调做进一步的封装。
可以看到,getData() 和 insert() 方法的共性在于它们都需要接收一个回调参数。
利用这个共性,我们可以使用抽象类的方式将回调参数封装到类内部的一个抽象方法中,我们先来看这种写法有什么巧妙之处。
创建一个名为 AsyncJob 的泛型抽象类,定义一个抽象的 start(Callback<T> callback) 方法,接收一个 Callback 参数。
public abstract class AsyncJob<T> {
public abstract void start(Callback<T> callback);
}正如我们前面定义的 Callback 接口一样,作为一个抽象出来的模板,它看起来非常的简单。接下来我们再看怎么使用它。
我们将 HttpManager.getData() 方法改造成一下。
public class HttpManager {
public static AsyncJob<List<String>> getDataJob(String param){
return new AsyncJob<List<String>>() {
@Override
public void start(Callback<List<String>> callback) {
try {
callback.onSuccess(new ArrayList<>());
}catch (Throwable e){
callback.onError(e);
}
}
};
}
}接收一个 param 请求参数,返回一个 AsyncJob<List<String>> 类型的对象,由于 AsyncJob 是抽象类,所以在实例化的时候必须实现它的 start() 方法,注意看,这个方法包含了我们对数据的处理,并将结果通过传进来的 callback 回调出去。
这是什么意思呢?
这就相当于我们把 getData() 的这一系列操作封装成了一个临时的任务对象,它在内部声明了对数据的处理方式,当你调用 start() 方法时,它便会执行声明的步骤,随后回调执行的结果,而这个结果将由你传进去的 callback 接收。
为什么要这么做呢?
因为按照直观的理解,原本我们希望数据的处理步骤是这样子的。

数据像原料一样在流水线上加工,每经过一台机器(方法),就变成新的半成品,直到最后一台机器,变成我们所需要的产品。
但是前面我们所编写的代码表现出来的却不是这个样子,它们呈现的是一种多级嵌套的形式。我们现在要做的就是将它们拆分出来,所以我们抽象出任务对象的概念。每个任务对象就像流水线上机器,包含了对半成品(上一步的结果)的加工方式。
我们按照同样的方式对 DBHelper.insert() 进行改造,返回一个新的临时任务对象 insertJob 。
public class DBHelper {
public static AsyncJob<Integer> insertJob(String value){
return new AsyncJob<Integer>() {
@Override
public void start(Callback<Integer> callback) {
try {
callback.onSuccess(1);
}catch (Throwable e){
callback.onError(e);
}
}
};
}
}好了,现在我们已经有了 getDataJob() 和 insertJob() 这两台机器(任务)了,我们试着把他们组装一下。
组装任务
在AccountHelper中定义一个 getAndSaveDataJob(String param) 方法,返回一个泛型为 Integer 的临时任务对象。
//AccountHelper.java
private static AsyncJob<Integer> getAndSaveDataJob(String param){
return new AsyncJob<Integer>() {
@Override
public void start(Callback<Integer> callback) {
AsyncJob<List<String>> getDataJob = HttpManager.getDataJob(param);
getDataJob.start(new Callback<List<String>>() {
@Override
public void onSuccess(List<String> data) {
String value = process(data);
AsyncJob<Integer> insertJob = DBHelper.insertJob(value);
insertJob.start(new Callback<Integer>() {
@Override
public void onSuccess(Integer result) {
callback.onSuccess(result);
}
@Override
public void onError(Throwable e) {
callback.onError(e);
}
});
}
@Override
public void onError(Throwable e) {
callback.onError(e);
}
});
}
};
}我们来看 start() 方法内部具体做了什么,生成一个 getDataJob 的临时任务,调用 getDataJob.start() 启动任务后,在 onSuccess() 回调中调用 process(data) 将列表转化为字符串,再生成一个 insertJob 的临时任务,最后调用 insertJob.start() 方法启动任务,将结果回传出去。
