记录:及其简单的牛客网讨论区爬虫
源代码:
var express = require('express');
var superagent = require('superagent');
var cheerio = require('cheerio');
var url = require('url');
var cnodeUrl = 'https://www.nowcoder.com/discuss';
router.get('/', function(req, res, next) {
// 用 superagent 去抓取 https://www.nowcoder.com/discuss 的内容
superagent.get(cnodeUrl).end(function(err, sres){
// 常规的错误处理
if(err){
return next(err);
}
// sres.text 里面存储着网页的 html 内容
var $ = cheerio.load(sres.text);
var items = [];
$('.discuss-main').each(function(idx, element){
var $element = $(element);
items.push({
title: $element.find('a').text(),
href: $element.find('a').attr('href'),
link: url.resolve(cnodeUrl, $element.find('a').attr('href'))
});
});
res.send(items);
})
});目标结构:
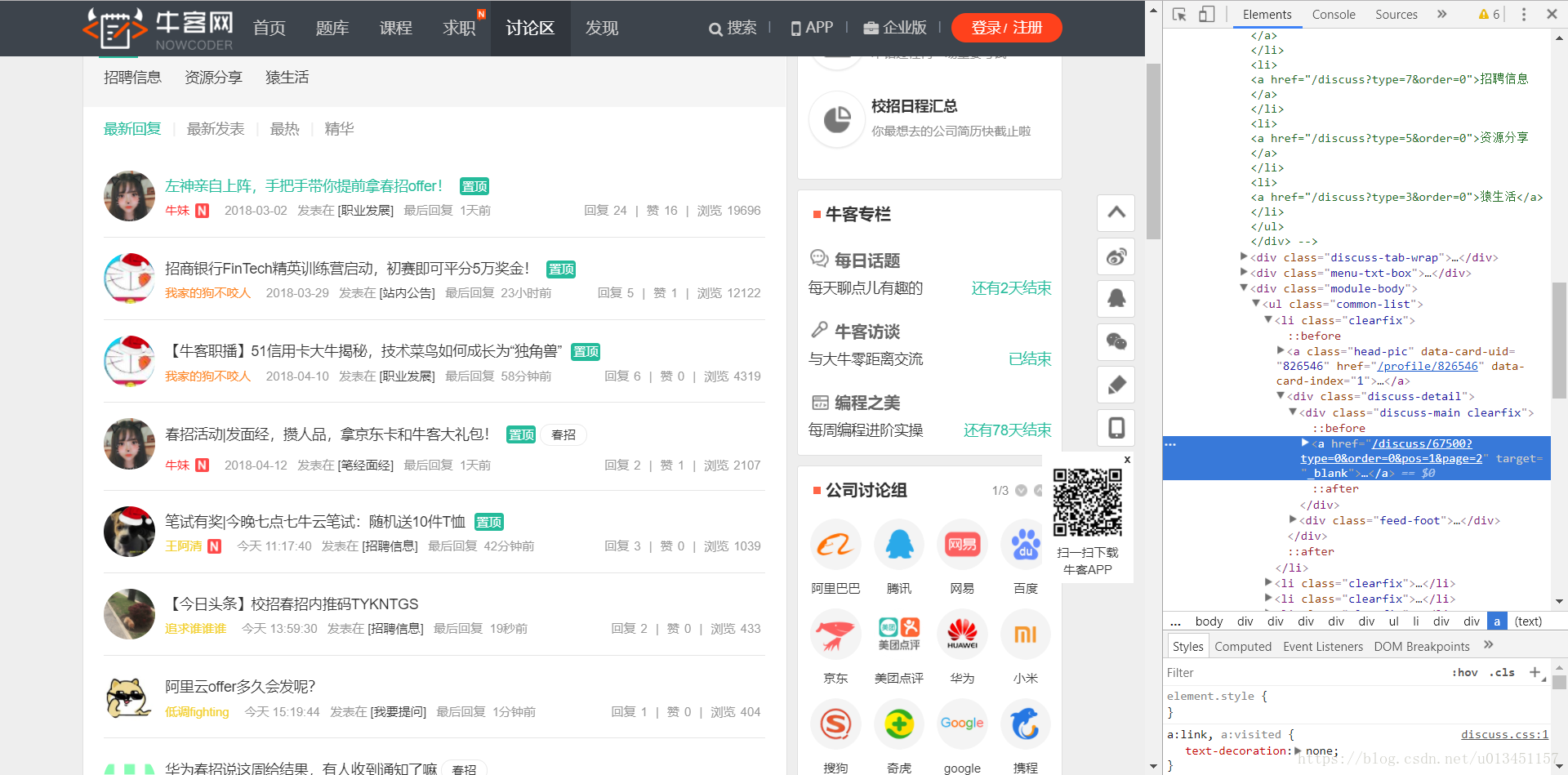
效果展示:
