欢迎访问https://blog.csdn.net/lxt_Lucia~~
宇宙第一小仙女\(^o^)/~~萌量爆表求带飞=≡Σ((( つ^o^)つ~ dalao们点个关注呗~~
摘要
最近学了map,set,auto,decltype,pair,vector等,有点琐碎, 现在放在一起来总结一下,方便理解和以后查找,也方便大家查阅 ~
Come on!!!
Come on!!!
Come on!!!
Map常见用法说明
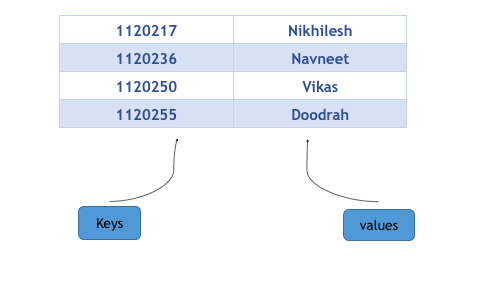
C++中map提供的是一种键值对容器,里面的数据都是成对出现的,如下图:每一对中的第一个值称之为关键字(key),每个关键字只能在map中出现一次;第二个称之为该关键字的对应值。
——————————————————————————————————————————————
一. 声明
#include<map>//头文件
map<int, string> ID_Name;
// 使用{}赋值是从c++11开始的,因此编译器版本过低时会报错,如visual studio 2012
map<int, string> ID_Name =
{
{ 2015, "Jim" },
{ 2016, "Tom" },
{ 2017, "Bob" }
};
——————————————————————————————————————————————
二. 插入操作
2.1 使用[ ]进行单个插入
map<int, string> ID_Name;
// 如果已经存在键值2015,则会作赋值修改操作,如果没有则插入
ID_Name[2015] = "Tom";2.1 使用insert进行单个和多个插入
insert共有4个重载函数:
// 插入单个键值对,并返回插入位置和成功标志,插入位置已经存在值时,插入失败
pair<iterator,bool> insert (const value_type& val);
//在指定位置插入,在不同位置插入效率是不一样的,因为涉及到重排
iterator insert (const_iterator position, const value_type& val);
// 插入多个
void insert (InputIterator first, InputIterator last);
//c++11开始支持,使用列表插入多个
void insert (initializer_list<value_type> il);下面是具体使用示例:
#include <iostream>
#include <map>
int main()
{
std::map<char, int> mymap;
// 插入单个值
mymap.insert(std::pair<char, int>('a', 100));
mymap.insert(std::pair<char, int>('z', 200));
//返回插入位置以及是否插入成功
std::pair<std::map<char, int>::iterator, bool> ret;
ret = mymap.insert(std::pair<char, int>('z', 500));
if (ret.second == false)
{
std::cout << "element 'z' already existed";
std::cout << " with a value of " << ret.first->second << '\n';
}
//指定位置插入
std::map<char, int>::iterator it = mymap.begin();
mymap.insert(it, std::pair<char, int>('b', 300)); //效率更高
mymap.insert(it, std::pair<char, int>('c', 400)); //效率非最高
//范围多值插入
std::map<char, int> anothermap;
anothermap.insert(mymap.begin(), mymap.find('c'));
// 列表形式插入
anothermap.insert({ { 'd', 100 }, {'e', 200} });
return 0;
}
——————————————————————————————————————————————
三. 取值
Map中元素取值主要有at和[ ]两种操作,at会作下标检查,而[]不会。
map<int, string> ID_Name;
//ID_Name中没有关键字2016,使用[]取值会导致插入
//因此,下面语句不会报错,但打印结果为空
cout<<ID_Name[2016].c_str()<<endl;
//使用at会进行关键字检查,因此下面语句会报错
ID_Name.at(2016) = "Bob";
——————————————————————————————————————————————
四. 容量查询
// 查询map是否为空
bool empty();
// 查询map中键值对的数量
size_t size();
// 查询map所能包含的最大键值对数量,和系统和应用库有关。
// 此外,这并不意味着用户一定可以存这么多,很可能还没达到就已经开辟内存失败了
size_t max_size();
// 查询关键字为key的元素的个数,在map里结果非0即1
size_t count( const Key& key ) const; //——————————————————————————————————————————————
五. 迭代器
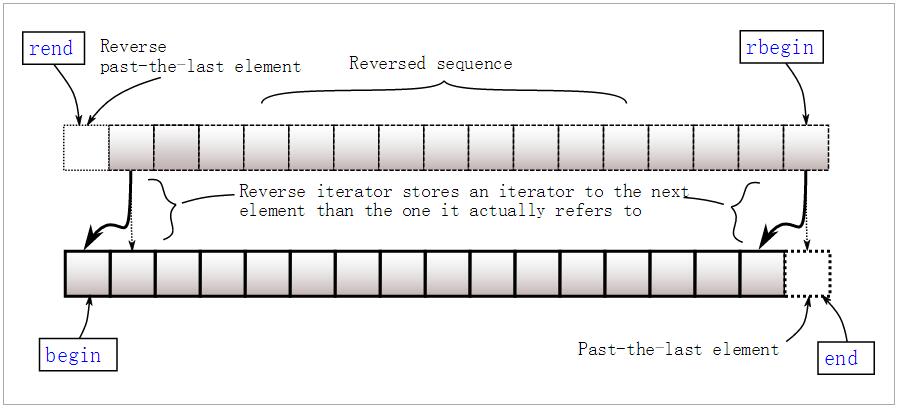
共有八个获取迭代器的函数:* begin, end, rbegin,rend* 以及对应的 * cbegin, cend, crbegin,crend*。
