在Caffe中,blob是对于上层空间的数据管理存储对象,对于上层来说的话,大部分时候是直接取blob对象的指针来用,如果不考虑GPU的情况下,实际上很简单,就是返回指针就行,但是问题是通常的数据是在GPU和CPU上同时存在,需要两个数据在不同的设备上进行同步,那么SyncedMemory的作用是实际上在管理实际数据。对于Blob中,封装的3个SyncedMemory对象的智能指针:
【大的逻辑】
SyncedMemory对象实际管理着数据空间,一个blob可以包含多个SyncedMemory对象的智能指针。SyncedMemory中主要完成数据空间的创建,GPU数据和CPU数据,数据空间的释放,以及GPU和CPU数据的同步。
(1) SyncedMemory与Blob的关联
下面是blob头文件的blob类的成员变量:
protected:
// data_ 为一个SyncedMemory对象指针,实际存放数据空间为对象中的 cpu_ptr_ 指针地址值 和 gpu_ptr_
shared_ptr<SyncedMemory> data_;
shared_ptr<SyncedMemory> diff_; //
shared_ptr<SyncedMemory> shape_data_; //
vector<int> shape_; // 存放shape 信息的vector
// 这里 shape_data_ 与 shape_ 存放的数据一样
int count_; // 存放 有效元素数目的变量
int capacity_; // 存放 Blob 容器的容量信息
实际上对于Blob对象内,使用SyncedMemory对象的地方或者非法,就是访问SyncedMemory对象的cpu和gpu指针。在blob内部,调用SyncedMemory对象的函数方法都是很单一,主要是访问SyncedMemory的内部指针
比如
const Dtype* Blob<Dtype>::cpu_data() const {
CHECK(data_);
return (const Dtype*)data_->cpu_data(); // 返回data_对象的 cpu指针值
}template <typename Dtype>
const Dtype* Blob<Dtype>::gpu_data() const {
CHECK(data_);
return (const Dtype*)data_->gpu_data(); // 返回data_对象的 gpu指针值
} if (count_ > capacity_) { //如果新的count_大于当前已分配空间容量,扩容,重新分配data_和diff_的空间
capacity_ = count_; //
// 这里reset是对这个指针重新赋值,可以发现SyncedMemory的数据空间大小不是随便设置,
// 而是需要多少就严格申请多少
data_.reset(new SyncedMemory(capacity_ * sizeof(Dtype)));
diff_.reset(new SyncedMemory(capacity_ * sizeof(Dtype)));
}这里的new SyncedMemory(并没有开始申请空间),只是设置了head_(UNINITIALIZED)这个标志,在实际访问指针的时候,创建内容空间
(2) SyncedMemory对象内部变量
private:
void to_cpu(); // 数据同步至CPU
void to_gpu(); // 数据同步至GPU
void* cpu_ptr_; // 位于CPU的数据指针
void* gpu_ptr_; // 位于GPU的数据指针
size_t size_; // 存储空间大小
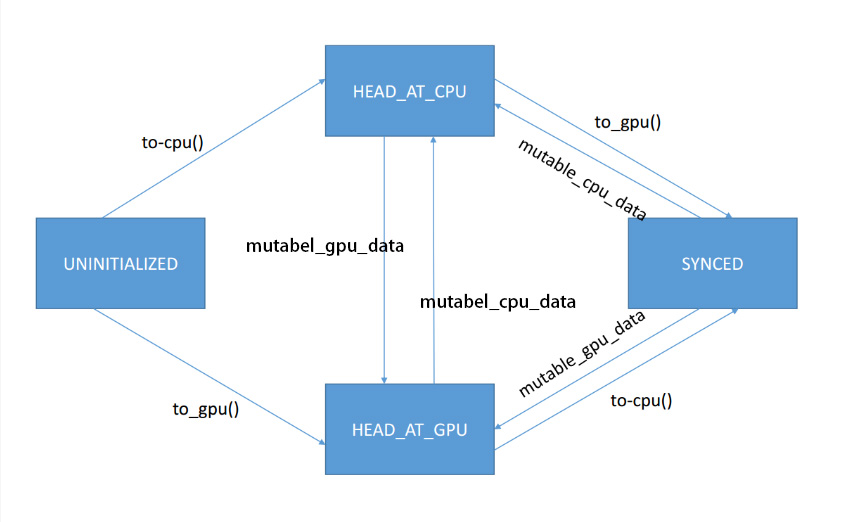
//enum SyncedHead { UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED };
SyncedHead head_; // 状态机变量 ---
//表示SyncedMemory对象所管理的这段内存的同步状态,在CPU,还是GPU,还是CPU和GPU已经同步
// 这里own_cpu_data_和own_gpu_data_不是互斥的关系,可以同时own两个地方的数据
// 这里的own代表的含义是SyncedMemory这个对象是否是真的在管理一段数据空间,
// 有一种可能是SyncedMemory对象所包含的数据指针,是指向的另外一段内存空间,而不由自己申请
bool own_cpu_data_; // 标志是否拥有CPU数据所有权 (否,即从别的对象共享)
