折半查找又称为二分查找,插值查找是在折半查找算法基础上优化而来,斐波那契查找算法又是针对插值查找进一步优化的,因此,我们先看下简单的折半查找算法,然后再剖析另外两种查找算法。注意,这里的查找均是有序表的查找,也就是说,待查的列表必须为有序的。因此,需要在查找之前,对列表进行排序操作。
一、折半查找
折半查找的基本思想:在有序表中,取中间记录作为比较对象,若给定值与中间记录的关键字相等,则查找成功;若给定值小于中间记录的关键字,则在中间记录的左半区继续查找;若给定值大于中间记录的关键字,则在中间记录的右半区继续查找;不断重复上述过程,直到查找成功,或所有查找区域无记录,查找失败失败为止。具体代码如下:
/// <summary>
/// 二分查找,返回指定元素的索引
/// </summary>
/// <param name="nums">待查找元素</param>
/// <param name="key">关键字</param>
/// <returns></returns>
public int Binary_Search(int[] nums, int key)
{
int low = 0, high = nums.Length-1, mid;
while (low <= high)
{
mid = (low + high) / 2; //折半查找
if (key < nums[mid])
high = mid - 1;
else if (key > nums[mid])
low = mid + 1;
else
return mid;
}
return -1;
}形象的可以将折半查找理解为两棵子树,即查找结果只需要找其中的一般数据记录即可。折半算法的时间复杂度为O(log n),优于顺序查找O(n)。由于折半查找的前提条件是需要有序表顺序存储,对于静态查找表,一次排序后不再变化,这样算法已经比较好了。但对于需要频繁执行插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,此时,就不建议使用。
二、插值查找
此时,我们有一个新的问题,为什么要折半,而不是折四分之一或者更多呢?具体来说,比如,我们要在取值范围0~10000之间100个元素从小到大均匀分布的数组中查找5,我们自然会考虑从数组下标较小的开始查找。由此可知,折半查找是有改进空间的。
在上述折半查找代码中,mid = (low+high)/2=low + (high - low)/2;也就是mid等于最低下标low加上最高下标high与low的差的一半。算法科学家就是针对1/2来进行优化的,具体如下:
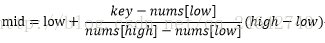
主要修改的部分就是将1/2改成了(key-nums[low])/(nums[high]-nums[low])。假设nums[10] ={1,16,24,35,47,59,62,73,88,99},low = 1,high = 9;则nums[low] = 1,nums[high] = 99,如果我们要查找16的话,按照折半的做法,需要四次才能够得到结果,但是按照新方法,(key-nums[low])/(nums[high]-nums[low]) =(16-1)/(99-1)≈0.153,即mid ≈ 1+0.153*(10-1) = 2.377取整得到mid=2,我们只需要查找两次就找到了,显然效率得到了提升。具体代码,就是将上述mid的语句进行替换,替换如下:
mid = low + (key - nums[low]) * (high - low) / (nums[high] - nums[low]);//插值运算插值查找是根据查找的关键字key与查找表中最大最小的关键字比较后的查找方法,其核心就在于查找的计算公式(key-nums[low])/(nums[high]-nums[low])。应该说,从时间复杂度来看,它也是O(log n),但对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好得多。反之,数组中如果分布类似{0,1,2,2000,2001,……,999998,999999}这种极端的不均匀的数据,用插值算法就不合适了。
三、斐波那契查找
斐波那契查找,它是利用黄金分割原理来实现的。本质是利用斐波那契数列来进行分割。分割本质如下图:
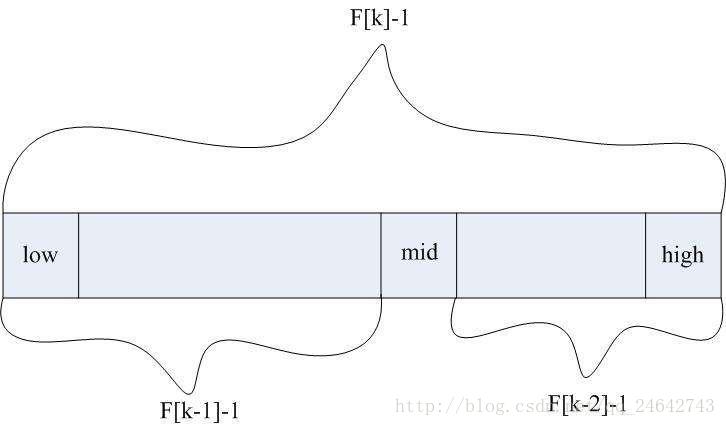
具体代码:
private static int MAXSIZE = 100;
private int[] F = new int[MAXSIZE];
//创建一个斐波那契数列
public void CalculateFibonacci()
{
F[0] = 0;
F[1] = 1;
for (int i = 2; i < F.Length; i++)
F[i] = F[i - 1] + F[i - 2];
}
//斐波那契查找核心在于:
//当key = nums[mid]时,查找成功;
//当key<nums[mid]时,新范围是第low个到第mid-1个,此时范围个数为F[k-1]-1个;
//当key>nums[mid]时,新范围是第mid+1个到第high个,此时范围个数为F[k-2]-1个;
public int Fibonacci_Search(int[] nums, int key)
{
int n = nums.Length - 1; //数组最大有效下标
int low = 0, high = n, mid, k = 0;
int[] newNums;
CalculateFibonacci();//计算斐波那契数列
//找出数组长度n在斐波那契数列的区间
while ((n + 1) > F[k])
k++;
//数组需要扩容
if (n < F[k] - 1)
{
//扩容
newNums = new int[F[k]];
for (int i = 0; i <= n; i++)
newNums[i] = nums[i];
}
else
{
newNums = nums;
}
//若F[k]>n时,避免后面在nums中取值时,数组越界而报错,因此在上面需要对nums进行扩容。
for (int i = n; i < F[k] - 1; i++)
newNums[i] = newNums[n];
//查找核心算法
while (low <= high)
{
//从low开始,有F[k - 1] - 1个元素,才到mid
mid = low + F[k - 1] - 1;
if (key < newNums[mid])
{
high = mid - 1;
k = k - 1;
}
else if (key > newNums[mid])
{
low = mid + 1;
k = k - 2;
}
else
{
if (mid <= n)
return mid;
//超出的部分就是后面我们自动补全的
else
return n;
}
}
return -1;
}也就是说,如果要查找的记录在右侧,则左侧的数据都不用再判断,不断反复进行下去,对处于当中的大部分数据,其工作效率要高一些,所以尽管斐波那契查找时间复杂度为O(log n),但就平均性能来说,斐波那契要优于折半查找,则效率要低于折半查找。还有关键一点是,折半查找mid是加法与除法运算,插值查找进行复杂的四则元算,而斐波那契查找只是最简单的加减法元算,在海量数据的查找过程中,这种细微的差别可能会影响最终的查找效率。
四、实验与结果
上述几种查找方式实验,如下图:
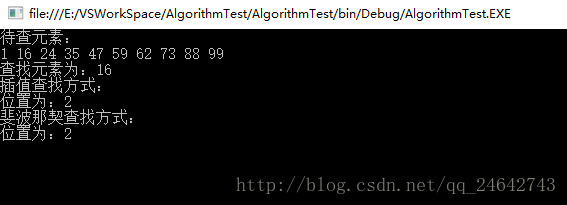
在实际运用过程中,要选择哪一种查找方式需要根据实际数据特点来决定,各有优劣。这三种都是 针对有序表进行查找操作的。如文中有疑问之处,可以私信我,谢谢!!!