今天讲解的是PDF数据提取与自动化(PDF Data Extraction and Automation)
一、安装PDF插件

二、准备PDF文档 (例1-4 Note.pdf, 例5 Invoice.pdf )


三、识别PDF所有文字和图像
1. 识别PDF文字: Read PDF txt
2. 识别PDF图像及文字: Read PDF with OCR 和Screen Scraping
3. 识别多个PDF中相同的单个字符 (Get Text 和Anchor Base)
例1:识别PDF文字
1. 新建一个sequence
2. 添加一个Read PDF txt的方法

Range是指扫描的页数,跟word文档打印的Range是一样的功能。例如:"All", "3-7", ”1”
3. 添加一个write txt file输出方法和message box屏幕输出方法

4. 运行结果如下:图片并未识别

例2:识别PDF图像和文字方法一
1. 添加Read PDF with OCR

2.运行结果如下:图片和文字均可识别

Tips:OCR识别的准确度会随着PDF图像的清晰度而降低,尽量避免使用OCR识别方法。
例3:识别PDF图像和文字方法二
1. 打开PDF文件,点击Screen Scraping

2. 保存录制结果,添加message box方法,接收 “MicrosoftedgeExeMicro” 变量

3. 运行结果如下

例4:识别多个Notes.pdf中相同的 ”IMPORTANT READ:”
1. 打开Notes.pdf,加入getText方法

2. 添加message box方法

3. 运行结果如下

4. 去掉title (可匹配多个PDF文档) 和 text (用index来代替字符串)
5. 接着打开Note2.pdf文档,点击运行按钮,测试结果仍然是 ”IMPORTANT READ:”,Selector选择器的情况如下


例5:使用Anchor Base锚点测试多个Invoice文件
1.打开Invoice1.pdf文件,添加一个Anchor Base,锚点里有两个参数,一是找到需要测试的对象名称,二是得到要测试对象的值

2. find element方法(或find image方法 )中的selectors修改如下
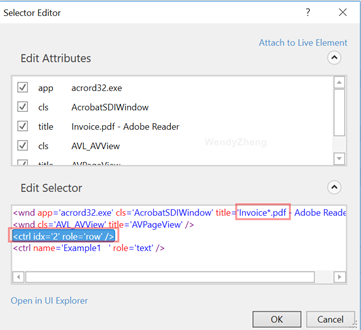
3. get text方法中的selectors修改如下

4. 分别测试Invoice1.pdf和Invoice2.pdf文件,测试结果请自行验证
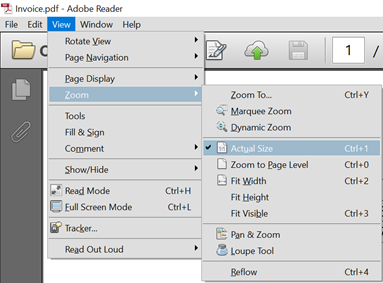
Tips:若使用find image方法,先将PDF设置为实际大小(我使用find image方法测试不成功)
扩展:后续会推出基于图像的自动化博客(image-based automation)