二者的区别在于,后者一定返回 const_iterator,而前者则根据map的类型返回iterator 或者 const_iterator。const情况下,不允许对值进行修改。如下面代码所示:
map<int,int>::iterator it;
map<int,int> mmap;
const map<int,int> const_mmap;
it = mmap.begin(); //iterator
mmap.cbegin(); //const_iterator
const_mmap.begin(); //const_iterator
const_mmap.cbegin(); //const_iterator返回的迭代器可以进行加减操作,此外,如果map为空,则 begin = end。
——————————————————————————————————————————————
六. 删除交换
6.1 删除
// 删除迭代器指向位置的键值对,并返回一个指向下一元素的迭代器
iterator erase( iterator pos )
// 删除一定范围内的元素,并返回一个指向下一元素的迭代器
iterator erase( const_iterator first, const_iterator last );
// 根据Key来进行删除, 返回删除的元素数量,在map里结果非0即1
size_t erase( const key_type& key );
// 清空map,清空后的size为0
void clear();- 6.2 交换
// 就是两个map的内容互换
void swap( map& other );——————————————————————————————————————————————
七. 顺序比较
// 比较两个关键字在map中位置的先后
key_compare key_comp() const;示例:
map<char,int> mymap;
map<char,int>::key_compare mycomp = mymap.key_comp();
mymap['a']=100;
mymap['b']=200;
mycomp('a', 'b'); // a排在b前面,因此返回结果为true
——————————————————————————————————————————————
八. 查找
// 关键字查询,找到则返回指向该关键字的迭代器,否则返回指向end的迭代器
// 根据map的类型,返回的迭代器为 iterator 或者 const_iterator
iterator find (const key_type& k);
const_iterator find (const key_type& k) const;举例:
std::map<char,int> mymap;
std::map<char,int>::iterator it;
mymap['a']=50;
mymap['b']=100;
mymap['c']=150;
mymap['d']=200;
it = mymap.find('b');
if (it != mymap.end())
mymap.erase (it); // b被成功删除
——————————————————————————————————————————————
九. 操作符
operator: == != < <= > >=
注意:对于==运算符, 只有键值对以及顺序完全相等才算成立。
Set常见用法说明
一.关于set
C++ STL 之所以得到广泛的赞誉,也被很多人使用,不只是提供了像vector, string, list等方便的容器,更重要的是STL封装了许多复杂的数据结构算法和大量常用数据结构操作。vector封装数组,list封装了链表,map和set封装了二叉树等,在封装这些数据结构的时候,STL按照程序员的使用习惯,以成员函数方式提供的常用操作,如:插入、排序、删除、查找等。让用户在STL使用过程中,并不会感到陌生。
关于set,必须说明的是set关联式容器。set作为一个容器也是用来存储同一数据类型的数据类型,并且能从一个数据集合中取出数据,在set中每个元素的值都唯一,而且系统能根据元素的值自动进行排序。应该注意的是set中数元素的值不能直接被改变。C++ STL中标准关联容器set, multiset, map, multimap内部采用的就是一种非常高效的平衡检索二叉树:红黑树,也成为RB树(Red-Black Tree)。RB树的统计性能要好于一般平衡二叉树,所以被STL选择作为了关联容器的内部结构。
关于set有下面几个问题:
(1)为何map和set的插入删除效率比用其他序列容器高?
大部分人说,很简单,因为对于关联容器来说,不需要做内存拷贝和内存移动。说对了,确实如此。set容器内所有元素都是以节点的方式来存储,其节点结构和链表差不多,指向父节点和子节点。结构图可能如下:
A
/ \
B C
/ \ / \
D E F G
因此插入的时候只需要稍做变换,把节点的指针指向新的节点就可以了。删除的时候类似,稍做变换后把指向删除节点的指针指向其他节点也OK了。这里的一切操作就是指针换来换去,和内存移动没有关系。
(2)为何每次insert之后,以前保存的iterator不会失效?
iterator这里就相当于指向节点的指针,内存没有变,指向内存的指针怎么会失效呢(当然被删除的那个元素本身已经失效了)。相对于vector来说,每一次删除和插入,指针都有可能失效,调用push_back在尾部插入也是如此。因为为了保证内部数据的连续存放,iterator指向的那块内存在删除和插入过程中可能已经被其他内存覆盖或者内存已经被释放了。即使时push_back的时候,容器内部空间可能不够,需要一块新的更大的内存,只有把以前的内存释放,申请新的更大的内存,复制已有的数据元素到新的内存,最后把需要插入的元素放到最后,那么以前的内存指针自然就不可用了。特别时在和find等算法在一起使用的时候,牢记这个原则:不要使用过期的iterator。
(3)当数据元素增多时,set的插入和搜索速度变化如何?