bool cpu_malloc_use_cuda_;
bool own_gpu_data_; // 标志是否拥有GPU数据所有权
int gpu_device_; // CPU 设备号
DISABLE_COPY_AND_ASSIGN(SyncedMemory);
}; // class SyncedMemory【细节逻辑】
SyncedMemory对象管理着一个数据对象,数据对象是一个tensor. 这个数据对象可能只存在CPU上,或者只存在GPU上,或者同时存在两个位置上。对于一个数据对象,按道理来说,存储情况会存在几种可能,
(1)只存在CPU上,这时候通过*cpu_ptr_就能访问
(2)只存在CPU上,这时候通过*cpu_ptr_就能访问
(3)需要同时存在CPU和GPU上,那么需要在两个设备上,数据需要同步。希望的效果是两个不同位置的数据是一致的。所谓的同步是指,当一方的数据发生变化时,另外一方的数据需要更新。比如CPU上的数据发生变化,那么需要同步把GPU上的数据更新。这样就涉及到一个何时更新的问题,更新太频繁,比如一方发生变化,就去更新另外一方,这样会导致额外的开销。
那么这时候就会涉及到一个同步管理的问题,实际上对于每个SyncedMemory对象都包含了一个head_变量,标志着目前被管理的数据对象的同步情况
1:head_ 状态机变量介绍,功能
取值是4种可能,UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU, SYNCED,
(1) UNINITIALIZED -- 表示这个数据对象的存储空间没有被初始化,对于这样的情况,需要alloc memory, 分配内存可能会分配在CPU或者GPU上
(2)HEAD_AT_CPU -- 表示的是目前在CPU空间上的数据对象的备份是最新的,或者说,目前CPU上的数据是能够反映当前SyncedMemory所管理数据对象的最新状态,那么对于GPU上的数据备份就不是最新的
(3)HEAD_AT_GPU -- 表示的是目前在GPU空间上的数据对象的备份是最新的,或者说目前GPU上数据是能够反映当前SyncedMemory所管理数据对象的最新状态,那么对于GPU上的数据备份就不是最新的
(4)SYNCED -- 表示的是目前GPU和CPU空间上的数据是同步的,两个位置都能反映当前SyncedMemory所管理数据对象的最新状态
2:下面的问题是这个状态变量是如何改变的状态机变量的值
在SyncedMemory.cpp文件中,改变状态机变量,主要有两个函数,这里的改变是指状态机变量的值发生变化,从一个值变化到另外一个值。
(1) to_cpu() 函数 -
//函数作用是让现在数据最新备份至少出现在cpu上
//函数执行过程中,如果最新的数据在GPU上,那么把GPU的数据同步到CPU上
//这时候CPU和GPU都有最新的同步数据
//返回状态机结果是HEAD_AT_CPU或者SYNCED
//HEAD_AT_CPU -- 代表数据备份最新出现在CPU上, GPU上的数据不是最新的备份
//SYNCED -- 代表CPU和GPU数据都是最新的
//函数作用是让现在数据最新备份至少出现在cpu上
//函数执行过程中,如果最新的数据在GPU上,那么把GPU的数据同步到CPU上
//这时候CPU和GPU都有最新的同步数据
//返回状态机结果是HEAD_AT_CPU或者SYNCED
//HEAD_AT_CPU -- 代表数据备份最新出现在CPU上, GPU上的数据不是最新的备份
//SYNCED -- 代表CPU和GPU数据都是最新的
inline void SyncedMemory::to_cpu() {
switch (head_) {
//如果SyncedMemory对象所对应的这段内存没有被初始化,那么在host上申请内存
case UNINITIALIZED:
CaffeMallocHost(&cpu_ptr_, size_, &cpu_malloc_use_cuda_);
caffe_memset(size_, 0, cpu_ptr_);
head_ = HEAD_AT_CPU;
own_cpu_data_ = true;
break;
case HEAD_AT_GPU: //表示目前数据是在GPU上
#ifndef CPU_ONLY
// 首先在Host上申请这么一段内存,然后把GPU上的数据,同步到CPU上,然后把head状态更新为同步
if (cpu_ptr_ == NULL) {
CaffeMallocHost(&cpu_ptr_, size_, &cpu_malloc_use_cuda_);
own_cpu_data_ = true;
}
caffe_gpu_memcpy(size_, gpu_ptr_, cpu_ptr_);
