这几天一直在整理排序算法,并想挨个实现出来,个人认为实现算法的代码多敲总不是坏事,写多了自然感觉就出来了。今天想要实现的希尔排序和堆排序,首先介绍这两种排序算法的实现原理,后面再上具体实现代码。
一、希尔排序
(1)原理:本质是针对直接插入排序的改进、通过一个自定义的增量,并按照这个增量分割成若干个子序列。使得每次排序,让子序列都趋于有序。直到增量递减为1时,整个序列将基本有序。增量为1时,整个序列被调整为有序状态了。具体,可以通过下图来体会一下:
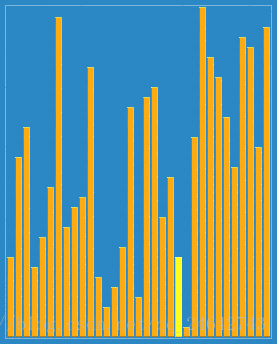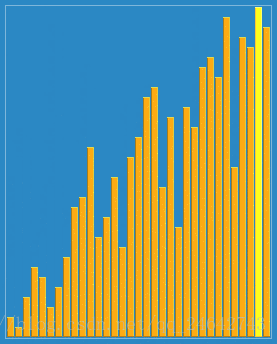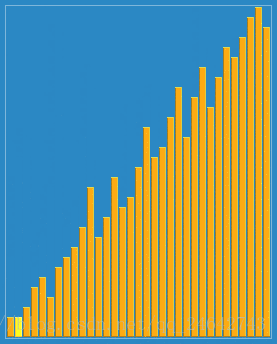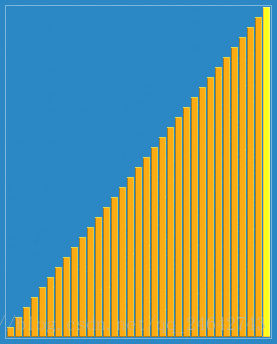
(2)特点: 增量的最后一个增量值必须等于1才行。由于记录是跳跃式的移动,希尔排序不是一种稳定的排序算法。其时间复杂度为O(n^(3/2))。
具体代码实现:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace 排序算法
{
class ShellSortTest
{
private static ShellSortTest _instance = new ShellSortTest();
public static ShellSortTest Instance
{
get { return _instance; }
}
//希尔排序 是对直接插入排序的改进
//主要思想:首先确定一个增量(增量一般为2^(t-k+1)-1(0≤k≤t≤log2(n+1))),
//将相距某个“增量”的记录组成一个子序列,
//这样才能保证在子序列内分别进行直接插入排序后得到的结果是基本有序而不是局部有序的。
//特点:1.不稳定排序 2.时间复杂度O(n^3/2)3.增量序列的最后一个增量值必须等于1才行
public void ShellSort(int[] nums)
{
int increment = nums.Length;
int temp,j;//临时变量,用于交换数值
do
{
//每次循环增量步长
increment = increment / 3 + 1;
//从当前增量位置开始,选择待插入元素
for (int i = increment; i < nums.Length; i++)
{
//待插入元素小于之前近邻 增量元素
if (nums[i] < nums[i - increment])
{
temp = nums[i];
//循环 以增量递减方式倒查找待插入位置j
for (j = i - increment; j > 0 && nums[j] > temp; j -= increment)
{
//间隔增量后移(跳跃式后移)
nums[j + increment] = nums[j];
}
nums[j + increment] = temp;
}
}
} while (increment > 1);//当增量为1时就停止循环
}
}
}二、堆排序
(1)堆:它是具有一下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于其左右孩子结点的值,称为小顶堆。如果按照层序遍历的方式给结点从1开始编号,则结点之间满足如下关系:
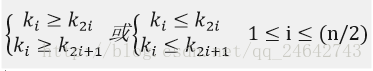
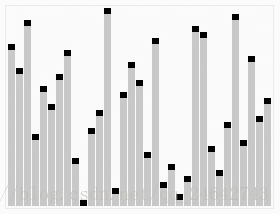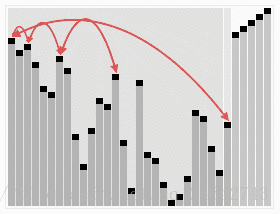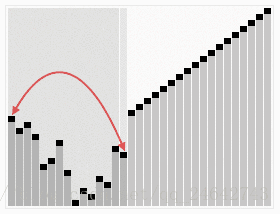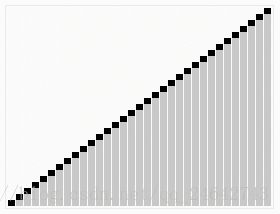
(2)原理:堆排序就是利用堆(假设利用大顶堆)进行排序的方法。它的基本思想是,将待排的序列构造成一个大顶堆。此时,整个序列的最大值就是堆顶的根结点。将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造出一个堆,这样就会得到n个元素中的次大值。如此反复执行,便能得到一个有序序列了。其主要解决的就只有两个问题:1.如何由一个无序序列构建成一个堆 2.如果在输出堆顶元素后,调整剩余元素成为一个新的堆。具体,可以通过下图来直观感受一下。
