uthash版本 :2.0.2
作者:jafon.tian
转载请注明出处:https://blog.csdn.net/JT_Notes
简要说明
uthash是采用宏函数来完成hash表功能。总体上可以分为两大类:
1. API宏函数
2. 内部宏函数
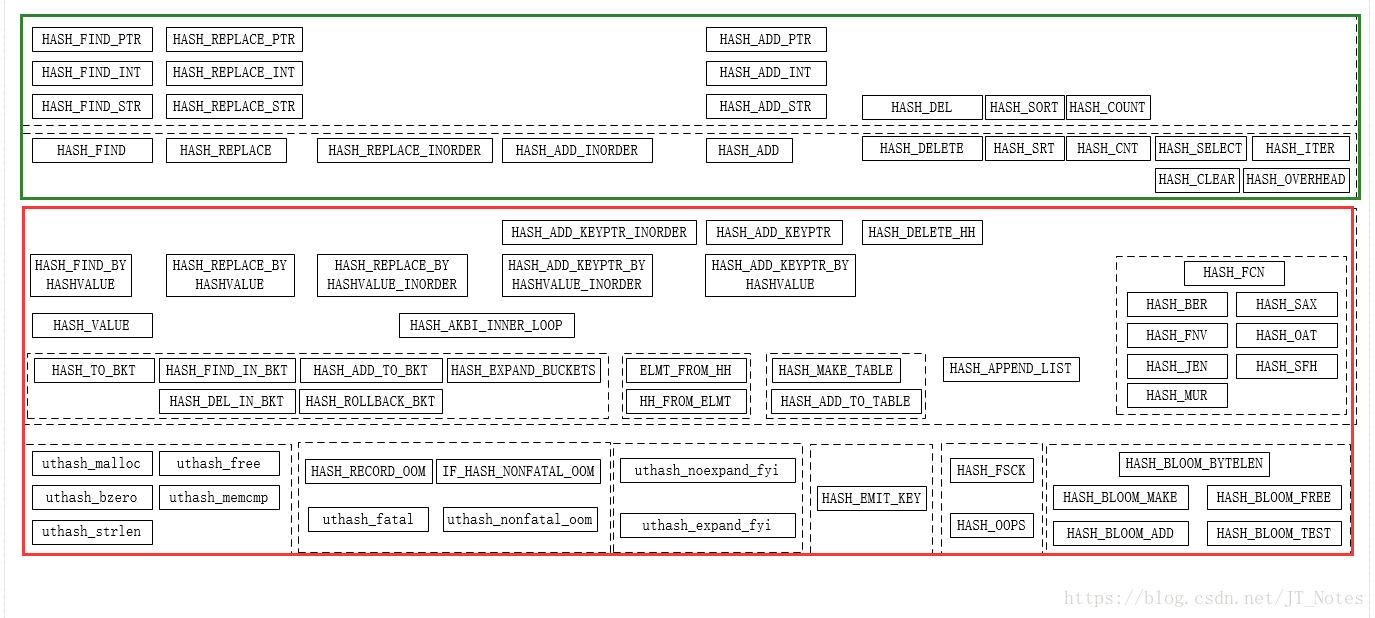
API宏函数
uthash提供了两大类对外API宏函数:
1. 快捷宏函数。快捷宏可以操作key数据类型是整数,指针或字符串的hash表(需要将UT_hash_handle名称取为hh)。快捷宏比一般宏使用更少的参数,对那些采用一般数据类型做key的情形使用起来会简单一些。
2. 一般宏函数。一般宏定义可以被用在key不是一般数据类型或者是多个成员组合或者UT_hash_handle名称不是hh的情形。这些宏需要更多的参数,因而也提供了更大的灵活性。
如果快捷宏已经可以满足你的需要,那就使用快捷宏,这样会使你的代码更具可读性。
- 便捷宏定义
| 名称 | 参数及简要说明 |
|---|---|
| HASH_ADD_INT | (head, intfield, add) 基于HASH_ADD的类型定制宏,key类型为int,key大小为sizeof(int) HASH_ADD(hh,head,intfield,sizeof(int),add) |
| HASH_REPLACE_INT | (head, intfield, add, replaced) 基于HASH_REPLACE的类型定制宏,key类型为int,key大小为sizeof(int) HASH_REPLACE(hh,head,intfield,sizeof(int),add,replaced) |
| HASH_FIND_INT | (head, findint, out) 基于HASH_FIND的类型定制宏,key类型为int,key大小为sizeof(int) HASH_FIND(hh,head,findint,sizeof(int),out) |
| HASH_ADD_STR | (head, strfield, add) 基于HASH_ADD的类型定制宏,key类型为char [ ] ,key大小使用uthash_strlen计算 |
| HASH_REPLACE_STR | (head, strfield, add, replaced) 基于HASH_REPLACE的类型定制宏,key类型为char [ ] ,key大小使用uthash_strlen计算 |
| HASH_FIND_STR | (head, findstr, out) 基于HASH_FIND的类型定制宏,key类型为char [ ] ,key大小使用uthash_strlen计算 |
| HASH_ADD_PTR | (head, ptrfield, add) 基于HASH_ADD的类型定制宏,key类型为指针,key大小为sizeof(void *) |
| HASH_REPLACE_PTR | (head, ptrfield, add, replaced) 基于HASH_REPLACE的类型定制宏,key类型为指针,key大小为sizeof(void *) |
| HASH_FIND_PTR | (head, findptr, out) 基于HASH_FIND的类型定制宏,key类型为指针,key大小为sizeof(void *) |
| HASH_DEL | (head, delptr) 基于HASH_DELETE的宏 |
| HASH_SORT | (head, cmpfcn) 基于HASH_SRT的宏 |
| HASH_COUNT | (head) 基于HASH_CNT的宏 |
注:使用便捷宏的前提是结构体中的UT_hash_handle成员名称必须为hh,key类型只能是int,char [ ]和指针类型。
- 一般宏定义
| 名称 | 参数 |
|---|---|
| HASH_ADD | (hh_name, head, keyfield_name, key_len, item_ptr) 基于HASH_ADD_KEYPTR的宏 |
| HASH_ADD_KEYPTR | (hh_name, head, key_ptr, key_len, item_ptr) 通过HASH_VALUE计算出hashvalue之后,直接调用HASH_ADD_KEYPTR_BYHASHVALUE |
| HASH_ADD_INORDER | (hh_name, head, keyfield_name, key_len, item_ptr, cmp) 基于HASH_ADD_KEYPTR_INORDER的宏 |
