目录
结构
scrapy是一个框架,要想写出第一个scrapy程序,那么就得先了解这个框架是由哪些组件构成的,这些组件又有什么作用。
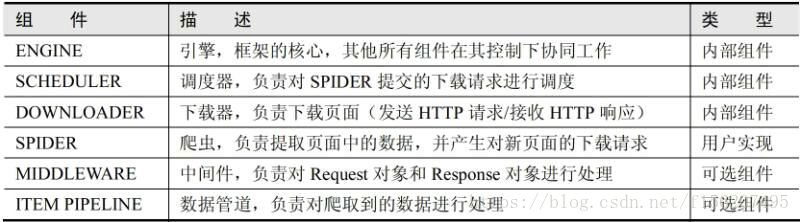
看一下这些组件详细的工作流程图
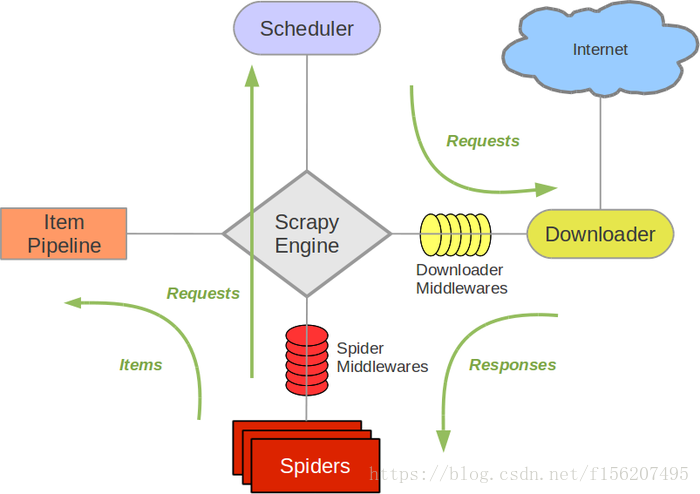
这些组件是如何配合的可以参考一下组件结构,我就不费笔墨了。
那么了解了scrapy的大致工作流程之后,如何开始写好第一个scrapy程序呢???
第一个scrapy的思路
既然是第一个,那就写得简单点。不考虑太多,通过回答下面三个问题开始理清思路。
- 爬虫从哪个或者哪些页面开始爬取?
- 对于一个已经下载的页面,需要提取其中哪些数据?
- 爬取完当前页面后,接下来爬取哪些页面?
目标页面:http://books.toscrape.com/
爬取目标:爬取该网站所有书本的信息(具体是哪些信息自己决定,这里选取书名和库存量)。
代码实现:
首先创建一个scrapy项目,
输入命令:scrapy startproject books
在spiders文件中新建一个爬虫文件,spider.py
spiders.py
import scrapy
class BooksSpider(scrapy.Spider):
name = "start"
start_urls = ["http://books.toscrape.com/"]
# 解析函数
def parse(self, response):
for book in response.css('article.product_pod'):
# 解析出书名
name = book.xpath('./h3/a/@title').extract_first()
yield{
'name':name,
}
# 解析出下一页的url
next_url = response.css('ul.pager li.next a::attr(href)').extract_first()
# 如果还有下一页,则用Request请求发出
if next_url:
next_url = response.urljoin(next_url)
yield scrapy.Request(next_url , callback=self.parse)如果将
yield{
'name':name,
}
改成
yield name
则会出现错误

也就是yield 只能返回Request请求,Item,dict数据,或者返回None。 返回Request会被引擎发送给Downloader组件,返回Item或者dict会被引擎发送给Item pipeline组件。
核心代码解读
name = 'start'
在一个scrapy中可以实现多个Spider,每个Spider需要被区分,于是Spider类的属性name起到了标识的作用,执行scrapy crawl name时,name就告诉了scrapy用哪个Spider去实现。
start_urls = ["http://books.toscrape.com/"]
start_urls是Spider类里面的属性,定义起始爬取点,它通常被实现成一个列表,其中放入所有起始爬取点的url。
可是我们都没有发送Request请求,为什么仅仅在start_urls里面放入url就能运行呢???看一下Spider的源码我们就明白了,
#该方法将读取start_urls内的地址,并为每一个地址生成一个Request对象, 并返回这些对象的迭代器
#该方法金调用一次
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
#start_requests()中调用,实际生成Request的函数。
#Request对象默认的回调函数为parse(),提交的方式为get
def make_requests_from_url(self, url):
return Request(url, dont_filter=True)
#默认的Request对象回调函数,处理返回的response。
#生成Item或者Request对象。用户必须实现这个类
def parse(self, response):
raise NotImplementedError
scrapy会自动地调用一次start_requests,仅仅只调用一次。
如果我们想为Request请求添加特定的HTTP头部,或者指定解析函数,则可以重写start_requests方法。
小结
name属性:是用来标识scrapy项目中的Spider,因为一个scrapy中可能有多个Spider
start_urls属性:是用来存放爬取起始点的url,如果使用start_urls,则不需要重写start_requests方法。如果有特定的需求,可重 写start_requests方法
parse函数:起解析response作用,可手动实现其他解析函数。解析函数需要完成两项任务,一是提取页面数据,以item或者字典的形式提交给scrapy引擎;二是使用选择器或者LinkExtractor提取页面中的url,用提取出来的url构造新的Request并提交给引擎。