咦?这不是和我们前面的逻辑一样吗?还是在做回调嵌套的事情。不要急,我们先看下main方法里面的调用。
//Main.java
public static void main(String[] args) {
AsyncJob<Integer> getAndSaveDataJob = AccountHelper.getAndSaveDataJob("123");
getAndSaveDataJob.start(new Callback<Integer>() {
@Override
public void onSuccess(Integer integer) {
System.out.println("成功");
}
@Override
public void onError(Throwable e) {
System.out.println("失败");
}
});
}相比之前的main函数,我们这里只需要生成一个 getAndSaveDataJob 任务,启动任务并传入回调,简化了一系列操作。
整理下,我们构造了 getDataJob 和 insertJob 这两个任务,并将它们组装成一个新的任务 getAndSaveDataJob ,此时我们的作业流水线图如下。
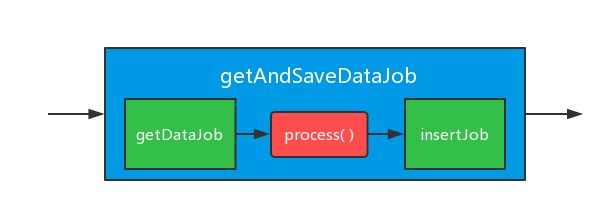
和我们预想的并不一样,没关系,因为到这一步,我们已经初步明确了:
- 任务对象的概念
- 如何组装两个任务
我们接下来要利用这两点对流水线进行重组改装。
改装流水线
为了贴近整个流程顺序执行的思路,我们考虑将 getDataJob 和 process() 方法结合起来,组装一个 processNetDataJob,用来表示一个从网络获取数据并处理的任务。
//AccountHelper.java
public static AsyncJob<String> processNetDataJob(String param){
return new AsyncJob<String>() {
@Override
public void start(Callback<String> callback) {
AsyncJob<List<String>> getDataJob = HttpManager.getDataJob(param);
getDataJob.start(new Callback<List<String>>() {
@Override
public void onSuccess(List<String> data) {
String value = process(data);
callback.onSuccess(value);
}
@Override
public void onError(Throwable e) {
callback.onError(e);
}
});
}
};
}再将这个任务与 DBHelper.insertJob() 组装一下,得到新的 getAndSaveDataJob() 。
//AccountHelper.java
private static AsyncJob<Integer> getAndSaveDataJob(String param){
return new AsyncJob<Integer>() {
@Override
public void start(Callback<Integer> callback) {
AsyncJob<String> processNetDataJob = processNetDataJob(param);
processNetDataJob.start(new Callback<String>() {
@Override
public void onSuccess(String value) {
DBHelper.insert(value).start(new Callback<Integer>() {
@Override
public void onSuccess(Integer result) {
callback.onSuccess(result);
}
@Override
public void onError(Throwable e) {
callback.onError(e);
}
});
}
@Override
public void onError(Throwable e) {
callback.onError(e);
}
});
}
};
}main函数保持不变。
//Main.java
public static void main(String[] args) {
AsyncJob<Integer> getAndSaveDataJob = AccountHelper.getAndSaveDataJob("123");
getAndSaveDataJob.start(new Callback<Integer>() {
@Override
public void onSuccess(Integer integer) {
System.out.println("成功");
}
@Override
public void onError(Throwable e) {
System.out.println("失败");
}
});
}但是流水线的形式已经发生了改变。
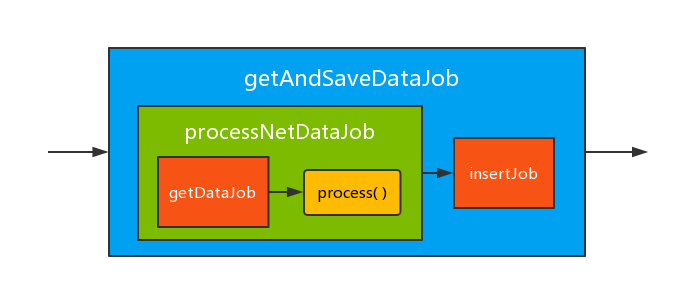
仔细看,我们从最开始的 getDataJob 层层往外套,到最后将其包装成 getAndSaveDataJob,其中每一层都由前后两个任务组装成一个新的任务。
现在你发现了吗?这种临时任务对象的优势就在于,它可以将多个流程的嵌套,拆解成两两嵌套的方式,任由你组装。
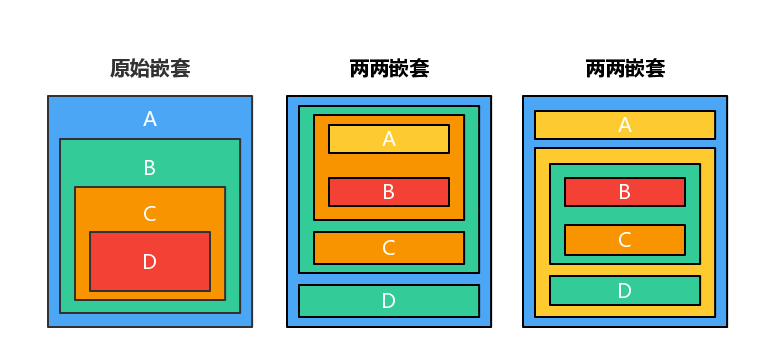
简单的映射
回到前面 processNetDataJob() 这个方法。
//AccountHelper.java
public static AsyncJob<String> processNetDataJob(String param){
return new AsyncJob<String>() {
@Override
public void start(Callback<String> callback) {
AsyncJob<List<String>> getDataJob = HttpManager.getDataJob(param);
getDataJob.start(new Callback<List<String>>() {
@Override
public void onSuccess(List<String> data) {
String value = process(data);
callback.onSuccess(value);
}
@Override
public void onError(Throwable e) {
callback.onError(e);
}
});
}
};
}我们发现它只有下面这一句核心代码,其它都是模板代码。
String value = process(data);这个方法的作用是返回了一个泛型为 String 的任务对象,它其实是由 getDataJob 演变过来的,而 getDataJob 是一个泛型为 List<String> 的任务对象,即它把一个 AsyncJob<List<String>> 的对象转变为一个 AsyncJob<String> 对象。
事实上,我们可以在外部为其定义一个接口,来帮助它实现这种转变。
接口定义如下,声明一个名为 Func 的接口,接收两个泛型参数,接口中包含一个名为 call 的方法,其中 T 为传入的方法参数类型,R 为该方法返回的类型。
public interface Func<T,R> {
R call(T t);
}紧接着,我们在 AsyncJob 类中添加一个 map 方法,主要作用就是实现上述的转化。
//AsyncJob.java
public <R>AsyncJob<R> map(Func<T,R> func){
AsyncJob<T> upstream = this;
return new AsyncJob<R>() {
@Override
public void start(Callback<R> callback) {
upstream.start(new Callback<T>() {
@Override
public void onSuccess(T t) {
R r = func.call(t);
callback.onSuccess(r);
}
@Override
public void onError(Throwable e) {
callback.onError(e);
}
});
}
};
}在这个方法中,我们传入了一个 Func 接口的实现,新建一个引用 upsteam 指向当前实例,并返回一个新的任务对象,在 upsteam 的 onSuccess() 回调中,调用 func.call() 方法,传入回调结果 t,得到 R 类型的值 r,再将该值通过新建任务对象的 onSuccess() 方法回调出去。
现在我们的 processNetDataJob() 方法就变成这样了。
//AccountHelper.java
public static AsyncJob<String> processNetDataJob(String param){
AsyncJob<List<String>> getDataJob = HttpManager.getDataJob(param);
AsyncJob<String> processNetData = getDataJob.map(new Func<List<String>, String>() {
@Override
public String call(List<String> data) {
return process(data);
}
});
return processNetData;
}processNetDataJob 直接由 getDataJob 通过 map() 方法变换得到,处理的逻辑在 call() 中实现。
这就是简单的映射。
好了,说了这么多,我们才刚刚介绍完第一部分。再次强调一下,这个部分的目的就是让你理解临时任务对象的概念,它是 RxJava 的核心思想。我们在这一部分所实现的类和接口,在 RxJava 中都能找到它们的影子。
- AsyncJob<T>,实际上就是 Observable,在 RxJava 中,它不仅可以只分发一个事件也可以是一个事件序列。
- Callback<T>,就是 Observer, 只是少了一个
onComplete( )方法。start(Callback callback)方法,则对应subscribe(Observer observer)方法。
▶ 自己动手造一个 RxJava(一)—— 理解临时任务对象
▷ 自己动手造一个 RxJava(二)—— 事件的发送、接收与映射
▷ 自己动手造一个 RxJava(三)—— 线程调度