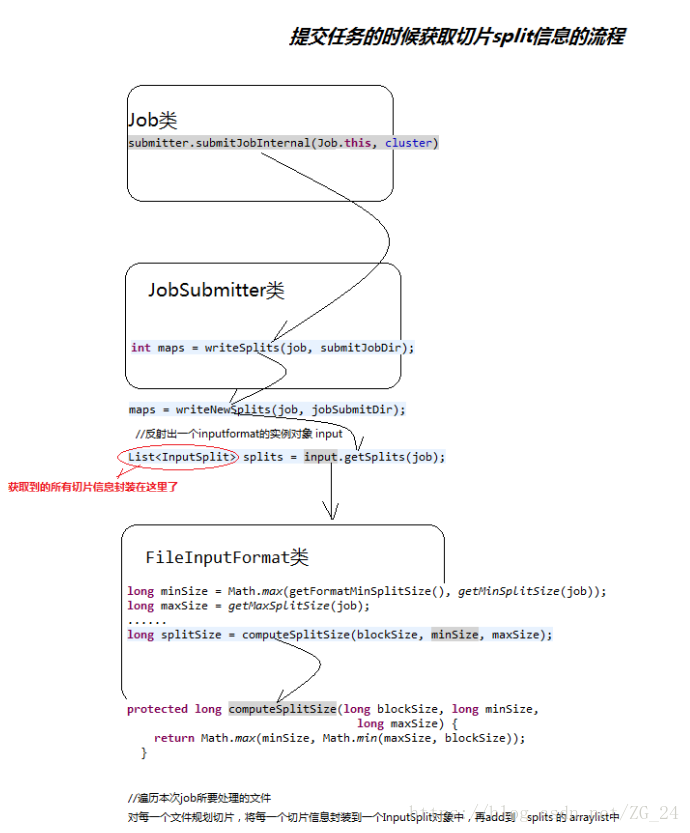
一 MR程序的组件全貌
之前的文章中已经描述过了大部分的组件。目前没有接触过的只剩InputFormat、RecordReaders、OutputFormat。
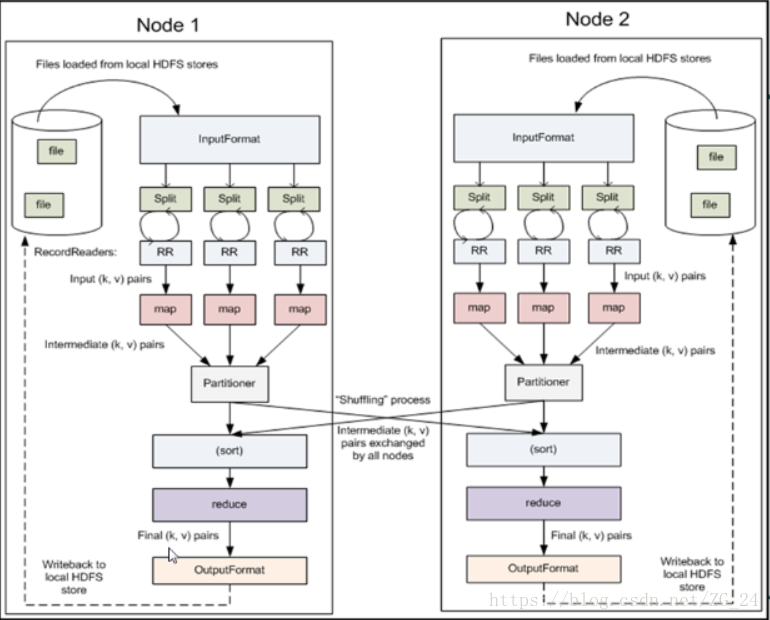
InputFormat和RecordReader
Hadoop提出了InputFormat的概念。
org.apache.hadoop.mapreduce包里的InputFormat抽象类提供了如下列代码所示的两个方法:
public abstract class InputFormat<K, V> {
public abstract List<InputSplit> getSplits(JobContext context);
RecordReader<K, V> createRecordReader(InputSplit split, TaskAttemptContext context);
}这些方法展示了InputFormat类的两个功能:
- 将输入文件切分为map处理所需的split
- 创建RecordReader类, 它将从一个split生成键值对序列
RecordReader类同样也是org.apache.hadoop.mapreduce包里的抽象类。
public abstract class RecordReader<Key, Value> implements Closeable {
public abstract void initialize(InputSplit split, TaskAttemptContext context);
public abstract boolean nextKeyValue() throws IOException, InterruptedException;
public abstract Key getCurrentKey() throws IOException, InterruptedException;
public abstract Value getCurrentValue() throws IOException, InterruptedException;
public abstract float getProgress() throws IOException, InterruptedException;;
public abstract close() throws IOException;
}为每个split创建一个RecordReader实例,该实例调用getNextKeyValue并返回一个布尔值。
组合使用InputFormat和RecordReader可以将任何类型的输入数据转换为MapReduce所需的键值对。
InputFormat和RecordReader
InputFormat
Hadoop内置的输入文件格式类有:

2) TextInputFormat<LongWritable,Text>这个是默认的数据格式类。key代表当前行数据距离文件开始的距离,value代码当前行字符串。
3)SequenceFileInputFormat<K,V>这个是序列文件输入格式,使用序列文件可以提高效率,但是不利于查看结果,建议在过程中使用序列文件,最后展示可以使用可视化输出。
4)KeyValueTextInputFormat<Text,Text>这个是读取以Tab(也即是\t)分隔的数据,每行数据如果以\t分隔,那么使用这个读入,就可以自动把\t前面的当做key,后面的当做value。
5)CombineFileInputFormat<K,V>合并大量小数据是使用。
6)MultipleInputs,多种输入,可以为每个输入指定逻辑处理的Mapper。
RecordReader
Hadoop在org.apache.hadoop.mapreduce.lib.input包里也提供了一些常见的RecordReader实现
- LineRecordReader: 这是RecordReader类对文本文件的默认实现,它将行号时为键并将该行内容视为值。
- SequenceFileRecordReader: 该类从二进制文件SequenceFile读取键值
OutputFormat和RecordWriter
org.apache.hadoop.mapreduce包里的OutputFormat和RecordWriter的子类负责共同写入作业输出。
如果指定的输出路径已经存在,则会导致作业失败,如果想改变这种情况,需要一个重写该方法的OutputFormat子类.
OutputFormat
org.apache.hadoop.mapreduce.output包提供了下列OutputFormat类.
- FileOutputFormat: 这是所有基于文件的OutputFormat的基类
- NullOutputFormat: 这是一个虚拟类,它丢弃所有输出并对文件不做任何写入
- SequenceFileOutputFormat: 它将输出写入二进制SequenceFile
- TextOutputFormat:它把输出写入到普通文本文件
上述类把他们所需的RecordWriter定义为内部类,因此不存在单独实现的RecordWriter类
Sequence files
org.apache.hadoop.io包里的SequenceFile类提供了高效的二进制文件格式,他经常用于MapReduce作业的输出,尤其是当作业的输出被当做另一个作业的输入时.
Sequence文件有如下优点.:
- 作为二进制文件,它们本质上比文本文件更为紧凑
- 他们支持不同层面的可选压缩,也就是说,可以对每条记录或整个split进行压缩
- 该文件可被并行切分处理
二 textinputformat对切片规划的源码分析