1.虚拟机安装centos7(网上可以百度,各种教程,此处忽略)
2.修改主机名(同时修改3台机器)
[root@promote ~]# vim /etc/hostname
# 主机名
hadoop001
[root@promote ~]# hostname hadoop001
[root@promote ~]# hostname
hadoop001
3.修改hosts
[root@promote ~]# vim /etc/hosts
## 添加
192.168.1.13 hadoop001
192.168.1.14 hadoop002
192.168.1.15 hadoop003
[root@promote ~]# scp /etc/hosts 192.168.1.14:/etc
[root@promote ~]# scp /etc/hosts 192.168.1.15:/etc
4.配置免密登陆
[root@promote ~]# ssh-keygen -t rsa
# 一路回车即可
[root@promote .ssh]# cat id_rsa.pub >> authorized_keys
# 其他2台机器也是这样,最后只需要将每台机器的公钥添加到其他机器的authorized_keys即可
[root@promote .ssh]# scp authorized_keys 192.168.1.14:$PWD
[root@promote .ssh]# scp authorized_keys 192.168.1.15:$PWD
## 修改authorized_keys权限
[root@promote .ssh]# chmod 600 authorized_keys
5.创建hadoop用户(建议用hadoop用户安装)
[root@hadoop001 ~]# useradd -m hadoop -s /bin/bash
[root@hadoop001 ~]# passwd hadoop
#修改sudoer
[root@hadoop001 ~]# visudo
#增加管理员权限
hadoop ALL=(ALL) ALL
# 同上。hadoop用户也要创建免密登录
6.关闭SELinux
[root@hadoop001 hadoop-2.9.2]# vi /etc/selinux/config
SELINUX=disabled
7.关闭防火墙
[root@hadoop001 hadoop-2.9.2]# systemctl status firewalld
[root@hadoop001 hadoop-2.9.2]# systemctl stop firewalld
[root@hadoop001 hadoop-2.9.2]# systemctl disable firewalld
8.同步时间
[root@hadoop001 hadoop-2.9.2]# yum install -y ntpdate