如果你知道log2的关系你应该就彻底了解这个答案。在set中查找是使用二分查找,也就是说,如果有16个元素,最多需要比较4次就能找到结果,有32个元素,最多比较5次。那么有10000个呢?最多比较的次数为log10000,最多为14次,如果是20000个元素呢?最多不过15次。看见了吧,当数据量增大一倍的时候,搜索次数只不过多了1次,多了1/14的搜索时间而已。你明白这个道理后,就可以安心往里面放入元素了。
——————————————————————————————————————————————
二.set中常用的方法
begin() ,返回set容器的第一个元素
end() ,返回set容器的最后一个元素
clear() ,删除set容器中的所有的元素
empty() ,判断set容器是否为空
max_size() ,返回set容器可能包含的元素最大个数
size() ,返回当前set容器中的元素个数
rbegin ,返回的值和end()相同
rend() ,返回的值和rbegin()相同
写一个程序练一练这几个简单操作吧:
#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> s;
s.insert(1);
s.insert(2);
s.insert(3);
s.insert(1);
cout<<"set 的 size 值为 :"<<s.size()<<endl;
cout<<"set 的 maxsize的值为 :"<<s.max_size()<<endl;
cout<<"set 中的第一个元素是 :"<<*s.begin()<<endl;
cout<<"set 中的最后一个元素是:"<<*s.end()<<endl;
s.clear();
if(s.empty())
cout<<"set 为空 !!!"<<endl;
cout<<"set 的 size 值为 :"<<s.size()<<endl;
cout<<"set 的 maxsize的值为 :"<<s.max_size()<<endl;
return 0;
}
小结:插入3之后虽然插入了一个1,但是我们发现set中最后一个值仍然是3哈,这就是set 。还要注意begin() 和 end()函数是不检查set是否为空的,使用前最好使用empty()检验一下set是否为空.
1)count( ) 用来查找set中某个某个键值出现的次数。这个函数在set并不是很实用,因为一个键值在set只可能出现0或1次,这样就变成了判断某一键值是否在set出现过了。
示例代码:
#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> s;
s.insert(1);
s.insert(2);
s.insert(3);
s.insert(1);
cout<<"set 中 1 出现的次数是 :"<<s.count(1)<<endl;
cout<<"set 中 4 出现的次数是 :"<<s.count(4)<<endl;
return 0;
}
2)equal_range( ) ,返回一对定位器,分别表示第一个大于或等于给定关键值的元素和 第一个大于给定关键值的元素,这个返回值是一个pair类型,如果这一对定位器中哪个返回失败,就会等于end()的值。具体这个有什么用途我还没遇到过~~~
示例代码:
#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> s;
set<int>::iterator iter;
for(int i = 1 ; i <= 5; ++i)
s.insert(i);
for(iter = s.begin() ; iter != s.end() ; ++iter)
cout<<*iter<<" ";
cout<<endl;
pair<set<int>::const_iterator,set<int>::const_iterator> pr;
pr = s.equal_range(3);
cout<<"第一个大于等于 3 的数是 :"<<*pr.first<<endl;
cout<<"第一个大于 3的数是 : "<<*pr.second<<endl;
return 0;
}
3)
erase(iterator) ,删除定位器iterator指向的值
erase(first,second),删除定位器first和second之间的值
erase(key_value),删除键值key_value的值
看看程序吧:
#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> s;
set<int>::const_iterator iter;
set<int>::iterator first;
set<int>::iterator second;
for(int i = 1 ; i <= 10 ; ++i)
s.insert(i);
//第一种删除
s.erase(s.begin());
//第二种删除
first = s.begin();
second = s.begin();
second++;
second++;
s.erase(first,second);
//第三种删除
s.erase(8);
cout<<"删除后 set 中元素是 :";
for(iter = s.begin() ; iter != s.end() ; ++iter)
cout<<*iter<<" ";
cout<<endl;
return 0;
}
小结:set中的删除操作是不进行任何的错误检查的,比如定位器的是否合法等等,所以用的时候自己一定要注意。
4)find( ) ,返回给定值值得定位器,如果没找到则返回end()。
示例代码:
#include<iostream>
#include<set>
using namespace std;
int main()
{
int a[] = {1,2,3};
set<int> s(a,a+3);
set<int>::iterator iter;
if((iter = s.find(2)) != s.end())
cout<<*iter<<endl;
return 0;
}
5)
insert(key_value); 将key_value插入到set中 ,返回值是pair<set<int>::iterator,bool>,bool标志着插入是否成功,而iterator代表插入的位置,若key_value已经在set中,则iterator表示的key_value在set中的位置。
inset(first,second);将定位器first到second之间的元素插入到set中,返回值是void.
