前言
国土资源部在国家标准《地理空间数据交换格式》(GB/T17798-2007)基础上制定了土地利用数据交换格式,土地利用数据仅描述矢量数据,文件的后缀名为VCT,简称为 VCT 文件,通过该文件 来实现各类国土资源空间信息的交换。VCT矢量数据交换格式广泛应用于国土资源部门土地利用现状调查成果汇交、土地利用规划成果汇交和地籍调查数据库成果交换。VCT作为一种优秀的明码数据格式,能储存点、线、面、注记等几何信息,市面上也有很多软件能实现shp和vct互相转换的软件,最近因为项目需要,写了两个关于vct格式转换的自定义转换器,顺便分享一下开发思路。
一、VCT格式储存规则
VCT 文件由八部分组成: 第一部分为文件头,描述数据的基本信息,如数据范围、坐标维数、比例尺等;第二部分为要素类型参数;描述数据中包含的层要素;第三部分为属性数据结构,描述各层要素对应的属性数据结构;第四部分为图形数据,描述各层要素对象的几何图形数据;第五部分为注记,描述具有文本标注的数据;第六部分为拓扑数据,描述几何图形拓扑关系的数据;第七部分为属性数据;第八部分则为图形表现数据。
第一部分为文件头 :头文件以HeadBegin开始,以HeadEnd结束,其中 Version: 表示 VCT 文件的版本号,用1.0、2.0、3.0表示。
第二部分为要素层类型参数 :以 FeatureCodeBegin 开始,以 FeatureCodeEnd 结束。三个版本均支持点、线、面、注记图层的配置,点、线、面、注记为四个字段类型,第1字段:要素类型编码;第2字段:要素类型名称;第3字段:图层类型;
第三部分为属性数据结构 :描述各层要素对应的属性数据结构.属性数据结构以 TableStructureBegin 开始,以 TableStructureEnd 结束。其中,第一行第一个字段为 属性项个数,如(XZQ,6),即
行政区属性表有6个属性字段

