Abstract 摘要
使用大规模数据训练triplet networks对人脸识别具有挑战性。由于可能的triplets数量随着样本数量的增加而爆炸,以前的研究采用在线硬性负面挖掘(OHNM)来处理它。然而,随着identities的数量变得非常大,训练将受到不好的局部最小值(bad local minima)的困扰,因为难以找到有效的hard triplets 。(triplets 、triplet Loss和 hard triplets的解释:https://blog.csdn.net/weixin_40710375/article/details/80738910)为了解决这个问题,在本文中,我们提出了带有子空间学习的triplet网络训练,它将所有identities的空间划分为只包含相似身份的子空间。结合bacth OHNM,hard triplets可以更容易找到。对具有100K身份的大规模MSCeleb-1M挑战的实验表明,所提出的方法可以大大提高性能。 此外,为了处理严重的噪声和大规模的检索问题,我们还在鲁棒噪声消除和高效图像检索方面做了一些努力,它们与子空间学习共同使用,以获得MS-Celeb-1M竞赛中的最新性能(Challenge1中没有外部数据)。
噪声说明:(该明星的图片中包括一些不是她的照片)

1. Introduction 介绍
介绍了三元组的组成和triplet loss的目的。(https://blog.csdn.net/weixin_40710375/article/details/80738910)一个问题是为什么我们需要triplet loss? 实际上,还有一些替代品,如softmax loss,这也很受欢迎。 然而,随着类的数量变得非常大,连接到softmax loss的全连接层也将变得非常大,因此GPU存储器的成本对于通常的batch大小将是难以承受的,而小的batch大小将花费太长时间训练。另一个原因是,如果每个类只有少数样本可用,那么softmax loss的训练很困难,图1显示了它在有100K的身份时对softmax和triplet loss的影响。当每个类别中的样本数量很小时(n = 2),triplet loss性能会更好。

虽然triplet loss优势很明显,但使用它却有一些挑战。一个巨大的挑战是如何利用大规模数据有效地训练triplet模型,例如,100K和1M身份是人脸识别中的常见情况。大规模triplet模型的难点在于可能的三元组的数量是样本数量的立方,而大多数三元组是easy triplet,无法帮助训练。减少搜索空间,一些研究人员将triplet loss转化为softmax损失[5,9,15],而一些研究者提出了在线硬质负反向挖掘(OHNM)[7,10,13]或批量OHNM [4]。 大多数研究集中于小规模的案例,而FaceNet [10]使用了大量的身份(8M),但是它遭受了很长的培训时间(几个月)。
在上述方法中,他们都考虑对所有身份分批次进行采样。人们普遍认为hard triplets可以帮助训练,因为他们可以减少识别相似身份的模糊性,并且这表明这些hard triplets最好来自相似身份。但是,从所有身份抽样并不能保证包含相似身份,因此它将无法生成有效的hard triplets。特别是在100K或1M身份的大规模人脸识别中,采用通常的batch大小采样到相似身份的概率非常小,例如,大小为1800的批量从FaceNet中的8M身份随机采样[10]。
在本文中,我们考虑大规模人脸识别的情况,并提出利用子空间学习训练triplets网络。 其基本思想是为每个身份选一个表示(特征),并对所有身份进行聚类以生成聚类或子空间,其中每个子空间中的身份很相似。 随着batch OHNM迭代应用于每个子空间中,所提出的方法可以容易地生成更有效的hard triplets。 对具有100K身份的大规模MS-Celeb-1M数据集进行评估[2]表明,所提出的方法可以大大提高性能并获得更具有鲁棒性的triplet models。 特别是,我们的单一triplet网络获得了99.48%的LFW [6]准确性,与8M身份的FaceNet 99.63%[10]相比具有竞争性。
使用batch OHNM的子空间学习是我们的主要贡献。 另外,鉴于MS-Celeb1M数据集有噪音,我们还设计了一个噪音消除技巧来清洗训练数据,实验表明它能够处理不同数量的噪音。此外,考虑到清理后训练图像的数量约为5M,我们使用双层分层技巧来精确有效地检索测试图像。结合所提出的triplet网络,我们已经在MSCeleb-1M竞赛中取得了最先进的性能,即Challenge1没有外部数据。random set和hard set的回收率(recall)分别为75%和60.6%,其中75%已达到随机集的上限。
2. Related Work 相关工作
在这一部分,我们介绍一些以前关于如何加速三元网络训练的研究。一个很大的困难是可能的triplets数量与训练样本的数量成正比。为了避免直接搜索整个空间,一些研究人员[5,9,15]将triplets loss转化为一种softmax损失。 Sankaranarayanan等人。 [9]提出将正负对之间的欧几里德距离转换为概率相似度,并使用低维嵌入进行快速检索。与[9]类似,Zhuang et al。 [15]将检索问题转换为二元码的多标签分类问题,通过二元二次算法进行优化以实现更快的检索。为了简化优化,Hoffer等人[5]通过将检索问题转化为2类分类问题,提出了一个类似连体的三元网络。这些方法已经显示出有希望的加速,但是没有考虑到hard triplets,这会导致性能下降。
受分类效率的启发,一些研究[1,7,10,13]综合了分类和hard triplets的优点。 Wang等人[13]使用预训练分类模型来选择离线可能的三联体,但离线选择是固定的,因为分类模型不会被更新。为了实现更快训练和处理变体三联体,Parkhi等人[7]训练更进一步的分类网络微调三重损失。他们使用在线硬否定挖掘(OHNM),其中只有三元组违反边际约束被认为是难以学习的三元组。 Chen等人没有进行只有三重点损失的微调, [1]提出以softmax和三重损失的方式联合训练网络,以保存课间和课内信息,并且他们还在训练中采用OHNM。为了将OHNM应用于大规模数据,Schroff等人建议FaceNet [10]以8M身份训练三元组网络,并且需要几个月才能完成大批量的1800.OHNM的一个限制是三元组在批处理中预定义,这将错过可能的硬阴性样本包含在批次中。
为了充分利用batch,一些研究[4]在batch中在线生成hard triplets。Hermans等人[4]提出了batch OHNM,其中负面样本是根据它们到锚点(anchor)的距离在batch内搜索的,而最接近的样本被认为是候选hard negative samples。通过这种方式,可以很容易地找到更hard的triplets,并且以1500个身份进行个人重新识别时获得最佳性能。 由于其规模较小,采用通常batch大小(128或256)得到相似身份的概率很大。然而,在大规模的情况下,随机抽样得到相似身份将更加困难,因此batch OHNM将失败。本文重点研究如何在大规模人脸识别中找到有效的hard triplets。
3. Method 方法
在这一部分,我们将介绍如何训练具有大规模数据的triplets网络。我们首先回顾了在线hard负例挖掘(Online Hard Negative Mining OHNM)和batch OHNM对triplets网络的训练,然后阐述了如何利用子空间学习改进训练。
设x为图像。类似于FaceNet [10],我们映射样本x到d维embedding with L2-正则化(可参考本篇网络结构部分https://blog.csdn.net/fire_light_/article/details/79592804),如图2(a)所示。并给出了表示f (x) ∈ R^d满足‖f (x)‖^2 = 1.(公式太难打了 原文如下)