示例代码:
#include<iostream>
#include<set>
using namespace std;
int main()
{
int a[] = {1,2,3};
set<int> s;
set<int>::iterator iter;
s.insert(a,a+3);
for(iter = s.begin() ; iter != s.end() ; ++iter)
cout<<*iter<<" ";
cout<<endl;
pair<set<int>::iterator,bool> pr;
pr = s.insert(5);
if(pr.second)
{
cout<<*pr.first<<endl;
}
return 0;
}
6)
lower_bound(key_value) ,返回第一个大于等于key_value的定位器
upper_bound(key_value),返回最后一个大于等于key_value的定位器
示例代码:
#include<iostream>
#include<set>
using namespace std;
int main()
{
set<int> s;
s.insert(1);
s.insert(3);
s.insert(4);
cout<<*s.lower_bound(2)<<endl;
cout<<*s.lower_bound(3)<<endl;
cout<<*s.upper_bound(3)<<endl;
return 0;
}
——————————————————————————————————————————————
三.自定义比较函数
(1)元素不是结构体:
例:
//自定义比较函数myComp,重载“()”操作符
struct myComp
{
bool operator()(const your_type &a,const your_type &b)
{
return a.data-b.data>0;
}
}
set<int,myComp>s;
......
set<int,myComp>::iterator it;
(2)元素是结构体:
可以直接将比较函数写在结构体内。
例:
struct Info
{
string name;
float score;
//重载“<”操作符,自定义排序规则
bool operator < (const Info &a) const
{
//按score从大到小排列
return a.score<score;
}
}
set<Info> s;
......
set<Info>::iterator it;
Auto常见用法说明
一.用法理解
C++11引入了一些新的实用的类型推导能力,这意味着你可以花费更少的时间去写那些编译器已经知道的东西。当然有些时候你需要帮助编译器或者你的编程伙伴。但是C++11,你可以在一些乏味的东西上花更少的时间,而多去关注逻辑本身。
在C++11中,如果编译器在定义一个变量的时候可以推断出变量的类型,不用写变量的类型,你只需写auto即可。
过去咱们往往先写成:
int x = 4;现在可以这样写:
auto x = 4;这当然不是auto预期的用途!它会在模板和迭代器的配合使用中闪耀光芒:
vector<int> vec;
auto itr = vec.iterator();其它时候auto也会非常有用。比如,你有一些下面格式的代码:
template <typename BuiltType, typename Builder>
void
makeAndProcessObject (const Builder& builder)
{
BuiltType val = builder.makeObject();
// do stuff with val
}上面的代码,我们看到这里需要两个模板参数:一个是Builder对象的类型,另一个是Builder创建出的对象的类型。糟糕的是创建出的类型无法被推导出,所以每次你必须这样调用:
MyObjBuilder builder;
makeAndProcessObject<MyObj>( builder );
但是auto立即将丑陋的代码一扫无余,当Builder创建对象时不用写特殊代码了,你可以让C++帮你做:
template <typename Builder>
void
makeAndProcessObject (const Builder& builder)
{
auto val = builder.makeObject();
// do stuff with val
}现在你仅需一个模板参数,而且这个参数可以在函数调用的时候轻松推导:
MyObjBuilder builder;
makeAndProcessObject( builder );这样更易调用了,并且没丢失可读性,却更清晰了。
——————————————————————————————————————————————
二.引用、指针和常量
下面要确定的一个问题是auto如何处理引用:
int& foo();
auto bar = foo(); // int& or int?答案是在C++11中,auto处理引用时默认是值类型,所以下面的代码bar是int。不过你可以指定&作为修饰符强制它作为引用:
int& foo();
auto bar = foo(); // int
auto& baz = foo(); // int&不过,假如你有一个指针auto则自动获取指针类型:
int* foo();
auto p_bar = foo(); // int*但是你也可以显式指定表明变量是一个指针:
int* foo();
auto *p_baz = foo(); // int*当处理引用时,你一样可以标记const,如果需要的话:
int& foo();
const auto& baz = foo(); // const int&或者指针:
int* foo();
const int* const_foo();
const auto* p_bar = foo(); // const int*
auto p_bar = const_foo(); // const int*所有这些都很自然,并且这遵循C++模板中类型推导的规则。
decltype常见用法说明
现在你可能会说auto就这样吗,假如我想返回Builder创建的对象怎么办?我还是需要提供一个模板参数作为返回值的类型。好!这充分证明了标准委员有一群聪明的家伙,对这个问题他们早想好了一个完美的解决方案。这个方案由两部分组成:decltype和新的返回值语法。
——————————————————————————————————————————————
一.新的返回值语法
讲一下新的返回值语法,该语法还能看到auto的另一个用处。在以前版本的C和C++中,返回值的类型必须写在函数的前面:
int multiply(int x, int y);在C++11中,你可以把返回类型放在函数声明的后面,用auto代替前面的返回类型,像这样:
auto multiply(int x, int y) -> int;但是为什么我要这样用?让我们看一个证明这个语法好处的例子。一个包含枚举的类:
class Person
{
public:
enum PersonType { ADULT, CHILD, SENIOR };
void setPersonType (PersonType person_type);
PersonType getPersonType ();
private:
PersonType _person_type;
};我们写了一个简单的类,里面有一个类型PersonType表明Person是小孩、成人和老人。不做特殊考虑,我们定义这些成员方法时会发生什么? 第一个设置方法,很简单,你可以使用枚举类型PersonType而不会有错误:
void Person::setPersonType (PersonType person_type)
{
_person_type = person_type;
}而第二个方法却是一团糟。简单的代码却编译不过:
// 编译器不知道PersonType是什么,因为PersonType会在Person类之外使用
PersonType Person::getPersonType ()
{
return _person_type;
}你必须要这样写,才能使返回值正常工作:
Person::PersonType Person::getPersonType ()
{
return _person_type;
}这可能不算大问题,不过会容易出错,尤其是牵连进模板的时候。
这就是新的返回值语法引进的原因。因为函数的返回值出现在函数的最后,而不是前面,你不需要补全类作用域。当编译器解析到返回值的时候,它已经知道返回值属于Person类,所以它也知道PersonType是什么。
auto Person::getPersonType () -> PersonType
{
return _person_type;
}好,这确实不错,但它真的能帮助我们什么吗?我们还不能使用新的返回值语法去解决我们之前的问题,我们能吗?不能,让我们介绍新的概念:decltype。
——————————————————————————————————————————————
二.decltype
decltype是auto的反面兄弟。auto让你声明了一个指定类型的变量,decltype让你从一个变量(或表达式)中得到类型。我说的是什么?