| HASH_ADD_BYHASHVALUE_INORDER | (hh_name, head, keyfield_name, key_len, key_hash, item_ptr, cmp) 基于HASH_ADD_KEYPTR_BYHASHVALUE_INORDER的宏 |
| HASH_ADD_KEYPTR_INORDER | (hh_name, head, key_ptr, key_len, item_ptr, cmp) 通过HASH_VALUE计算出hashvalue之后,直接调用HASH_ADD_KEYPTR_BYHASHVALUE_INORDER |
| HASH_REPLACE | (hh_name, head, keyfield_name, key_len, item_ptr, replaced_item_ptr) 通过HASH_VALUE计算出hashvalue之后,直接调用HASH_REPLACE_BYHASHVALUE |
| HASH_REPLACE_INORDER | (hh_name, head, keyfield_name, key_len, item_ptr, replaced_item_ptr, cmp) 通过HASH_VALUE计算出hashvalue之后,直接调用HASH_REPLACE_BYHASHVALUE_INORDER |
| HASH_FIND | (hh_name, head, key_ptr, key_len, item_ptr) 通过HASH_VALUE计算出hashvalue之后,直接调用HASH_FIND_BYHASHVALUE |
| HASH_DELETE | (hh_name, head, item_ptr) 基于HASH_DELETE_HH的宏 |
| HASH_SRT | (hh_name, head, cmp) O(n log(n))的排序算法 |
| HASH_CNT | (hh_name, head) 获取hash表所有元素个数 |
| HASH_CLEAR | (hh_name, head) 释放uthash资源 |
| HASH_SELECT | (dst_hh_name, dst_head, src_hh_name, src_head, condition) 将源hash表中复合条件的元素添加到目标hash表 |
| HASH_ITER | (hh_name, head, item_ptr, tmp_item_ptr) hash表迭代器 |
| HASH_OVERHEAD | (hh_name, head) 统计hash表内部结构消耗的内存 |
内部宏函数
内部函数分为:
1. api支持类
2. bucket操作类
3. hash算法类
4. hh和element转换类
5. 库封装类
6. bloom类
7. 调试和异常处理类
api支持类
| 名称 | 参数及简要说明 |
|---|---|
| HASH_VALUE | (key_ptr, key_len, key_hash) 计算hashvalue |
| HASH_ADD_BYHASHVALUE | (hh_name, head, keyfield_name, key_len, key_hash, item_ptr) 基于HASH_ADD_KEYPTR_BYHASHVALUE的宏 |
| HASH_ADD_KEYPTR_BYHASHVALUE | (hh_name, head, key_ptr, key_len, key_hash, item_ptr) 添加操作的核心宏定义 |
| HASH_ADD_KEYPTR_BYHASHVALUE_INORDER | (hh_name, head, key_ptr, key_len, key_hash, item_ptr, cmp) 顺序添加操作的核心宏定义 |
| HASH_REPLACE_BYHASHVALUE | (hh_name, head, keyfield_name, key_len, key_hash, item_ptr, replaced_item_ptr) HASH_FIND_BYHASHVALUE、HASH_DELETE和HASH_ADD_KEYPTR_BYHASHVALUE的组合 |
| HASH_REPLACE_BYHASHVALUE_INORDER | (hh_name, head, keyfield_name, key_len, key_hash, item_ptr, replaced_item_ptr, cmp) HASH_FIND_BYHASHVALUE、HASH_DELETE和HASH_ADD_KEYPTR_BYHASHVALUE_INORDER的组合 |
