****************根据网址获取指定的网页内容********************
private static String getHtml(String path){
StringBuffer html = new StringBuffer();//保存整个html文档的数据
try {
//1.发起一个url网址的请求
URL url = new URL(path);
URLConnection connection = url.openConnection();
//2.获取网页的数据流
InputStream input = connection.getInputStream(); //字节流 一个字节一个字节的读取 中文占用两个字节
InputStreamReader reader = new InputStreamReader(input,"GBK"); //字符流 一个字符一个字符的读取 可指定字符集编码 ,常用字符集编码:GBK,GB2312,utf-8,ISO-8859-1
BufferedReader bufferedReader = new BufferedReader(reader); //字符流 一行一行的读取
//3.解析并且获取InputStream中具体的数据,并且输出到控制台
String line = "";
while((line = bufferedReader.readLine()) != null)
{
html.append(line); //将所有读到的每行信息line追加到(拼接到)html对象上
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return html.toString();
}
****************解析html网页内容********************
private static List parseHtml(String html) {
// 2.解析html网页内容
Document document = Jsoup.parse(html);
// 获取所有的招聘信息所在的div节点
Element div = document.getElementById("resultList");
// 获取div中所有的招聘信息的div
Elements jobs = div.getElementsByClass("el");
List<Job> jobList = new ArrayList<Job>();
for (Element job : jobs) {
// 工作名称
String jobName = job.getElementsByClass("t1").get(0).text().toUpperCase();
jobName = parseJob(jobName);
// 公司名称
String company = job.getElementsByClass("t2").get(0).text();
// 工作地点
String address = job.getElementsByClass("t3").get(0).text();
// 薪酬待遇
String salary = job.getElementsByClass("t4").get(0).text();
// 求平均值
double avgSalary = getAvgSalary(salary);
// 封装招聘信息
Job myJob = new Job();
myJob.setJobName(jobName);
myJob.setCompany(company);
myJob.setAddress(address);
myJob.setSalary(avgSalary);
// 将对象添加到集合里面
jobList.add(myJob);
}
return jobList;
}
*******************解释***********************
通过访问某网站地址之后,设置读的方式,解析内容,可以先去网页确认你要爬取的数据,进入开发者模式(F12),看网页的结构是怎样的,程序中是先拿到节点id为resultList,里面的一行一行数据的class都为el,分析网页即可以找到有用的信息,这样就可以更准确地爬到想要的数据
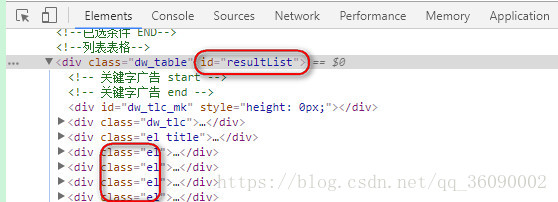
拿到数据之后,将一条条信息进行封装,然后把封装的信息添加到集合中,如果要对数据进行一些处理,可以将处理信息的方法封装一下调用即可。
接下来,开始数据库操作……
*********************END*************************