第四部分为图形数据 :描述各层要素对象的几何图形数据。图形数据可分为点状图形数据、线状图形数据和面状图形数据,第一行字段为标识码:每个要素以对象标识码为起始标志,且点、线、面三类要素的“标识码”不得重复。第二行字段为要素代码:在图形数据结构中已经定义的,从其定义;未定义的显示“Unknow”。第三行字段为层名:在图形数据结构中已经定义的,从其定义;未定义的显示“Unknow”。第四行字段为图形要素特征类型:点、线、面的要素特征类型各不相同。点的特征类型:1|2|3,1表示独立点,2表示结点,3表示有向点。线的特征类型1|2|3|4|5|6|100,1表示折线、2表示圆弧、3表示园、4表示椭圆、5表示光滑曲线、6表示B样条曲线、100表示间接坐标。在土地利用矢量数据交换格式中,线要素采用直接坐标描述。
线状图形数据的第五行对象点数,其下依次为点坐标。
面状图形要素描述:不同的面状特征类型,数据的表达形式不同。面状特征类型:1和100,其中1表示由直接坐标表示的面对象,100表示由间接坐标表示的面对象。间接坐标面的构成类型:21和22,21表示间接坐标面引用线表示面对象图1,22表示间接坐标面引用面表示面对象如图2。直接坐标面即用折线的点坐标直接表示面对象,无引用,如下图所示。
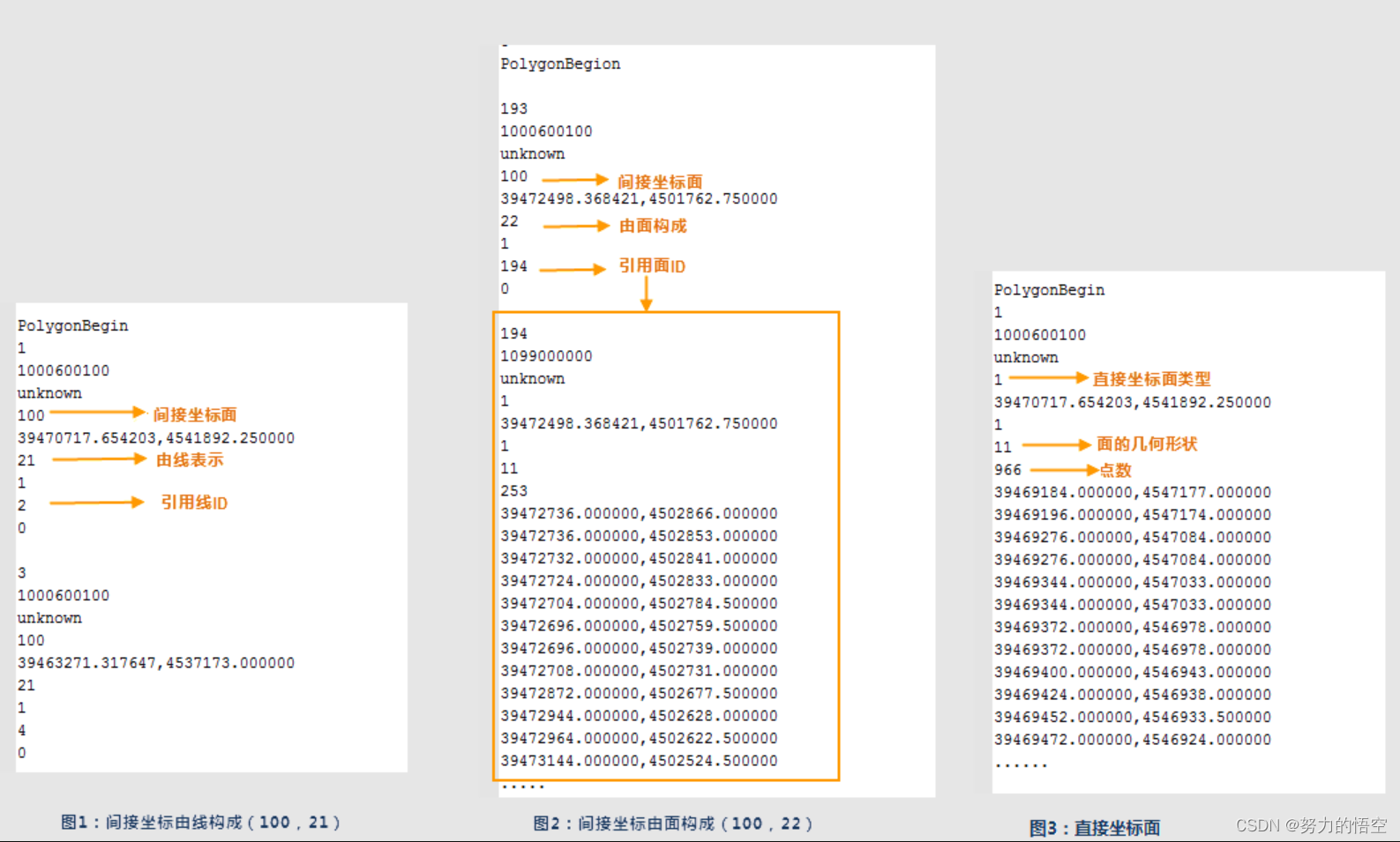
第五部分为注记要素 :以 AnnotationBegin 开始,以 AnnotationEnd 结束标志集中存储在注记数据段,第一行为对象标识码,第二行表示要素类型编码,第三行为图形表现编码,第四行为注记的特征类型,特征类型由1和1表示,其中1表示单点注记,2表示多点注记。
第六部分为属性要素 :以 AttributeBegin 开始,以AttributeEnd 结束标志集中存储属性数据段,属性数据段可以包含多个属性表,每个属性表以属性表名起始标志,以TableEnd为属性表数据结束标志。

第七部分为图形表现数据 :以StyleBegin 和 RepresentationBegion 为起始标志,以StyleEnd 和 RepresentationEnd 结束标志集中图形表现数据段。
二、开发思路
1.VCT格式读取
想必写出,VCT格式读取相对来说更为简单,因为不需要考虑细节,只需要把文本中的需要部分提取出来组合为对应数组即可。需要注意的是,为保证储存空间,大部分面要素是采用21,也就是以间接坐标面引用线表示面。