[root@hadoop002 ~]# ntpdate cn.pool.ntp.org
9.安装jdk1.8(安装文件官网一堆)
[root@hadoop001 ~]# mkdir /usr/local/java/
[root@hadoop001 ~]# tar -zxvf jdk-8u251-linux-x64.tar.gz -C /usr/local/java/
[root@hadoop001 ~]# chown root:root -R /usr/local/java/jdk1.8.0_251/
[root@hadoop001 ~]# vim /etc/profile
#增加如下配置
export JAVA_HOME=/usr/local/java/jdk1.8.0_251
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
[root@hadoop001 java]# source /etc/profile
10.安装hadoop2.9.2(安装文件自行下载)
#创建安装目录
[root@hadoop001 ~]# mkdir /usr/local/cluster
#解压到安装目录下
[root@hadoop001 ~]# tar -zxvf hadoop-2.9.2.tar.gz -C /usr/local/cluster/
#赋权给hadoop用户
[root@hadoop001 ~]# chown hadoop:hadoop -R /usr/local/cluster/hadoop-2.9.2/
#hadoop用户创建数据目录
[hadoop@hadoop001 ~]$ sudo mkdir /opt/data
[hadoop@hadoop001 /]$ sudo chown hadoop:hadoop /opt/data/
11.修改配置文件
#hadoop-env.sh 修改JAVA_HOME
export JAVA_HOME=/usr/local/java/jdk1.8.0_251
scp hadoop-env.sh hadoop002:$PWD
scp hadoop-env.sh hadoop003:$PWD
#--------------------------------
#core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9000</value>
</property>
scp core-site.xml hadoop002:$PWD
scp core-site.xml hadoop003:$PWD
#------------------------------
#hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
scp hdfs-site.xml hadoop002:$PWD
scp hdfs-site.xml hadoop003:$PWD
#-------------------------------
#mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
scp mapred-site.xml hadoop002:$PWD
scp mapred-site.xml hadoop003:$PWD
#--------------------------------
#yarn-site.xml
<property>
<name>yarn.resouremanager.hostname</name>
<value>hadoop001</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop001:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop001:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop001:8031</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
<description>可分配的物理内存总量</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
<description>NodeManager总的可用虚拟CPU个数</description>
</property>
scp yarn-site.xml hadoop002:$PWD
scp yarn-site.xml hadoop003:$PWD
#--------------------------------
#slaves
hadoop001
hadoop002
hadoop003
scp slaves hadoop002:$PWD
scp slaves hadoop003:$PWD
12.配置Hadoop环境变量
vim /etc/profile
export HADOOP_HOME=/usr/local/cluster/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
13.格式化hdfs目录
[hadoop@hadoop001 ~]$ hdfs namenode -format
14.启动/停止集群
#启动hdfs
[hadoop@hadoop001 ~]$ start-dfs.sh
#停止hdfs
[hadoop@hadoop001 sbin]$ stop-dfs.sh
#启动yarn
[hadoop@hadoop001 sbin]$ start-yarn.sh
#停止yarn
[hadoop@hadoop001 sbin]$ stop-yarn.sh
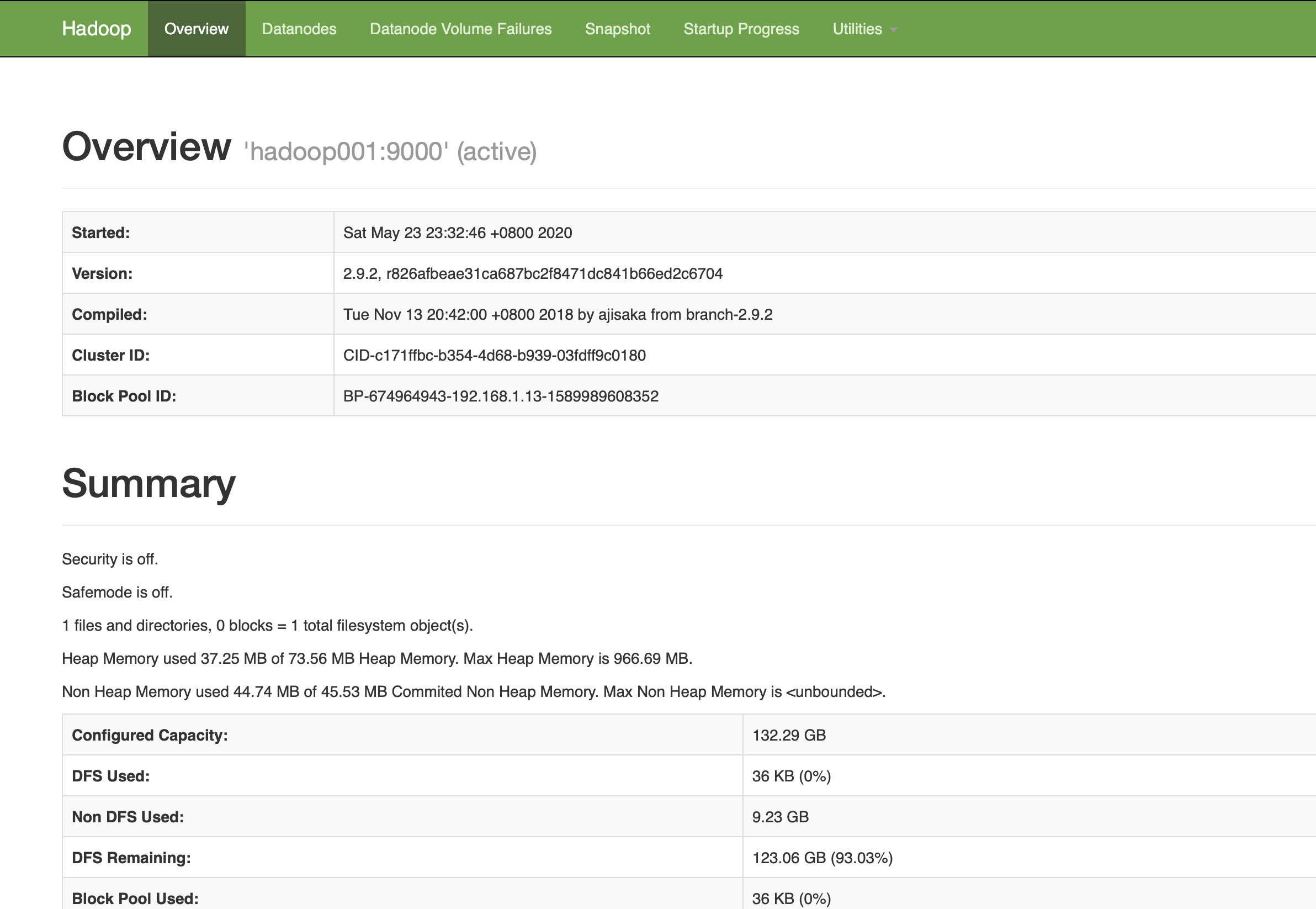
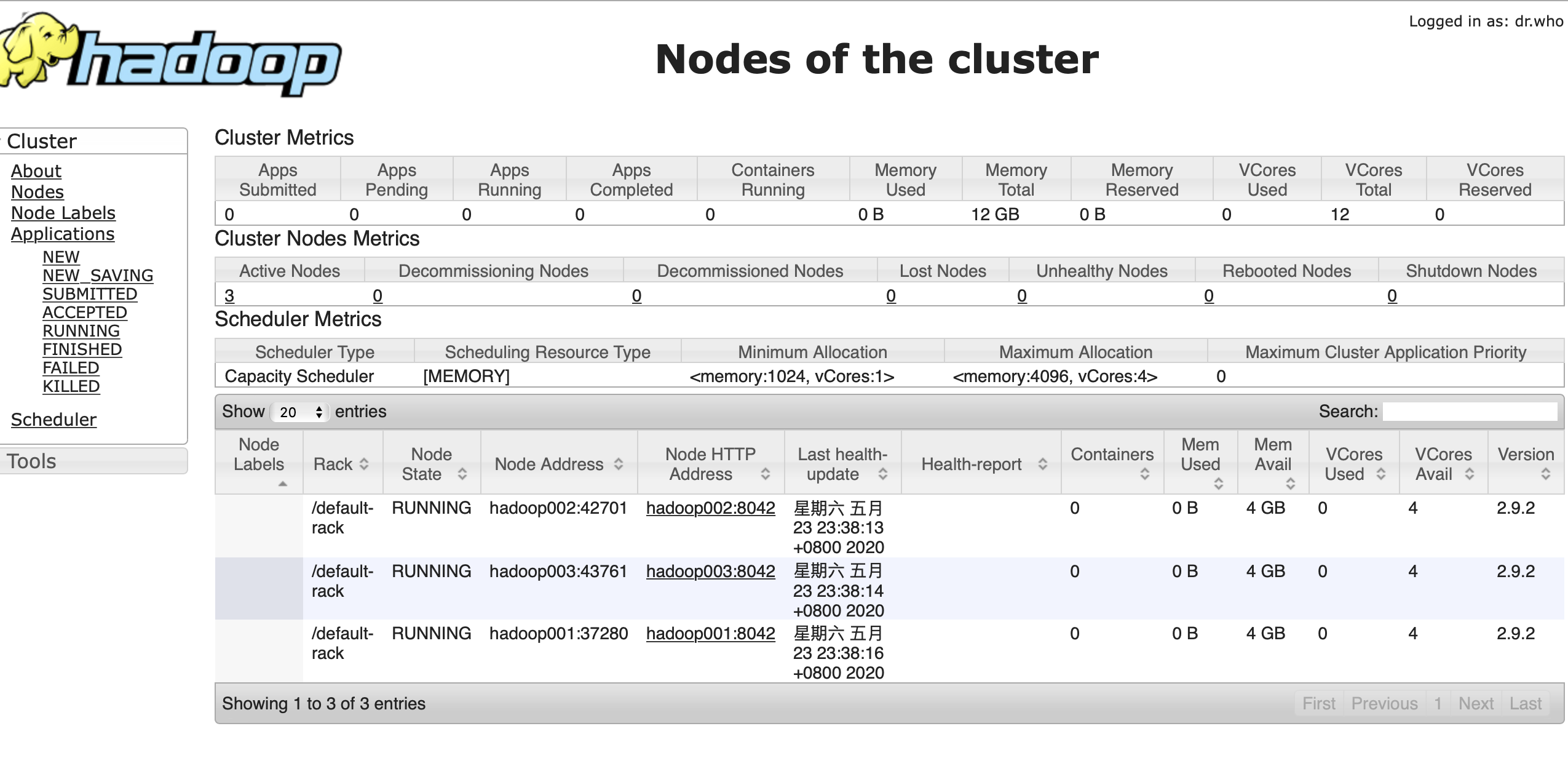
15.界面查看