int x = 3;
decltype(x) y = x; // 相当于 auto y = x;可以对基本上任何类型使用decltype,包括函数的返回值。嗯,听起来像个熟悉的问题,假如我们这样写:
decltype( builder.makeObject() )我们将得到makeObject的返回值类型,这能让我们指定makeAndProcessObject的返回类型。我们可以整合进新的返回值语法:
template <typename Builder>
auto
makeAndProcessObject (const Builder& builder) -> decltype( builder.makeObject() )
{
auto val = builder.makeObject();
// do stuff with val
return val;
}这仅适用于新的返回值语法,因为旧的语法下,我们在声明函数返回值的时候无法引用函数参数,而新语法,所有的参数都是可访问的。
Pair常见用法说明
一.说明:
1)类模板:template <class T1, class T2> struct pair
2)参数:class T1是第一个值的数据类型,class T2是第二个值的数据类型。
3)功能:pair将一对值(可以是不同的数据类型)组合成一个值,两个值可以分别用pair的两个公有函数first和second访问。
——————————————————————————————————————————————
二.具体用法:
1.定义(构造):
pair<int, double> p1; //使用默认构造函数
pair<int, double> p2(1, 2.4); //用给定值初始化
pair<int, double> p3(p2); //拷贝构造函数
2.访问两个元素(通过first和second):
pair<int, double> p1; //使用默认构造函数
p1.first = 1;
p1.second = 2.5;
cout << p1.first << ' ' << p1.second << endl;
输出结果:1 2.5
3.赋值:
(1)利用make_pair:
pair<int, double> p1;
p1 = make_pair(1, 1.2);
(2)变量间赋值:
pair<int, double> p1(1, 1.2);
pair<int, double> p2 = p1;
(3)生成新的pair对象:
可以使用make_pair对已存在的两个数据构造一个新的pair类型:
int a = 8;
string m = "James";
pair<int, string> newone;
newone = make_pair(a, m);
注意:使用关于pair函数中的字符串时,定义字符串用string a;a时字符串的名称。Vector常见用法说明
一、什么是vector
向量(Vector)是一个封装了动态大小数组的顺序容器(Sequence container)。跟任意其它类型容器一样,它能够存放各种类型的对象。可以简单的认为,向量是一个能够存放任意类型的动态数组。
——————————————————————————————————————————————
二、容器特性
1.顺序序列
顺序容器中的元素按照严格的线性顺序排序。可以通过元素在序列中的位置访问对应的元素。
2.动态数组
支持对序列中的任意元素进行快速直接访问,甚至可以通过指针算述进行该操作。操供了在序列末尾相对快速地添加/删除元素的操作。
3.能够感知内存分配器的(Allocator-aware)
容器使用一个内存分配器对象来动态地处理它的存储需求。
——————————————————————————————————————————————
三、基本函数实现
1.构造函数
- vector():创建一个空vector
- vector(int nSize):创建一个vector,元素个数为nSize
- vector(int nSize,const t& t):创建一个vector,元素个数为nSize,且值均为t
- vector(const vector&):复制构造函数
- vector(begin,end):复制[begin,end)区间内另一个数组的元素到vector中
2.增加函数
- void push_back(const T& x):向量尾部增加一个元素X
- iterator insert(iterator it,const T& x):向量中迭代器指向元素前增加一个元素x
- iterator insert(iterator it,int n,const T& x):向量中迭代器指向元素前增加n个相同的元素x
- iterator insert(iterator it,const_iterator first,const_iterator last):向量中迭代器指向元素前插入另一个相同类型向量的[first,last)间的数据
3.删除函数
- iterator erase(iterator it):删除向量中迭代器指向元素
- iterator erase(iterator first,iterator last):删除向量中[first,last)中元素
- void pop_back():删除向量中最后一个元素
- void clear():清空向量中所有元素
4.遍历函数
- reference at(int pos):返回pos位置元素的引用
- reference front():返回首元素的引用
- reference back():返回尾元素的引用
- iterator begin():返回向量头指针,指向第一个元素
- iterator end():返回向量尾指针,指向向量最后一个元素的下一个位置
- reverse_iterator rbegin():反向迭代器,指向最后一个元素
- reverse_iterator rend():反向迭代器,指向第一个元素之前的位置
5.判断函数
- bool empty() const:判断向量是否为空,若为空,则向量中无元素
6.大小函数
- int size() const:返回向量中元素的个数
- int capacity() const:返回当前向量张红所能容纳的最大元素值
- int max_size() const:返回最大可允许的vector元素数量值
7.其他函数
- void swap(vector&):交换两个同类型向量的数据
- void assign(int n,const T& x):设置向量中第n个元素的值为x
- void assign(const_iterator first,const_iterator last):向量中[first,last)中元素设置成当前向量元素
8.看着清楚
01)push_back 在数组的最后添加一个数据
02)pop_back 去掉数组的最后一个数据
03)at 得到编号位置的数据
04)begin 得到数组头的指针
05)end 得到数组的最后一个单元+1的指针
06)front 得到数组头的引用
07)back 得到数组的最后一个单元的引用
