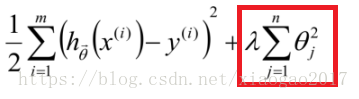目录
五、学习环境的搭建与介绍
略
六-七-八、线性回归模型
1、什么是回归?
有监督学习,因变量y是连续的。
通常我们考虑整体的θ,而无需关心θ0(截距项)。

注意1:回归有个问题:它擅长内推插值,而不擅长外推归纳。
举例:身高和体重得到一个函数h=x-106 于是,假定身高是106,体中计算得到0。这个是不正常的。
于是我们需要明确一点:回归函数是有范围的。在范围区间内,我们的函数是正常的。
注意2:残差
可以先通过判断残差 是否符合高斯分布,来判断能否用线性回归去做
2、θ怎么求?
用最小二乘法求解。OLS:Ordinary Least Square
3、为什么用最小二乘法?
方式一:
(1)X必然存在误差。
误差产生的原因多种多样,就好比量身高,弯个腰,抬个头,都会使得测量不准。
但总体来说,如果模型正确,误差是独立同分布的,服从均值为0,方差为σ2的高斯分布(原理:中心极限定理)。
(2)似然函数
在统计学中,似然函数是一种关于 统计模型参数的函数。
我们想要预测某件事情,怎么预测呢?先找到历史上发生过的事件,提取一些特征X,然后用参数θ组合这些特征X,得到一个函数,用这个函数近似我们的事件。
这样我们就能够得到一个函数,我们称为似然函数。而我们求得这个最大的似然函数,来尽可能的等价于我们的真实值y。
(3)利用误差项+最大似然函数,推导出最小二乘法

方式二:残差平方和

4、OLS又是怎么求得的θ?
前文推导过:y=wTX。其实y还有其他表现形式:
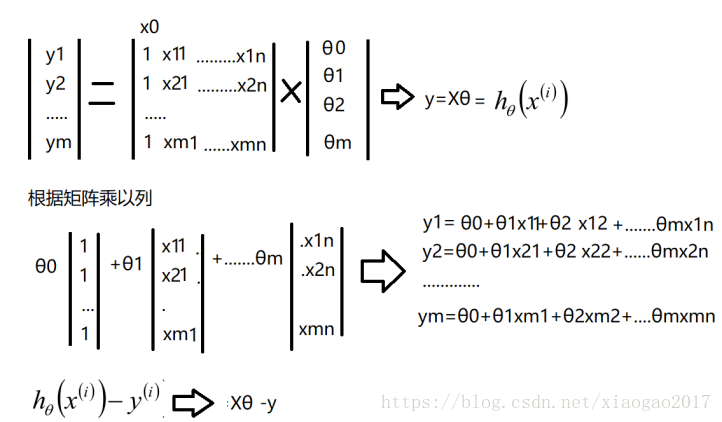
进一步求解
 5、OLS一定可以求得θ吗?
5、OLS一定可以求得θ吗?
(1)只要XTX可逆,那么就一定可以求出θ。
(2)当样本个数 大于 样本维度时,一定可求逆。
但是当样本个数较少时,不可求逆。
(3)如果不可求逆,怎么办?
方案一:加上一个大于0的λ。

方案二:SVD求解、梯度下降算法(sklearn中建议,当样本个数超过10w时,采用梯度下降法)
6、λ的意义?
(1)λ是一个超参数,不像普通参数那样,可以通过训练得到。
一般情况下,超参数都是调出来的。用校验集来验证超参数效果。大致就是:提供一些值,然后用校验集测试,选出一个最好的超参数。
有时,也可以通过计算得到
(2)正如下图所示,λ是起到调节 损失函数和正则项的。下面标记的那部分,称为正则项。