一、视图
视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】,用户使用时只需使用【名称】即可获取结果集,可以将该结果集当做表来使用。
使用视图我们可以把查询过程中的临时表摘出来,用视图去实现,这样以后再想操作该临时表的数据时就无需重写复杂的sql了,直接去视图中查找即可,但视图有明显地效率问题,并且视图是存放在数据库中的,如果我们程序中使用的sql过分依赖数据库中的视图,即强耦合,那就意味着扩展sql极为不便,因此并不推荐使用
-- 1.视图是一个虚拟表(非正式存在),其本质是其本质是 -- 【根据SQL语句获取动态的数据集,并为其命名】, -- 用户使用时只需使用【名称】即可获取结果集, -- 可以将该结果集当做表来使用。 -- 2. -- 有了视图以后你是不是觉得写sql语句就很简单了,但是你尽量不要这样做 -- 因为mysql是DBA管着呢,那么你告诉DBA建一堆视图,你写程序的时候是方便了, -- 但是你要是修改呢,那么你就得修改视图了,你就得找到DBA修改你的视图了, -- 那么这样联系别人会很麻烦的。说不定人家还很忙呢。还是推荐自己去写sql语句。 -- #注意: -- 如果是一个单表的就可以修改或者删除或者插入 -- 如果是几个表关联的时候是不可以修改或者删除或者插入的(这点也是不确定的,有的可以改,有的不可以改)
准备表
======================== 创建部门表 create table dep( id int primary key auto_increment, name char(32) ); 创建用户表 create table user( id int primary key auto_increment, name char(32), dep_id int, foreign key(dep_id) references dep(id) ); 插数据 insert into dep(name) values('外交部'),('销售'),('财经部'); insert into user(name,dep_id) values ('egon',1), ('alex',2), ('haiyan',3);
1.创建视图
创建视图语法:
CREATE VIEW 视图名称 AS SQL语句
create view teacher_view as select tid from teacher where tname='李平老师';
#连表 select * from dep left join user on dep.id = user.dep_id; #创建一个视图 create view user_dep_view as select dep.id depid ,user.id uid ,user.name uname,dep.name depname from dep left join user on dep.id = user.dep_id; -- 这样创建一个视图以后就可以吧一个虚拟表保存下来,就可以查看了。 select uname from user_dep_view where depid = 3;
-- 我的电脑上不可以增删改,只可查看。但是有的电脑上又可以增删改,可能是跟版本有关
#测试
insert into user_dep_view VALUES (1,2,'egon','人文部'); #会报错
DELETE from user_dep_view where uid = 1; #会报错
update user_dep_view set uname = '海燕' where depid = 2; #会报错
-- 对于单表来说是可以修改的,并且原来表的也就更改了。
-- 但是一般还是不要这样改。视图大多数是用来查看的
#建表 CREATE TABLE t1( id int PRIMARY KEY auto_increment, name CHAR(10) ); #插入数据 insert into t1 VALUES (1,'egon'), (2,'daa'), (3,'eef'); #创建视图 CREATE view t1_view as select * from t1; #测试创建视图以后还能不能增删改查 select * from t1_view; update t1_view set name = '海燕' where id = 2; #可以修改(而且原来表的记录也修改了) INSERT into t1_view values(4,'aaa'); #可以插入(同上) delete from t1_view where id=3;#同上
2.修改视图
语法:ALTER VIEW 视图名称 AS SQL语句
3.删除视图
语法:DROP VIEW 视图名称
二、触发器
使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,注意:没有查询
-- 触发器:某种程序触发了工具的运行 -- 触发器不能主动调用,只有触发了某种行为才会调用触发器的执行 -- 插入一条记录就触发一次 -- 还是建议不要用触发器,因为这是BDA管理的,还是不如你在程序里面直接写比较方便
1.创建触发器的语法
create trigger trigger_name trigger_time trigger_event on tbl_name for each row triggrr_body #主体,就是在触发器里干什么事 trigger_time:{before | after} trigger_event:{insert | update |detele}
准备表
-- # 2.准备表 -- #第一步:准备表 create table cmd_log( id int primary key auto_increment, cmd_name char(64), #命令的名字 sub_time datetime, #提交时间 user_name char(32), #是哪个用户过来执行这个命令 is_success enum('yes','no') #命令是否执行成功 ); create table err_log( id int primary key auto_increment, cname char(64), #命令的名字 stime datetime #提交时间 );
创建触发器
-- #创建触发器(向err_log表里插入最新的记录) delimiter // create trigger tri_after_inser_cmd_log after insert on cmd_log for each row BEGIN if new.is_success = 'no' then insert into err_log(cname,stime) VALUES(new.cmd_name,new.sub_time); end if; #记得加分号,mysql一加分号代表结束,那么就得声明一下 END // delimiter ; #还原的最原始的状态 -- #创建触发器(向err_log表里插入最旧的记录) delimiter // create trigger tri_after_inser_cmd_log1 after delete on cmd_log for each row BEGIN if old.is_success = 'no' then insert into err_log(cname,stime) VALUES(old.cmd_name,old.sub_time); end if; #记得加分号,mysql一加分号代表结束,那么就得声明一下 END // delimiter ; #还原的最原始的状态 DELETE from cmd_log where id=1;
-- 触发器的两个关键字:new ,old -- new :表示新的记录 -- old:表示旧的那条记录 -- 什么情况下才往里面插记录 -- 当命令输入错误的时候就把错误的记录插入到err_log表中
测试
# 4.测试 insert into cmd_log(cmd_name,sub_time,user_name,is_success) values ('ls -l /etc | grep *.conf',now(),'root','no'), #NEW.id,NEW.cmd_name,NEW.sub_time ('ps aux |grep mysqld',now(),'root','yes'), ('cat /etc/passwd |grep root',now(),'root','yes'), ('netstat -tunalp |grep 3306',now(),'egon','no');
三、事务
-- 事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,