head_ = SYNCED;// 由于之前在GPU是最新,这个函数和返回以后是把GPU的数据同步在CPU上了
#else
NO_GPU;
#endif
break;
case HEAD_AT_CPU:
case SYNCED:
break;
}
}(2) to_gpu() 函数 -
//函数作用是让现在数据最新备份至少出现在GPU上
//函数执行过程中,如果最新的数据在CPU上,那么把CPU的数据同步到GPU上
//这时候CPU和GPU都有最新的同步数据
//返回状态机结果是HEAD_AT_CPU或者SYNCED
//HEAD_AT_GPU -- 代表数据备份最新出现在CPU上, CPU上的数据不是最新的备份
//SYNCED -- 代表CPU和GPU数据都是最新的
//函数作用是让现在数据最新备份至少出现在GPU上
//函数执行过程中,如果最新的数据在CPU上,那么把CPU的数据同步到GPU上
//这时候CPU和GPU都有最新的同步数据
//返回状态机结果是HEAD_AT_CPU或者SYNCED
//HEAD_AT_GPU -- 代表数据备份最新出现在CPU上, CPU上的数据不是最新的备份
//SYNCED -- 代表CPU和GPU数据都是最新的
inline void SyncedMemory::to_gpu() {
#ifndef CPU_ONLY
switch (head_) {
//如果指针数据没有被分配,那么在GPU上重新分配
case UNINITIALIZED:
CUDA_CHECK(cudaGetDevice(&gpu_device_));
CUDA_CHECK(cudaMalloc(&gpu_ptr_, size_));
caffe_gpu_memset(size_, 0, gpu_ptr_);
head_ = HEAD_AT_GPU;
own_gpu_data_ = true;
break;
//如果目前数据在CPU head上,那么把CPU上的数据,拷贝到GPU上
case HEAD_AT_CPU:
if (gpu_ptr_ == NULL) {
CUDA_CHECK(cudaGetDevice(&gpu_device_));
CUDA_CHECK(cudaMalloc(&gpu_ptr_, size_));
own_gpu_data_ = true;
}
caffe_gpu_memcpy(size_, cpu_ptr_, gpu_ptr_);
head_ = SYNCED;
break;
case HEAD_AT_GPU:
case SYNCED:
break;
}
#else
NO_GPU;
#endif
}3:下面的问题是核心问题,什么时候改变状态机变量的值,即什么时候调用to_cpu, to_gpu函数
答案是在blob对象访问CPU或者GPU数据指针的时候.
下面总结一下调用关系
在上层代码中,调用的是blob的 cpu_data()函数,这个函数返回的数据的实际指针
template <typename Dtype>
void InnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
const Dtype* weight = this->blobs_[0]->cpu_data();而blob的cpu_data()函数如下
template <typename Dtype>
const Dtype* Blob<Dtype>::cpu_data() const {
CHECK(data_);
return (const Dtype*)data_->cpu_data(); // 返回data_对象的 cpu指针值
}又调用的是SyncedMemory对象的cpu_data()函数,而SyncedMemory对象的cpu_data()函数如下
//返回CPU数据指针,并且把
const void* SyncedMemory::cpu_data() {
to_cpu();
return (const void*)cpu_ptr_;
}
最终在这个函数中,返回数据的实际指针,但是在返回之前调用to_cpu()函数。
那么实际blob在管理CPU和GPU时候的逻辑就清楚了,在每次Blob对象调用函数,cpu_data()或者gpu_data()返回数据指针的时候,都是希望被返回的数据指针是能够反映当前tensor的最新状态,访问CPU指针,那么希望CPU上具有tensor数据的最新备份,访问GPU指针,那么希望GPU上有tensor数据的最新备份。而内部的管理是通过SyncedMemory对象的内部状态机来管理。
4:汇总一下状态机改变的函数
这里直接引用别人画的一个图,表示了状态变量,在哪些函数调用中被改变