08)max_size 得到vector最大可以是多大
09)capacity 当前vector分配的大小
10)size 当前使用数据的大小
11)resize 改变当前使用数据的大小,如果它比当前使用的大,者填充默认值
12)reserve 改变当前vecotr所分配空间的大小
13)erase 删除指针指向的数据项
14)clear 清空当前的vector
15)rbegin 将vector反转后的开始指针返回(其实就是原来的end-1)
16)rend 将vector反转构的结束指针返回(其实就是原来的begin-1)
17)empty 判断vector是否为空
18)swap 与另一个vector交换数据
——————————————————————————————————————————————
四、头文件
#include < vector>
using namespace std;
——————————————————————————————————————————————
五、简单介绍
- Vector<类型>标识符
- Vector<类型>标识符(最大容量)
- Vector<类型>标识符(最大容量,初始所有值)
- Int i[5]={1,2,3,4,5}
Vector<类型>vi(I,i+2);//得到i索引值为3以后的值 - Vector< vector< int> >v; 二维向量//这里最外的<>要有空格。否则在比较旧的编译器下无法通过
——————————————————————————————————————————————
六.使用总结
1.vector的初始化:
可以有五种方式,举例说明如下:
(1) vector<int> a(10); //定义了10个整型元素的向量(尖括号中为元素类型名,它可以是任何合法的数据类型),但没有给出初值,其值是不确定的。
(2)vector<int>a(10,1); //定义了10个整型元素的向量,且给出每个元素的初值为1
(3)vector<int>a(b); //用b向量来创建a向量,整体复制性赋值
(4)vector<int>a(b.begin(),b.begin+3); //定义了a值为b中第0个到第2个(共3个)元素
(5)intb[7]={1,2,3,4,5,9,8};vector<int> a(b,b+7); //从数组中获得初值
2.vector对象的几个重要操作:
举例说明如下:
(1)a.assign(b.begin(), b.begin()+3);//b为向量,将b的0~2个元素构成的向量赋给a
(2)a.assign(4,2);//是a只含4个元素,且每个元素为2
(3)a.back();//返回a的最后一个元素
(4)a.front();//返回a的第一个元素
(5)a[i]; //返回a的第i个元素,当且仅当a[i]存在2013-12-07
(6)a.clear();//清空a中的元素
(7)a.empty();//判断a是否为空,空则返回ture,不空则返回false
(8)a.pop_back();//删除a向量的最后一个元素
(9)a.erase(a.begin()+1,a.begin()+3);//删除a中第1个(从第0个算起)到第2个元素,也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+3(不包括它)
(10)a.push_back(5);//在a的最后一个向量后插入一个元素,其值为5
(11)a.insert(a.begin()+1,5);//在a的第1个元素(从第0个算起)的位置插入数值5,如a为1,2,3,4,插入元素后为1,5,2,3,4
(12)a.insert(a.begin()+1,3,5);//在a的第1个元素(从第0个算起)的位置插入3个数,其值都为5
(13)a.insert(a.begin()+1,b+3,b+6);//b为数组,在a的第1个元素(从第0个算起)的位置插入b的第3个元素到第5个元素(不包括b+6),如b为1,2,3,4,5,9,8,插入元素后为1,4,5,9,2,3,4,5,9,8
(14)a.size();//返回a中元素的个数;
(15)a.capacity();//返回a在内存中总共可以容纳的元素个数
(16)a.rezize(10);//将a的现有元素个数调至10个,多则删,少则补,其值随机
(17)a.rezize(10,2);//将a的现有元素个数调至10个,多则删,少则补,其值为2
(18)a.reserve(100);//将a的容量(capacity)扩充至100,也就是说现在测试a.capacity();的时候返回值是100.这种操作只有在需要给a添加大量数据的时候才 显得有意义,因为这将避免内存多次容量扩充操作(当a的容量不足时电脑会自动扩容,当然这必然降低性能)
(19)a.swap(b);//b为向量,将a中的元素和b中的元素进行整体性交换
(20)a==b; //b为向量,向量的比较操作还有!=,>=,<=,>,<
3.顺序访问vector的几种方式:
举例说明如下:
1.向向量a中添加元素:
1)直接向向量a中添加元素
vector<int> a;
for(int i=0;i<10;i++)
a.push_back(i);
2)也可以从数组中选择元素向向量中添加
int a[6]={1,2,3,4,5,6};
vector<int> b;
for(int i=1;i<=4;i++)
b.push_back(a[i]);
3)也可以从现有向量中选择元素向向量中添加
int a[6]={1,2,3,4,5,6};
vector<int> b;
vector<int> c(a,a+4);
for(vector<int>::iterator it=c.begin();it<c.end();it++)
b.push_back(*it);
4)也可以从文件中读取元素向向量中添加
ifstream in("data.txt");
vector<int> a;
for(int i; in>>i)
a.push_back(i);
5)易犯错误
vector<int> a;
for(int i=0;i<10;i++)
a[i]=i;
//这种做法以及类似的做法都是错误的。下标只能用于获取已存在的元素,而现在的a[i]还是空的对象
2.从向量中读取元素:
1)通过下标方式读取
int a[6]={1,2,3,4,5,6};
vector<int> b(a,a+4);
for(int i=0;i<=b.size()-1;i++)
cout<<b[i]<<" ";
2)通过遍历器方式读取
int a[6]={1,2,3,4,5,6};
vector<int> b(a,a+4);
for(vector<int>::iterator it=b.begin();it!=b.end();it++)
cout<<*it<<" ";
——————————————————————————————————————————————
七.实例来咯~
1.pop_back()&push_back(elem)实例在容器最后移除和插入数据:
#include <string.h>
#include <vector>
#include <iostream>
