对于对吞吐量和延迟有极致追求的程序来说,提升应用程序的运行速度无疑能够显著增强其核心竞争力。下面就本人目前的认识简要介绍如下,有不足之处,还望指正。
阻止CPU的切换
CPU的切换会给成勋的运行带来非常大的损耗,主要是因为CPU切换带来的是CPU对应的内存数据的洗礼,当程序运行的CPU发生切换时,由于目前的CPU架构大部分都是NUMA架构,内存控制器天然的会把内存进行切割,固定分配到各个CPU,这就使得如果运行程序的CPU发生切换时,就需要重建页表,以建立虚拟内存和实际物理内存之间的映射关系,而这会极大的影响程序的运行速度。
解决方案:
为应用程序绑定CPU。
依据应用程序的特点开启大页内存
目前操作系统的内存都比较大,动辄几十G非常常见,如果应用程序属于高内存占用型,那么使用默认的内存分页大小(4KB)会使得虚拟内存和物理内存之间的页表变大,增加了内存地址的检索时间,同时也增大了快表失效的概率,如此将会增加CPU和内存交互的耗时,从而影响应用程序的响应时间。
当然对于内存占用比较小,且内存访问不随机的应用程序,则不需要开启大页内存,因为该类应用程序不会出现块表失效的可能或者说极少出现。
解决方案:
开启操作系统的大页内存。
依据应用场景合理控制内存分配策略
NUMA架构决定了CPU对于local access的时间远低于remote access,所以如果能够根据应用场景合理的控制内存分配策略,同时配合CPU的绑定机制,可以使得应用程序在指定的CPU上运行且改CPU不会remote access去访问其他节点的内存,那么就能够最大限度的提升应用程序的运行速度。
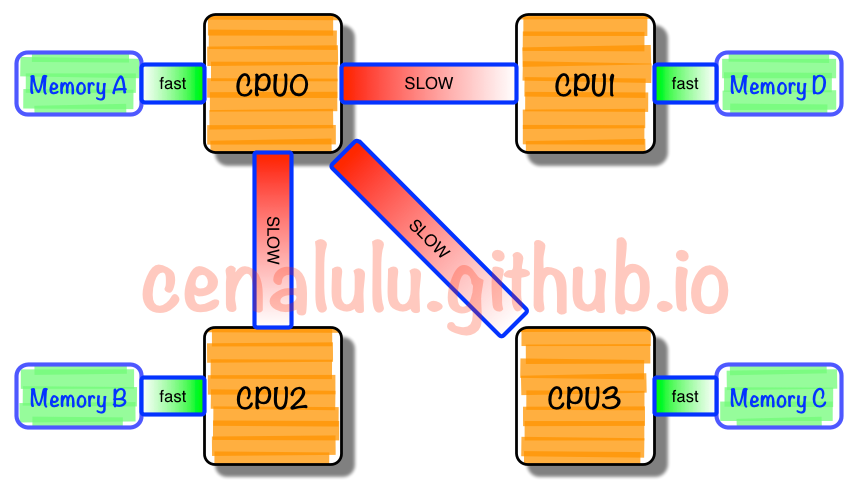
NUMA架构
在NUMA架构出现前,CPU欢快的朝着频率越来越高的方向发展。受到物理极限的挑战,又转为核数越来越多的方向发展。如果每个core的工作性质都是share-nothing(类似于map-reduce的node节点的作业属性),那么也许就不会有NUMA。由于所有CPU Core都是通过共享一个北桥来读取内存,随着核数如何的发展,北桥在响应时间上的性能瓶颈越来越明显。于是,聪明的硬件设计师们,先到了把内存控制器(原本北桥中读取内存的部分)也做个拆分,平分到了每个die上。于是NUMA就出现了!
NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(后称Remote Access)。所以NUMA(Non-Uniform Memory Access)就此得名。