比如该面要素,最后一行则是储存的前面线要素的索引,如果索引带负号则说明需要将该线换方向。其实在fme中我们可以通过AreaBuilder转换器来将线索引直接构面,可以不用考虑线方向。模板如下:

txt的解析主要还是用的python,为了保证转换性能,我将属性和图形分了两个转换器单独构造,然后通过FeatureJoiner关联,这里说一下为什么使用FeatureJoiner而不是FeatureMerger,因为属性和图形的索引都是唯一值,所以不管是FeatureJoiner还是FeatureMerger效果都是一样的,但是因为FeatureJoiner是非阻塞转换器,意味着可以和其他转换器开启多线程运行,计算速度会更快。
2.VCT格式写出
将fme要素写出为VCT的难度则要比写入大非常多,作者完成VCT读取转换器可能只花了2天时间完善,但是写出大概研究了一周多时间。主要技术难点有以下几点:
1、属性表结构获取
fme有个缺陷,就是没办法在模板过程中自动暴露字段,所有的字段暴露都是需要手动添加的。如果字段没有暴露出来,那么如果某个要素的字段值是MISS,则该要素在pythoncaller中用fmeobj类方法获取字段值则无法获取,这样就会导致字段不一致。这里我采用了FeatureReader读取,并
选择single output port读取方式。

这样读取则可以获得数据库的所有属性表schema,这里就有需要的字段类型和字段长度等信息了。只需要在python中组织一下,则可以将其输出为标准VCT结构。
2、面文件构造
虽然面文件读取不需要废多大功夫,但是写面文件则非常麻烦了,需要将面按拓扑规则打散成线,然后统一赋予标识码,再计算线方向,给与每个线正负号,最后将线索引以字符串串联起来。
以下是处理面属性的模板。

这里使用了LineOnLineOverlayer这个转换器将面打散成对应线段

打散之后用python代码进行线顺序,线方向判定,这里我是用了比较笨的逻辑,先根据面id分组遍历所有线段,取每条线的首位节点,来判定下一条线的归宿,如果下一条线是坐标相同的尾节点,则下一条线是负号,然后递归列表-1,剩下的线段按照次逻辑继续遍历。当然环岛和聚合体要提前标记。这样通过3层循环,一次递归,来完成线索引的计算。部分代码如下图:

最终得到结果

3、属性写出
一开始我把属性写出想的比较简单,只需要分组导出即可,但是如果是在pythoncaller中就很麻烦了,因为input函数会把所有要素遍历,如果是把所有要素集合为一个list放到close函数中做分组处理则需要用到pandas的group,考虑到要封装为自定义转换器,所以不打算引入第三方库,还好FME2021的pythoncaller有分组功能,将要素按图层分组写出list,在process_group函数中分组执行。完美的实现了属性表的写出
def process_group(self):
path=FME_MacroValues['vct写出路径']
path=path.replace("/","\\")
with open(path, "a+",encoding="ansi") as f:
f.write(self.tablename)
f.write("\n")
for a in self.lines:
f.write(str(a)+"\n")
f.write("TableEnd")
f.write("\n")
f.write("\n")剩下的点、线都比较简单,就是单纯的写出坐标串。这里就不赘述了,实际也就只花了几行代码而已。
效果展示
自定义转换器VctFeatureReader,将vct按点线面要素输出,

输出后会自动暴露几个关键字段,VCT索引值,要素代码和图层名,其他属性则写出为隐藏属性,需要手动暴露。

自定义转换器VctFeatureReader,可以实现各类矢量数据,导出为vct格式,目前支持shp、gdb、mapinfo、mdb等主流数据格式。

只需要设置好容差和写出路径即可
完美的转换为了VCT3.0格式


总结
第一次捣鼓底层数据格式,还是花费了不少时间,后期会考虑脱离FME环境,用C++结合gdal库来写数据格式转换,当然这个工作量和实现难度就更大了。