《Thinking in Java 》读书笔记-17
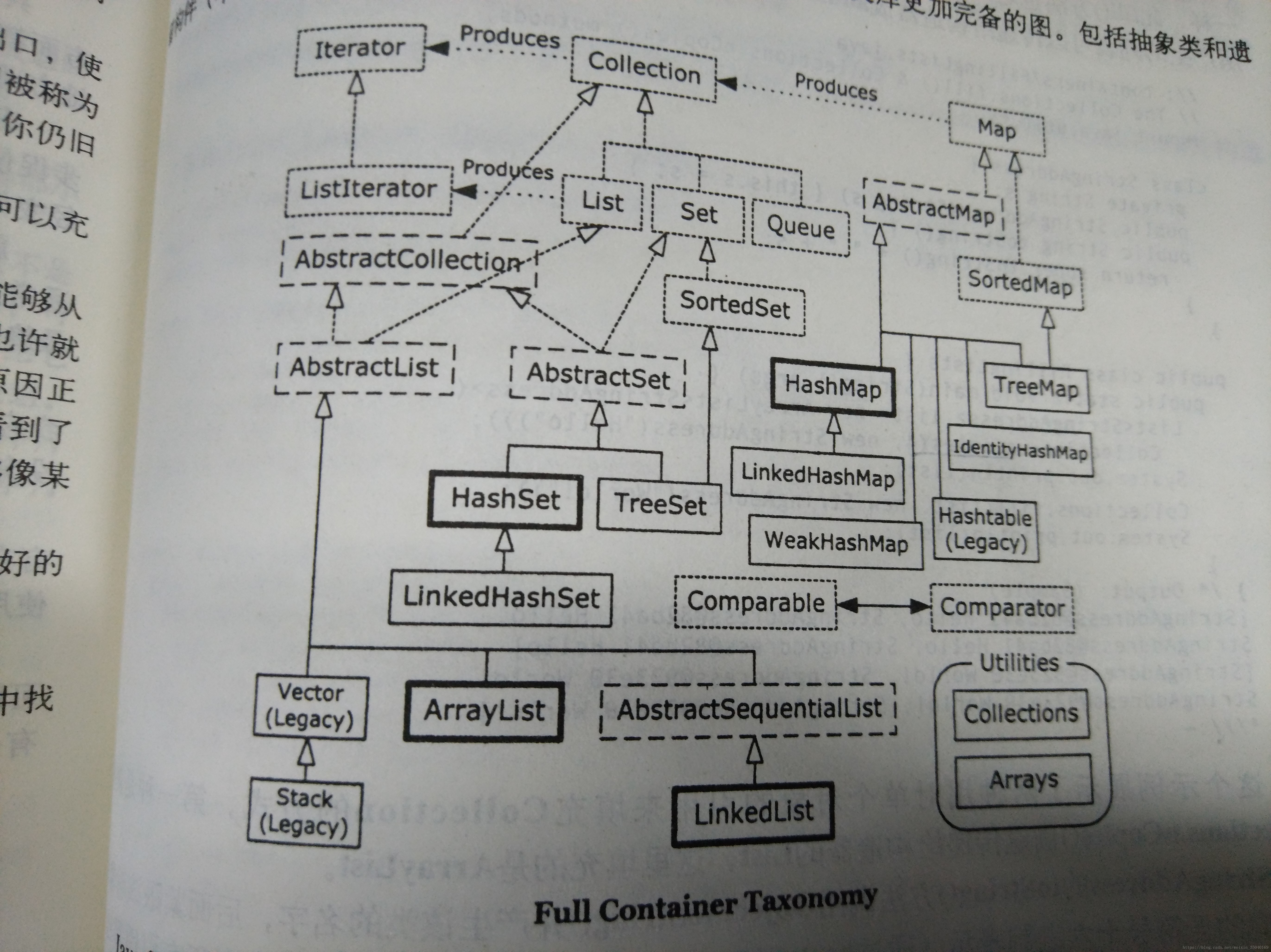
17.1 完整的容器分类法
17.2 填充容器
Collections.nCopies()和Collection.fill()都可以用单个对象的引用来填充Collection,并且所有引用都被设置为指向相同的的对象。
fill()方法的用处更为有限,它只能替换已经在List中存在的元素,而不能添加新的元素。
17.2.1 一种Generator解决方案
所有的Collection子类型都有一个接受另一个Collection对象的构造器。
17.2.2 Map生成器
未获支持的操作
17.2.3 使用Abstract类
17.3 Collection的功能方法
17.4 可选操作
执行各种不同的添加和移除的方法在Collection接口中都是可选操作。
使用Arrays.asList()生成的List,基于一个固定大小的数组,仅支持那些不会改变数组大小的操作。
17.5 List的功能方法
17.6 Set和存储顺序
接口 描述
| Set | 存入Set的每一个元素都必须是唯一的,因为Set不保存重复元素.加入Set的元素必须定义equals()方法以确保对象的唯一性. Set和Collection有完全一样的接口.Set接口不保证维护元素的次序. |
|---|---|
| HashSet * | 为快速查找而设计的Set.存入HashSet的元素必须定义HashCode()方法. |
| TreeSet | 保持次序的Set,底层为树结构.使用它可以从Set中提取有序的序列.元素必须实现Comparable接口 |
| LinkedHashSet | 具有HashSet的查询速度,且内部使用链表维护元素的顺序.于是在使用迭代器遍历Set时,结果会按元素插入的次序显示.元素也必须定义hashCode()方法. |
17.7 队列
17.7.1 优先级队列
17.8 理解Map
17.9 散列与散列码
散列的价值在于速度。我们使用数组来保存键的信息,这个信息并不是键本身,而是通过键对象生成一个数字(散列码),作为数组下标。由于数组的容量是固定的,而散列容器的大小是可变的,所以不同的键可以产生相同的数组下标(散列码)。也就是说,可能会有冲突(当然也有特例,比如EnumMap和EnumSet)。所以,数组的值存放着一个保存所有相同散列码的值的list(引用)。然后对list中的值使用equals进行线性查询。如果散列函数设计的比较好的话,数组的每个位置只有较少的值,并且浪费空间也小。于是,查询过程就是首先计算键的散列码得到数组下标,然后内存寻址(时间复杂度为O(1),赋值)找到数组的值,再遍历list(时间复杂度为O(n),线性查询)即可。即hashCode和equals共同确定了对象的唯一性。
所有类都继承于Object。Object的hashCode方法生成的散列码,实际上是默认使用对象的地址计算散列码;而Object的equals方法实际上就是地址比较(==)。显然,当我们在使用散列容器(如HashMap的Key,HashSet等)时,我们自定义的类中还继承Object的hashCode和equals是不行的。必须重写hashCode和equals方法。好的hashCode()应该产生分布均匀的散列码。
17.10 选择接口的不同实现
17.11 实用方法
17.12 持有引用
- SoftRefernce
- WeakRefernce
- PhantomRefernce
17.13 Java 1.0/1.1的容器
- 不要在新代码里使用Vector、Enumeration。
- 用LinkedLsit或基于LinlkedList的子类代替旧版的Stack。
- 如果拥有一个可以命名的固定的标志集合,那么EnumSet与BitSet相比是更好的选择。
- 只有在运行时才知道需要多少个标志,对标志命名不合理,需要BitSet中的某种特性操作。