using namespace std;
int main()
{
vector<int>obj(10,0);//最大容器为10,都初始化为0
for(int i=0;i<10;i++)//push_back(elem)在数组最后添加数据
{
obj.push_back(i);
cout<<obj[i]<<",";
}
for(int i=0;i<5;i++)//去掉数组最后一个数据
{
obj.pop_back();
}
cout<<"\n"<<endl;
for(int i=0;i<obj.size();i++)//size()容器中实际数据个数
{
cout<<obj[i]<<",";
}
return 0;
}
2.clear()清除容器中所以数据:
#include <string.h>
#include <vector>
#include <iostream>
using namespace std;
int main()
{
vector<int>obj;
for(int i=0;i<10;i++)//push_back(elem)在数组最后添加数据
{
obj.push_back(i);
cout<<obj[i]<<",";
}
obj.clear();//清除容器中所以数据
for(int i=0;i<obj.size();i++)
{
cout<<obj[i]<<endl;
}
return 0;
}
3.排序:
#include <string.h>
#include <vector>
#include <iostream>
#include <algorithm>
using namespace std;
int main()
{
vector<int>obj;
obj.push_back(1);
obj.push_back(3);
obj.push_back(0);
sort(obj.begin(),obj.end());//从小到大
cout<<"从小到大:"<<endl;
for(int i=0;i<obj.size();i++)
{
cout<<obj[i]<<",";
}
cout<<"\n"<<endl;
cout<<"从大到小:"<<endl;
reverse(obj.begin(),obj.end());//从大到小
for(int i=0;i<obj.size();i++)
{
cout<<obj[i]<<",";
}
return 0;
}
1)注意sort需要头文件#include < algorithm>
2)如果想sort来降序,可重写sort
bool compare(int a,int b)
{
return a< b; //升序排列,如果改为return a>b,则为降序
}
int a[20]={2,4,1,23,5,76,0,43,24,65},i;
for(i=0;i<20;i++)
cout<< a[i]<< endl;
sort(a,a+20,compare);4.访问(直接数组访问&迭代器访问)
#include <string.h>
#include <vector>
#include <iostream>
#include <algorithm>
using namespace std;
int main()
{
//顺序访问
vector<int>obj;
for(int i=0;i<10;i++)
{
obj.push_back(i);
}
cout<<"直接利用数组:";
for(int i=0;i<10;i++)//方法一
{
cout<<obj[i]<<" ";
}
cout<<endl;
cout<<"利用迭代器:" ;
//方法二,使用迭代器将容器中数据输出
vector<int>::iterator it;//声明一个迭代器,来访问vector容器,作用:遍历或者指向vector容器的元素
for(it=obj.begin();it!=obj.end();it++)
{
cout<<*it<<" ";
}
return 0;
}
5.二维数组两种定义方法(结果一样)
#include <string.h>
#include <vector>
#include <iostream>
#include <algorithm>
using namespace std;
int main()
{
int N=5, M=6;
vector<vector<int> > obj(N); //定义二维动态数组大小5行
for(int i =0; i< obj.size(); i++)//动态二维数组为5行6列,值全为0
{
obj[i].resize(M);
}
for(int i=0; i< obj.size(); i++)//输出二维动态数组
{
for(int j=0;j<obj[i].size();j++)
{
cout<<obj[i][j]<<" ";
}
cout<<"\n";
}
return 0;
}#include <string.h>
#include <vector>
#include <iostream>
#include <algorithm>
using namespace std;
int main()
{
int N=5, M=6;
vector<vector<int> > obj(N, vector<int>(M)); //定义二维动态数组5行6列
for(int i=0; i< obj.size(); i++)//输出二维动态数组
{
for(int j=0;j<obj[i].size();j++)
{
cout<<obj[i][j]<<" ";
}
cout<<"\n";
}
return 0;
}
string常见用法说明
#include<iostream>
#include"string"
#include"algorithm"
using namespace std;
//string的赋值
void f1()
{
string s1 ="shihao"; //string是一个类
string s2 ("bbbbbb");
string s3 = s1;
string s4(10, 'a'); //等价于string s4 ="aaaaaaaaaa";
cout << s1 << endl;
cout << s2 << endl;
cout << s3 << endl;
cout << s4 << endl;
}
//string的遍历
void f2()
{
string s1 = "abcdefg";
//1:数组方式
for(int i = 0; i < s1.length(); i++)
{
cout << s1[i] << " ";
}
cout << endl;
//2:迭代器
for(string::iterator it = s1.begin(); it != s1.end(); it++)
{
cout << *it << " ";
}
cout << endl;
//3 异常处理
try
{
for(int i = 0; i < s1.length() + 3; i++)
{
cout << s1.at(i) << " "; //当出现错误时, 会向外抛出异常
}
}
catch(...)