-- 即可回滚到原来的状态,从而保证数据库数据完整性。
-- 事务也就是要么都成功,要么都不成功
-- 事务就是由一堆sql语句组成的
准备表
create table user( id int primary key auto_increment, name char(32), balance int #用户余额 ); insert into user(name,balance) values('海燕',200), ('哪吒',200), ('小哈',200); -- 如果都成功就执行commit,,,如果不成功就执行rollback。 start transaction #开启事务 update user set balance = 100 where name = '海燕'; update user set balance = 210 where name = '哪吒'; update user set balance = 290 where name = '小哈'; #sql语句错误就会报错了 commit; #如果所有的sql语句都没有出现异常,应该执行commit start transaction update user set balance = 100 where name = '海燕'; update user set balance = 210 where name = '哪吒'; updatezzzz user set balance = 290 where name = '小哈'; #sql语句错误就会报错了 rollback; #如果任意一条sql出现异常,都应该回归到初始状态
上面的两种情况我们可以用异常处理捕捉一下


delimiter // create PROCEDURE p6( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN -- ERROR set p_return_code = 1; rollback; END; DECLARE exit handler for sqlwarning BEGIN -- WARNING set p_return_code = 2; rollback; END; START TRANSACTION; update user set balance = 100 where name = '海燕'; update user set balance = 210 where name = '哪吒'; update user11 set balance = 290 where name = '小哈'; COMMIT; -- SUCCESS set p_return_code = 0; #0代表执行成功 END // delimiter ; 捕捉异常+事务1
============捕捉异常+事务============== delimiter // create PROCEDURE p6( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN -- ERROR set p_return_code = 1; rollback; END; DECLARE exit handler for sqlwarning BEGIN -- WARNING set p_return_code = 2; rollback; END; START TRANSACTION; insert into test(username,dep_id) values('egon',1); DELETE from tb1111111; #如果执行失败,就不会执行commit了 COMMIT; -- SUCCESS set p_return_code = 0; #0代表执行成功 END // delimiter ; #调用 set @res = 111 #相当于定义一个全局变量 call p6(@res) select * from test; select @res 捕捉异常+事务
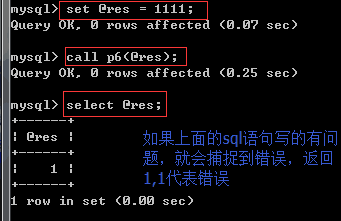
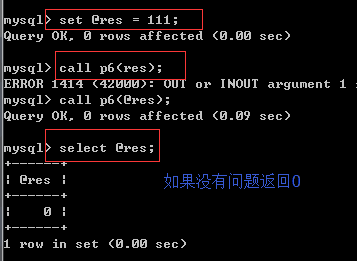
相当于python中 tyr...except
#用python模拟 try: START TRANSACTION; DELETE from tb1; #执行失败 insert into blog(name,sub_time) values('yyy',now()); COMMIT; set p_return_code = 0; #0代表执行成功 except sqlexception: set p_return_code = 1; rollback; except sqlwaring: set p_return_code = 2; rollback; 用python模拟
四、存储过程
存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql
-- 存储过程的优点: -- 1.程序与数据实现解耦 -- 2.减少网络传输的数据量 -- 但是看似很完美,还是不推荐你使用
===========创建无参的存储过程=============== delimiter // create procedure p1() begin select * from test; insert into test(username,dep_id) VALUES('egon',1); end // delimiter ; #调用存储过程 #在mysql中调用 call p1(); #在python程序中调用 cursor.callproc('p1')
对于存储过程,可以接收参数,其参数有三类: #in 仅用于传入参数用 #out 仅用于返回值用 #inout 既可以传入又可以当作返回值
==========创建有参的存储过程(in)=============== delimiter // create procedure p2( in m int, #从外部传进来的值 in n int ) begin insert into test(username,dep_id) VALUES ('haha',2),('xixi',3),('sasa',1),('yanyan',2); select * from test where id between m and n; end // delimiter ; #调用存储过程 call p2(3,7); #在mysql中执行 #在python程序中调用 cursor.callproc('p2',arg(3,7)) 创建有参的存储过程(in)
===========创建有参的存储过程(out)=============== delimiter // create procedure p3( in m int, #从外部传进来的值 in n int, out res int ) begin select * from test where id between m and n; set res = 1;#如果不设置,则res返回null end // delimiter ; #调用存储过程 set @res = 11111; call p3(3,7,@res); select @res; #在mysql中执行 #在python中 res=cursor.callproc('p3',args=(3,7,123)) #@_p3_0=3,@_p3_1=7,@_p3_2=123 print(cursor.fetchall()) #只是拿到存储过程中select的查询结果 cursor.execute('select @_p3_0,@_p3_1,@_p3_2') print(cursor.fetchall()) #可以拿到的是返回值 创建有参的存储过程(out)
=============创建有参存储过程之inout的使用========== delimiter // create procedure p4( inout m int ) begin select * from test where id > m; set m=1; end // delimiter ; #在mysql中 set @x=2; call p4(@x); select @x; =========================== delimiter // create procedure p5( inout m int ) begin select * from test11111 where id > m; set m=1; end // delimiter ; #在mysql中 set @x=2; call p5(@x); select @x; #这时由于不存在那个表就会报错,查看的结果就成2了。 创建有参存储过程之inout的使用