3.1. Triplet with OHNM

3.2. Triplet with Batch OHNM
为了充分利用batch,一些研究人员提出batch OHNM [4]来探索更多的负面negative样本。代替在整个图像空间T采样x_i^n,batch OHNM 在batch中找x_i^n,batch OHNM的损失最小化如下:

与方程1不同,x_i^n对应每个锚(anchor)x_i^a的欧氏距离进行选择。在训练中,我们随机采样|B|个不同的身份,同时x_i^a和x_i^p同样在每个身份中随机采样,因此每个x_i^a有2|B|-2个可能的x_i^n(因为x_i^a和x_i^n不能是同一个身份的)。batch OHNM不仅可以找到更难的负例,而且由于x_i^n不再是输入,因此可以用更多的三元组进行训练。类似于FaceNet [10],我们考虑几个接近但不是最近的x_i^n,因为最近的x_i^n有可能是错误标记或者poorly imaged faces,从而导致poor的训练。(FaceNet的做法:如果选择最Hard的三元组会造成局部极值,网络可能无法收敛至最优值。因此google大佬们的做法是在mini-batch中挑选所有的 positive 图像对,因为这样可以使得训练的过程更加稳固。对于Negetive的挑选,大佬们使用了semi-hard的Negetive,也就是满足a到n的距离大于a到p的距离的Negative,而不去选择那些过难的Negetive。
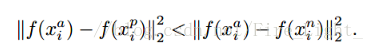
3.3. Triplet with Subspace Learning
hard negative mining的有效性来源于它能够处理识别相似身份的模糊性,这表明hard triplets应该更好地从相似身份中产生。 然而,在OHNM和batch OHNM中,所有身份用于对批次进行随机抽样,这不能保证包含相同的身份。尤其是在大规模身份为100K的情况下,采用128或256等常见batch大小对相似身份进行抽样可能相当困难。为了找到相似身份,其基本思想是找每个身份的表示(特征)并根据表示(特征)进行聚类产生子空间,子空间中的身份是相似的。我们使用分类模型来实现这一点,该分类模型可以在整个训练集的子集上进行预训练。令x_i^c(∀i= 1,...,Nc)是一个具有身份c的图像,Nc是该身份中的图像数量。 然后,由分类模型提取的x_i^c的表示(特征)被表示为g(x_i^c),并且身份表示(特征)g(c)由=定义为:

然后,我们对所有的身份表示(特征) [g (1), ..., g (C)] 应用K-means聚类产生M个子空间,每个子空间表示为Tm (∀m = 1, ..., M),如图2(c)所示的虚线圆圈。
为了加速训练,我们参考[7],它使用预训练分类模型作为初始化。 随着batch OHNM迭代应用于每个子空间,子空间学习的triplets loss可以最小化为

与单个batch OHNM不同。该batch在Tm中以相同身份随机抽样,因此选出的x_i^n更难从而产生更有效的hard 三元组 图2(c)说明了这个过程,其中hard负样本非常接近子空间中的正对(虚线圆圈)。 虽然在特征提取和聚类方面花费了一些时间,但子空间学习可以大大减少搜索空间和训练时间。 特别是,与batch OHNM类似,几个最接近的x_i^n被认为是避免了不良的局部最小值。
3.4. Some Discussions
在子空间学习中,身份表示的选择和子空间的数量非常重要。 在这一部分,我们对它们进行一些讨论。
对于公式3中的g(c)的选择,我们使用该身份中的所有图像表示(特征)的平均值作为身份表示(特征)。由于视点,光照和表情中有很大的变化,平均操作可以消除个体差异并提取身份的共同特征。实际上,g(c)可以被认为是k均值聚类中的一个聚类中心,但是在每个身份中只有一个中心。
对于子空间M的数量,其不能太大或太小,即每个子空间应包含适中数量的身份。 如果M太小,整个图像空间只有一个粗略的划分,因此许多不相同的身份将属于一个子空间,并且找不到足够的三元组。 如果M太大,将会产生许多只包含少数身份的小子空间。如果M太大,将会产生许多只包含少数身份的小子空间。然而,相似性不能保证是有效的,因为身份表示仅由预训练分类模型给出,其不足以可靠地确定 相似。 因此,精细的空间划分会导致过度拟合,这也会导致性能低下。在我们的实验中,我们验证了每个具有约10k身份的子空间是合适的。
4. Cleaning and Retrieval
除了三重网络之外,如何处理噪音数据和大规模检索也是一个具有挑战性的问题。 在这一部分,我们提出两个技巧来处理它们,并在MS-Celeb-1M竞赛中使用这些技巧。 最后,我们给算法流水线做一个简短的总结。
4.1. Noise Removing
在MS-Celeb-1M竞赛的挑战赛中[2],整个数据集中有许多错误标记的图像。 我们观察到,除了一些身份有很多噪声外,大多数身份只有少量嘈杂的面孔。由于干净的数据占主导地位,Sukhbaatar等人 [8]表明,CNN对少量噪声具有鲁棒性。 基于证据,我们提出清理数据的步骤如下:(1)我们使用所有数据来训练初始分类模型; (2)将初始模型用作特征提取器来去除噪声; (3)用干净的数据重新训练新的分类模型。 对于去除步骤,我们采用一种简单的技巧,只保留具有相同预测身份和标签身份的图像。 图3说明了移除的三个步骤。

4.2. Large-Scale Retrieval
尽管清洗后训练样本的数量从8.4M减少到5M,检索样本仍然具有挑战性。假设训练集中有N个样本的C身份。 直接计算所有训练样本的欧几里德距离需要O(N)的复杂度,但这是不可行的,因为N非常大,并且即使使用GPU计算也需要很长时间。 为了有效地检索,我们在身份表示的帮助下提出了两层分层检索。
给定一个测试样本,其基本思想是首先确定其身份,然后将该身份的训练图像用于检索,如图4所示。 以这种方式,复杂度可以被减少到只有O(C + N / C),其中N / C是每个身份的平均样本数。由于有大约100K的身份,即C远小于N。这个分层技巧可以大大加速检索。 与使用预训练分类模型的公式3中的身份表示不同,我们采用triplet network来表示:

4.3. Algorithm Pipeline
作为一个简短的总结,我们在Alg.1中给出了三元组的子空间学习流水线。 流水线主要包含三部分:(1)初始化,也是噪声消除过程; (2)训练,通过子空间学习训练triplet network; (3)测试,这是两层分层检索。