(3)特点: 它的运行时间主要是消耗在初始构建堆和重建堆时的反复筛选上。初始化构建堆的时间复杂度为O(n),n-1次重建堆的时间复杂度为O(nlogn)。空间复杂度上,它只有一个用来交换的暂存单元。由于记录的比较与交换是跳跃式进行,因此堆排序也是一种不稳定的排序方法。另外,由于初始构建堆所需的比较次数较多,因此,它并不适合排序序列个数较少的情况。
(4)具体实现代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace 堆排序
{
class Program
{
static void Main(string[] args)
{
int[] data = { 50, 10, 90, 30, 70, 40, 80, 60, 20 };
HeapSort(data);
foreach (int temp in data)
{
Console.Write(temp+" ");
}
Console.WriteLine();
Console.ReadKey();
}
//交换
public static void Swap(int[] nums, int i, int j)
{
i -= 1;
j -= 1;
nums[i] ^= nums[j];
nums[j] ^= nums[i];
nums[i] ^= nums[j];
}
//堆排序 从大到小
public static void HeapSort(int[] data)
{
//层次遍历这个数的所有非叶子节点,把所有子树,变成子大顶堆 构建初始化堆
//整个构建堆的时间复杂度为O(n)
for (int i = data.Length / 2; i >= 1; i--)
{
HeapAdjust(data,i,data.Length);
}
//需要取n-1次堆顶元素
//取第i次堆顶记录重建堆需要O(logi)时间(完全二叉树的某个结点到根结点的距离为log2(i)+1),且需要取n-1次
//因此,重建堆的时间复杂度为O(nlog(n))
for (int i = data.Length; i > 1; i--)
{
//把编号1和i位置进行交换
Swap(data,1,i);
//因为,当前i的位置为堆顶,在上一行代码中被移除去了,所以需要重新把1~i-1构造成大顶堆
HeapAdjust(data,1,i-1);
}
}
/// <summary>
/// 堆排序重建
/// </summary>
/// <param name="data">排序数组</param>
/// <param name="i">当前子堆顶父元素编号</param>
/// <param name="length">当前剩余排序元素个数</param>
public static void HeapAdjust(int[] data, int i, int length)
{
int maxNodeNum = i; //默认父节点为当前子树的最大结点
int tempI = maxNodeNum;
while (true)
{
//把i结点的子树变成大顶堆
int leftChildNum = 2 * tempI; //左子结点编号
int rightChildNum = leftChildNum + 1; //右子节点编号
//如果左孩子结点比父结点要大 此处leftChildNum为编号,所以需要等于待排元素个数,由于数组是从0开始的
if (leftChildNum <= length && data[maxNodeNum - 1] < data[leftChildNum - 1])
{
maxNodeNum = leftChildNum;
}
//如果右孩子结点比父结点要大
if (rightChildNum <= length && data[maxNodeNum - 1] < data[rightChildNum - 1])
{
maxNodeNum = rightChildNum;
}
//发现了一个比i更大的子结点,交换i和maxNodeNum里面的数据
if (maxNodeNum != tempI)
{
Swap(data, tempI, maxNodeNum);
tempI = maxNodeNum;
}
else
{
break;
}
}
}
}
}以上就是今天实现的两种排序算法,下一节将介绍归并排序算法。如果文中若有不对的地方,还劳烦你指出!谢谢!