{
cout << "发生异常" << endl;
}
try
{
for(int i = 0; i < s1.length() + 3; i++) //出现错误, 不向外抛出异常
{
cout << s1[i] << " ";
}
}
catch(...)
{
cout << "发生异常" << endl;
}
}
//字符指针和sting的转换
void f4()
{
//1:
string s1 = "aaabbb";
cout << s1.c_str() << endl;
//2:
char buf[128] = {0};
s1.copy(buf, 3, 1); //拷贝3个字符,从1个字符开始(位置下标从0开始) //注:不会自动加上字符串结束标志
cout << "buf: " << buf << endl;
}
//字符串的连接
void f5()
{
//1:
string s1 = "aaa";
string s2 = "bbb";
s1 = s1 + s2;
cout << "s1: " << s1 << endl;
//2:
string s3 = "333";
string s4 = "444";
s3.append(s4);
cout << "s3: " << s3 << endl;
}
//字符串的查找和替换
void f6()
{
string s1 = "wbm hello wbm 111 wbm 222 wbm 333";
//查找 从查找位置开始第一个出现的下标
int index = s1.find("wbm", 1); //位置下标从0开始
cout <<"index: " << index << endl << endl;
//查找每一次wbm出现的下标
int offindex = s1.find("wbm", 0);
while (offindex != string::npos) //不等于-1
{
cout << "offindex: " << offindex << endl;
offindex++;
offindex = s1.find("wbm", offindex);
}
//把所有的wbm换成大写
offindex = s1.find("wbm", 0);
while (offindex != string::npos) //不等于-1
{
s1.replace(offindex, 3, "WBM");
offindex++;
offindex = s1.find("wbm", offindex);
}
cout << endl << "s1替换后的结果为: " << s1 << endl;
//把aaa替换成大写
string s2 = "aaa bbb ccc";
s2.replace(0, 3, "AAA"); //从第0个位置开始替换3个
cout << endl << "s2: " << s2 << endl;
}
//区间删除和插入
void f7()
{
string s1 = "hello1 hello2 hello1";
string::iterator it = find(s1.begin(), s1.end(), 'l');
if (it != s1.end())
{
s1.erase(it); //删除
}
cout << "s1删除l以后的结果为:" << s1 << endl;
s1.erase(s1.begin(), s1.end());
cout << "s1全部删除:" << s1 << endl;
cout << "s1的长度为: " << s1.length() << endl;
//插入
string s2 = "BBB";
s2.insert(0, "AAA");
cout << "s2: " << s2 << endl;
}
//大小写转换
void f8()
{
string s1 = "AAAbbb";
transform(s1.begin(), s1.end(), s1.begin(), ::tolower); //transform(first,last,result,op);
cout << "s1全部转化为小写为: " << s1 << endl;
transform(s1.begin(), s1.end(), s1.begin(), ::toupper); //transform(first,last,result,op);
cout << "s1全部转化为大写为: " << s1 << endl;
}
int main()
{
f8();
return 0;
}
结束语
宇宙第一小仙女\(^o^)/~~萌量爆表求带飞=≡Σ((( つ^o^)つ~ dalao们点个关注呗~~
还比较全面叭~欢迎补充~有错误欢迎指出~
再次感谢各位大佬的们的分享!
本篇参考资料:
https://blog.csdn.net/w_linux/article/details/71600574
https://blog.csdn.net/shuzfan/article/details/53115922
https://blog.csdn.net/Duke10/article/details/78344226
https://blog.csdn.net/fanyun_01/article/details/56842637
https://blog.csdn.net/yas12345678/article/details/52601454
https://blog.csdn.net/wang907553141/article/details/52663223
http://towriting.com/blog/2013/08/08/improved-type-inference-in-cpp11/