| HASH_FIND_BYHASHVALUE | (hh_name, head, key_ptr, key_len, key_hash, item_ptr) 查找操作的核心宏定义 |
| HASH_DELETE_HH | (hh_name, head, delptrhh) 删除操作的核心宏定义 |
bucket操作类
在bucket中添加、删除、查找元素,根据hashvalue找到对应的bucket,并在适当时机进行bucket回滚和扩张。
| 名称 | 参数及简要说明 |
|---|---|
| HASH_TO_BKT | (hashv,num_bkts,bkt) 根据hashvalue和bucket总数计算出该hashvalue所在的bucket |
| HASH_FIND_IN_BKT | (tbl,hh,head,keyptr,keylen_in,hashval,out) 在一个bucket中找到拥有指定key的元素 |
| HASH_ADD_TO_BKT | (head,hh,addhh,oomed) 将元素添加到bucket中 |
| HASH_DEL_IN_BKT | (head,delhh) 将元素从bucket中删除 |
| HASH_ROLLBACK_BKT | (hh, head, itemptrhh) 在HASH_ADD_TO_BKT失败时,将bucket滚回添加操作之前的状态 |
| HASH_EXPAND_BUCKETS | (hh,tbl,oomed) 扩张bucket数量,核心宏定义 |
hash算法类
目前版本的uthash支持七种hash算法,具体使用哪一种是通过HASH_FCN来指定的
/* default to Jenkin's hash unless overridden e.g. DHASH_FUNCTION=HASH_SAX */
#ifdef HASH_FUNCTION
#define HASH_FCN HASH_FUNCTION
#else
#define HASH_FCN HASH_JEN
#endif| 名称 | 参数及简要说明 |
|---|---|
| HASH_BER HASH_FNV HASH_JEN HASH_MUR HASH_SAX HASH_OAT HASH_SFH |
(key,keylen,hashv) 计算hashvalue |
hh和element转换类
| 名称 | 参数及简要说明 |
|---|---|
| ELMT_FROM_HH | (tbl,hhp) 给定应用结构体变量找到hash表句柄 |
| HH_FROM_ELMT | (tbl,elp) 给定hash表句柄找到应用结构体变量 |
库封装类
#ifndef uthash_malloc
#define uthash_malloc(sz) malloc(sz) /* malloc fcn */
#endif
#ifndef uthash_free
#define uthash_free(ptr,sz) free(ptr) /* free fcn */
#endif
#ifndef uthash_bzero
#define uthash_bzero(a,n) memset(a,'\0',n)
#endif
#ifndef uthash_memcmp
#define uthash_memcmp(a,b,n) memcmp(a,b,n)
#endif
#ifndef uthash_strlen
#define uthash_strlen(s) strlen(s)
#endifbloom类
| 名称 | 参数及简要说明 |
|---|---|
| HASH_BLOOM_BYTELEN | bloom占用内存空间的大小(单位是字节) |
| HASH_BLOOM_MAKE | (tbl, oomed) 建立bloom结构 |
| HASH_BLOOM_FREE | (tbl) 释放bloom结构 |
| HASH_BLOOM_ADD | (tbl, hashv) 根据hashv进行计算出位置,并设置bloom对应位 |
| HASH_BLOOM_TEST | (tbl, hashv) 根据hashv进行计算出位置,并判断bloom中相应位是否已置位 |
调试和异常处理类
| 名称 | 参数及简要说明 |
|---|---|
| HASH_RECORD_OOM | (oomed) 异常已发生,进行记录 |
| IF_HASH_NONFATAL_OOM | 在可恢复情况下,判断异常是否已经发生 |
| uthash_fatal | 不可恢复情况下,异常处理 |
| uthash_nonfatal_oom | 可恢复情况下,异常处理 |