while 循环
# while 循环的结构:
'''
while 条件:
循环体
'''
# 如何终止循环?
# 1,改变条件 (标志位的概念)
# 2, break 终止循环。
# flag = True
# count = 1
# while flag:
# print(count)
# count = count + 1
# if count == 101:
# flag = False
# break 循环中只要遇到break 立马结束循环。
# while True:
# print(111)
# print(222)
# break
# print(333)
# print(444)
# print(123)
# continue: 结束本次循环,继续下一次循环。
# while True:
# print(111)
# print(222)
# continue
# print(333)
# while else 结构
# 如果while循环被break打断,则不执行else代码。
# count = 1
# while count < 5:
# print(count)
# count = count + 1
# if count == 3: break
# else:
# print(666)
# print(222)
# 应用场景:
# 验证用户名密码,重新输入这个功能需要while循环。
# 无限次的显示页面,无限次的输入......
格式化输出
制作一个模板,某些位置的参数是动态的,像这样,就需要用格式化输出。
# name = input('请输入姓名:')
# age = int(input('请输入年龄:'))
# sex = input('请输入性别:')
# % 占位符 s 数据类型为字符串 d 数字
# 第一种方式:
# msg = '你的名字是%s,你的年龄%d,你的性别%s' % (name,age,sex)
# print(msg)
# 第二种方式
# msg = '你的名字是%(name1)s,你的年龄%(age1)d,你的性别%(sex1)s' % {'name1':name,'age1':age,'sex1':sex}
# print(msg)
# bug 点 在格式化输出中,只想单纯的表示一个%时,应该用%% 表示
# msg = '我叫%s,今年%d,我的学习进度1%%' % ('关亮和',28)
# print(msg)
运算符
== 比较的两边的值是否相等 = 赋值运算
!= 不等于
+= 举例: count = count + 1 简写 count += 1
-=
*= : count = count * 5 简写 count *= 5
/=
**=
//=
。。。。
逻辑运算符
and or not
# 优先级:()> not > and > or
# 第一种情况,前后条件为比较运算
# print(1 < 2 or 3 > 1)
# print(1 < 2 and 3 > 4)
# print(1 < 2 and 3 > 4 or 8 < 6 and 9 > 5 or 7 > 2)
# print(1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8)
# print(1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6)
# 第二种情况,前后两边的条件为数值
'''
x or y if x is True,return x
'''
# print(1 or 2)
# print(1 and 2)
# print(5 or 2)
# print(5 and 2)
# print(0 or 2)
# print(-1 or 2)
'''
# 补充
# int < --- > bool
# 0 对应的bool值为False,非0 都是True.
# True 1 ,False 0
# print(bool(100))
# print(bool(-1))
# print(bool(0))
# print(int(True))
# print(int(False))
'''
# print(0 or 3 and 5 or 4)
# 变态面试题:思考
# print(1 > 2 or 3 and 4 < 6)
# print(2 or 3 and 4 < 6)
# 应用:
# 1,if while 等条件判断(数据库,Django orm Q查询)。
# 1,面试。
编码初识
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。

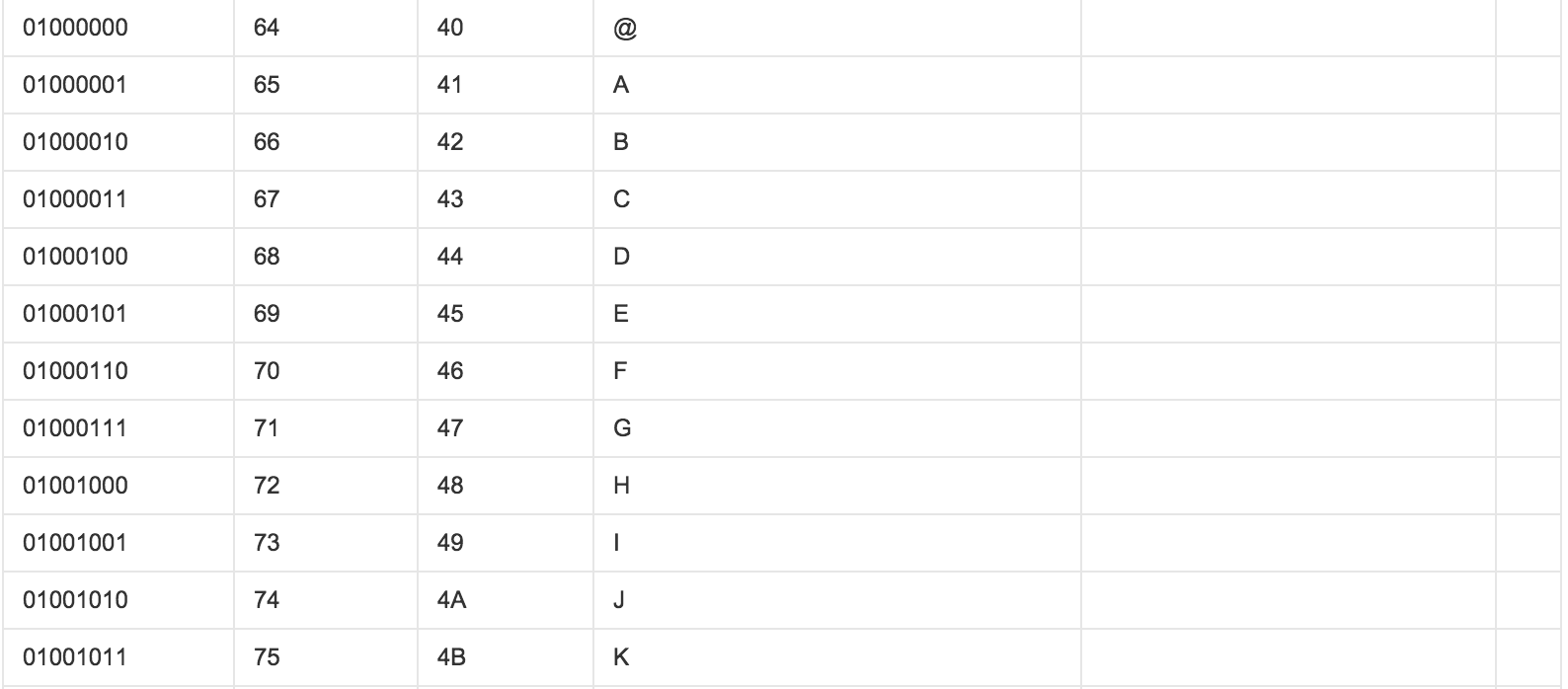
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
|
1
2
3
|
#!/usr/bin/env python
print
"你好,世界"
|
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
|
1
2
3
4
|
#!/usr/bin/env python
# -*- coding: utf-8 -*-
print
"你好,世界"
|