1、jaxp的sax解析方式的原理(********)
2、使用jaxp的sax方式解析xml(**会写***)
=======================================
1、jaxp的sax解析方式的原理(********)
* jaxp解析xml有两种技术 dom 和 sax
* dom方式:根据xml的层级结构在内存中分配一个树形结构,把xml中标签,属性,文本封装成对象
* sax方式:事件驱动,边读边解析
* 在javax.xml.parsers包里面
** SAXParser
此类的实例可以从 SAXParserFactory.newSAXParser() 方法获得
- parse(File f, DefaultHandler dh)
* 两个参数
** 第一个参数:xml的路径
** 第二个参数:事件处理器
** SAXParserFactory
实例 newInstance() 方法得到
* 画图分析一下sax执行过程
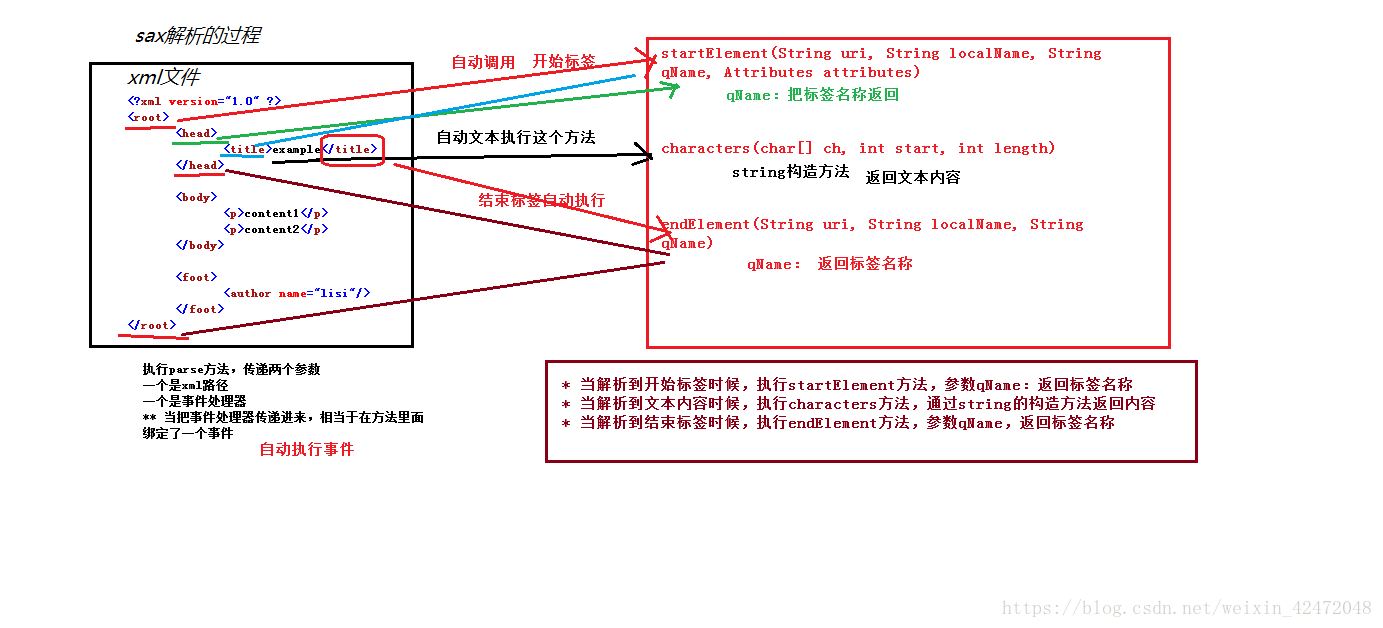
* 当解析到开始标签时候,自动执行 startElement 方法.
* 当解析到文本时候,自动执行 characters 方法.
* 当解析到结束标签时候,自动执行 endElement 方法.
2、使用jaxp的sax方式解析xml(**会写***)
* sax方式不能实现增删改操作,只能做查询操作
** 打印出整个文档
*** 执行parse方法,第一个参数是xml路径,第二个参数是事件处理器.
*** 创建一个类,继承事件处理器的类,重写里面的三个方法
需求一:获取到所有的name元素的值
** 定义一个成员变量 flag= false
** 判断开始方法是否是name元素,如果是name元素,把flag值设置成true
** 如果flag值是true,在characters方法里面打印内容
** 当执行到结束方法时候,把flag值设置成false
需求二:获取第一个name元素的值
** 定义一个成员变量 idx=1
** 在结束方法时候,idx+1 idx++
** 想要打印出第一个name元素的值,
- 在characters方法里面判断,
-- 判断flag=true 并且 idx==1,在打印内容
public class TestSax {
public static void main(String[] args) throws Exception {
/*
* 1、创建解析器工厂
* 2、创建解析器
* 3、执行parse方法
*
* 4、自己创建一个类,继承DefaultHandler
* 5、重写类里面的三个方法
* */
//创建解析器工厂
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
//创建解析器
SAXParser saxParser = saxParserFactory.newSAXParser();
//执行parse方法
saxParser.parse("src/p1.xml", new MyDefault1());
saxParser.parse("src/p1.xml", new MyDefault2());
}
}
//打印xml的内容
class MyDefault1 extends DefaultHandler {
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.print("<"+qName+">");
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.print(new String(ch,start,length));
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.print("</"+qName+">");
}
}
//实现获取所有的name元素的值
class MyDefault2 extends DefaultHandler {
boolean flag = false;
int idx = 1;
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
//判断qName是否是name元素
if("name".equals(qName)) { // flag=true 对应开始标签
flag = true;
}
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
//当flag值是true时候,表示解析到name元素
//索引是1
if(flag == true && idx == 2) {
System.out.println(new String(ch,start,length));
}
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
//把flag设置成false,表示name元素结束
if("name".equals(qName)) { // flag=false 对应结束标签
flag = false;
idx++;
}
}
}
注:SAX解析原理具体介绍:
DOM方式:一行一行的读取XML文档,最终会把XML文档所有数据存放到Document对象中。
SAX方式:也是一行一行的读取XML文档,但是当XML文档读取结束后,SAX不会保存任何数据,同时整个解析XML文档的工作也就结束了。
但是,SAX在读取一行XML文档数据后,就会给感兴趣的用户一个通知!例如当SAX读取到一个元素的开始时,会通知用户当前解析到一个元素的开始标签。
而用户可以在整个解析的过程中完成自己的业务逻辑,当SAX解析结束,不会保存任何XML文档的数据。
优先:使用SAX,不会占用大量内存来保存XML文档数据,效率也高。
缺点:使用SAX,当解析到一个元素时,上一个元素的信息已经丢弃,也就是说没有保存元素与元素之间的结构关系,
这也大大限制了SAX的使用范围。如果只是想查询XML文档中的数据,那么使用SAX是最佳选择!