1.重载函数是否能够通过函数返回值的类型不同来区分?
不可以。因为在C++编程中,函数的返回值可以忽略(不使用其返回值),程序中调用此时函数名相同和参数相同的两个函数对编译器和程序员来说是没有办法区分的,编译器会提示出错。
2.C++多态机制的实现
(1)重载:同一个类中同一个函数的不同实现,必须保证函数参数不同(类型,个数,顺序),本质上与多态无关。使用重载函数,编译器会根据函数的名称和参数定义来生成函数的内部标识符,保证每个函数的标识符是唯一的,这样在链接时就可以链接到对应的函数。重载属于静态绑定,在编译过程中就能确定调用哪一个函数,是早期绑定,与多态原理不同。
(2)覆盖:也称为重写,子类中对父类的同名函数同参数的重写,父类的函数必须设置为虚函数,这样保证使用基类指针或者引用指向不同的子类对象可以动态调用属于具体子类的方法而不是调用基类的方法,从而实现多态。
PS:C++中 多态一般默认是指动态多态(通过类继承机制和虚函数机制实现),是在运行时确定的,在面向对象编程中直接被称为多态,而静态多态一般是指使用函数重载或者模板机制实现的。模板也允许将不同的特殊行为和单个泛化记号相关联,由于这种关联处理于编译期而非运行期,因此被称为“静态”。可以用来实现类型安全、运行高效的同质对象集合操作。C++ 的STL库大量使用了模板机制来实现,而并没有使用虚函数机制,属于静态多态。
详情可以参考以下博客:https://blog.csdn.net/sinat_20265495/article/details/50112311
3.队列和栈的共同点以及不同点(C++版本)
队列:这里只说单向队列,就是我们平常所说的FIFO队列,它满足先进先出的规则,即只能在队尾插入元素,提取元素只能在队头。(C++里面提供了queue容器作为单向队列的实现)
栈:栈满足LIFO规则(后进先出),插入和取出操作只能在栈顶进行(C++提供了stack容器作为栈的实现)
相同点:都是线性表结构,并且只能在端点进行数据的插入和读取(受限制的线性表结构),都不能进行随机存取,都不支持遍历(不开临时空间),在C++ stl中可以采用deque作为两者的底层容器;
不同点:栈和队列的操作不同,栈只能在线性表的一端进行插入和删除,而队列则是只能在表的一端进行插入,在另一端进行删除;栈符合LIFO原则,而队列符合FIFO原则,即满足队列的操作原则;
具体可以参考这篇博客:https://blog.csdn.net/zqixiao_09/article/details/51474589
4.模板(函数模板、类模板)
可以参考这篇博客:https://blog.csdn.net/sinat_20265495/article/details/50112311
5.C++内存模型(内存布局)
一般来说,一个C++程序所分配的内存空间主要分为五个部分:堆、栈、静态存储区、代码段
根据C++中类的情况,可以分为以下几种情况进行讨论:
单一类:
(1)空类:占据一个字节,用于标识这个类是一个空类,没有实际含义,使用sizeof操作符可以看到大小为1个字节。

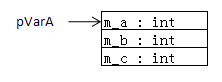
(2)只有成员变量的类:该类的大小为所有普通成员变量所占据的内存大小的和(静态成员变量并不存放在对象的内存空间中),内存布局如下图所示,可以看出在内存中是按照变量声明的顺序存放的。
(3)只有虚函数的类:根据虚函数的实现机制,该类的对象所占据的内存只有一个虚函数表指针(vfptr),指向一个虚函数表,该表按照函数的声明顺序存储着虚函数的函数指针。内存布局如下所示:

从上面我们可以看到,在该类的对象中,只存放一个虚函数表指针,它指向虚函数表,虚函数表并没有存放在对象的内存空间中。该类的对象的大小为虚函数表指针大大小(64位系统为8个字节,32位系统则为4个字节)
(4)既有虚函数,又有成员变量的类
这样的类的对象内存中既有虚函数表指针,又有成员变量(按照声明的顺序存放),内存布局如下图所示: https://blog.csdn.net/it_yuan/article/details/24651347

单继承、多继承的情况则比较复杂,此处不进行详细分析,具体可以自己网上找一下或者参考以下这篇博客: https://blog.csdn.net/it_yuan/article/details/24651347
6.函数调用压栈出栈过程及参数入栈顺序
函数对应的栈其实是栈帧,由系统从系统栈(内存中的栈空间)划分一定大小的空间给函数,函数独占该栈帧,栈帧里面存放着该函数执行时的局部变量 、上一个栈帧的ESP和EBP、函数调用的返回地址(函数的后面的指令的地址),在函数调用过程中涉及了栈帧的分配、切换和释放,不同操作系统、不同语言、不同编译器的实现机制基本相同,但是具体的实现细节有所不同,例如参数压栈出栈的顺序等。具体可以参考以下博客(个人觉得两位大神的分析特别详细):
https://blog.csdn.net/u011555996/article/details/70211315
https://www.cnblogs.com/roy-blog/p/6367093.html
7.C++ inline原理(注意与define的区别和联系)
inline是C++的一种机制,作用于函数,将一个函数声明为inline,可以让编译器在编译代码时,将“对此函数的每一个调用”都以函数本体替换之,该过程发生在编译期间。inline的优点是:它可以省去函数调用所带来的额外开销,提高程序的速度。缺点也很明显:首先,过分使用inline函数会导致代码膨胀,占用过多内存和硬盘空间;其次,在升级inline函数时,需要所有引用它的模块都要重新编译。
综合以上说明,inline一般用于函数体比较小,频繁切换的函数上面。另外需要强调的一点是,千万不要将构造或析构函数inline。原因是,这种函数往往看起来是空的,而实际上在编译期间会生成很多代码,如果将它们inline了,很容易就会导致代码膨胀。
8.define和const的区别
const是定义了一种数据类型,被其修饰的变量会被系统分配内存空间,存放在静态存储区,在编译时会进行类型检查,而define定义的常量本质上是一种宏替换,不是一种数据类型,系统不会为其分配内存空间,宏定义的常量在预处理的时候会被替换,不会进行类型检查。
具体差异可以参考这篇博客:https://blog.csdn.net/yingyujianmo/article/details/51206460
9.虚继承和虚基类表、虚基类表指针
虚继承是为了解决多重继承中派生类对象内存同时存在多份虚基类的实体而提出的,当使用虚继承时,派生类中最多保存一份虚基类的实体,但是需要在内存中增加虚基类表指针。具体可以参考 以下博客:
https://blog.csdn.net/bxw1992/article/details/77726390
10.C++ 11多线程 thread库
C++11标准中新增了对多线程的标准库支持,使多线程程序的开发更加方便,主要是通过thread类来创建、调度、运行线程,并提供了大量多线程操作的API,可以说是服务器端开发的一大神器,具体可以参考这篇博客,讲得很详细,这里就不再赘述。
https://www.cnblogs.com/wangguchangqing/p/6134635.html#autoid-3-0-0