本篇介绍如何使用matlab产生一套回声消除所需要的实验数据,以及验证数据
(本博文只是为了验证回声消除,假设了一个经过处理的信号时回声,标准的回声模型见另一篇博文G.168 标准回声模型)
实验数据产生思路:
1】首先要有一个原始的哈利路亚语音信号,这个信号用来模拟MIC端讲话人的语音
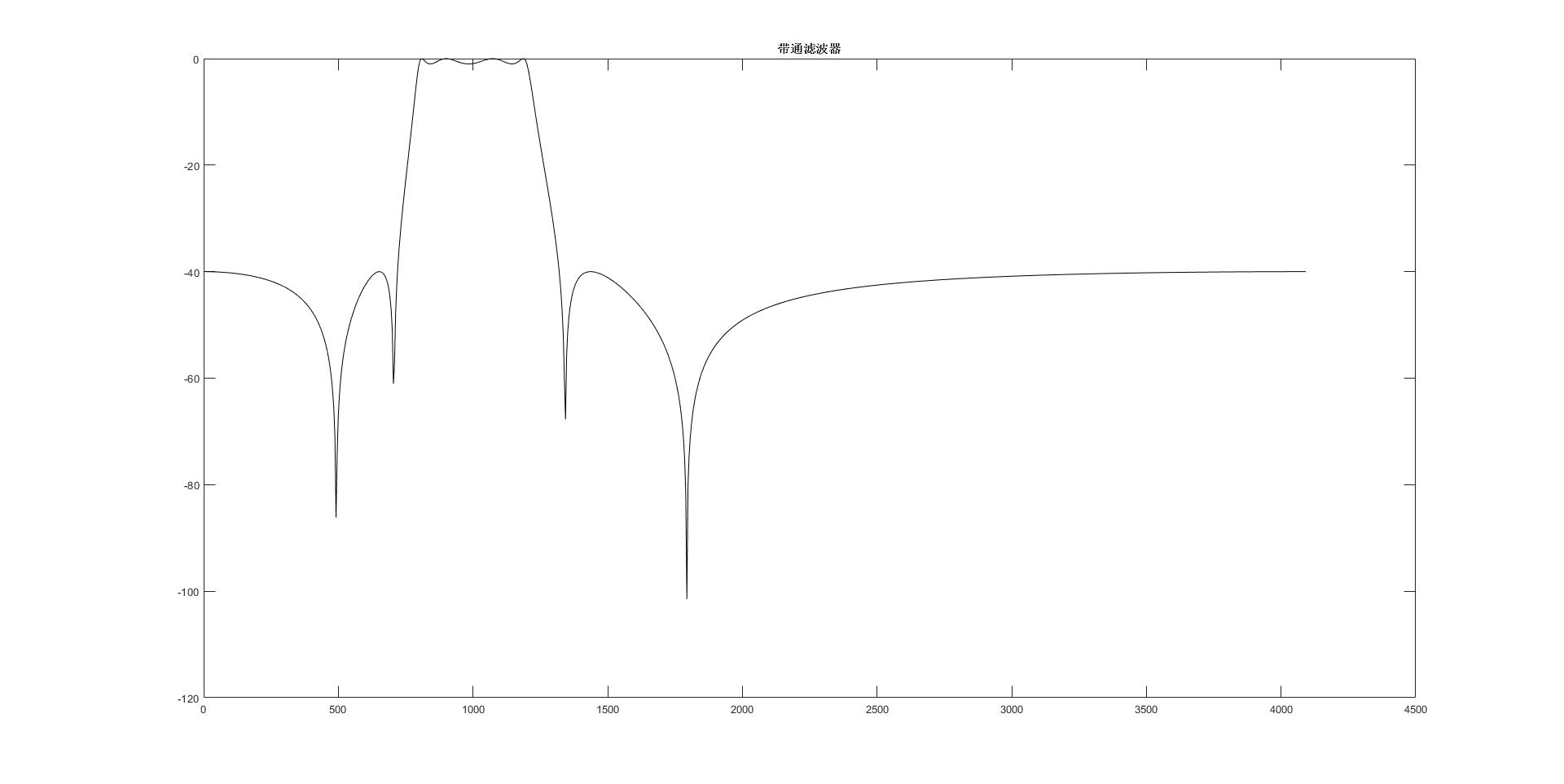
2】建立一个带通滤波器用来模拟SPK到MIC的传输过程,因为带通滤波器是一个是不变系统,所以在后续回声消除的实验中只需要开始时候权值收敛,后续不需要跟踪回声通道的变化
3】一个随机的杂波,用来模拟喇叭播放的声音
4】喇叭的原声经过带通滤波器后产生一个模拟的回声,这个回声与哈利路亚语音信号相加,得到一个MIC端采集的期望信号
具体实现代码如下
clear all
close all
clc
[voice,fs1]=audioread('handel.wav');
Sspk=randn(1,73113)/5;
% 回声通道设计
Fs2=fs1/2; % 奈奎斯特频率
wp=[800 1200]/Fs2;
ws=[600 1400]/Fs2; % 通带和阻带
Rp=1; Rs=40; % 通带波纹和阻带衰减
[M,Wn]=ellipord(wp,ws,Rp,Rs); % 求原型滤波器阶数和带宽
[B,A]=ellip(M,Rp,Rs,Wn); % 求数字滤波器系数
% 产生回声开始
SspkBypass=filter(B,A,Sspk);
SspkBypassFlipud=flipud(SspkBypass);
SspkBypassFlipudByPass=filter(B,A,SspkBypassFlipud);
Secho=flipud(SspkBypassFlipudByPass)*3; % 模拟实际产生的回声
% 产生回声结束
MICin=voice+Secho'; % 模拟MIC采集到的期望信号
audiowrite('哈利路亚原声.wav',voice,fs1,'BitsPerSample',16);
audiowrite('喇叭原声.wav',Sspk,fs1,'BitsPerSample',16);
audiowrite('喇叭回声.wav',Secho,fs1,'BitsPerSample',16);
audiowrite('MICin的期望信号.wav',MICin,fs1,'BitsPerSample',16);
figure
subplot(2,1,1)
plot(Sspk)
hold on
plot(Secho);
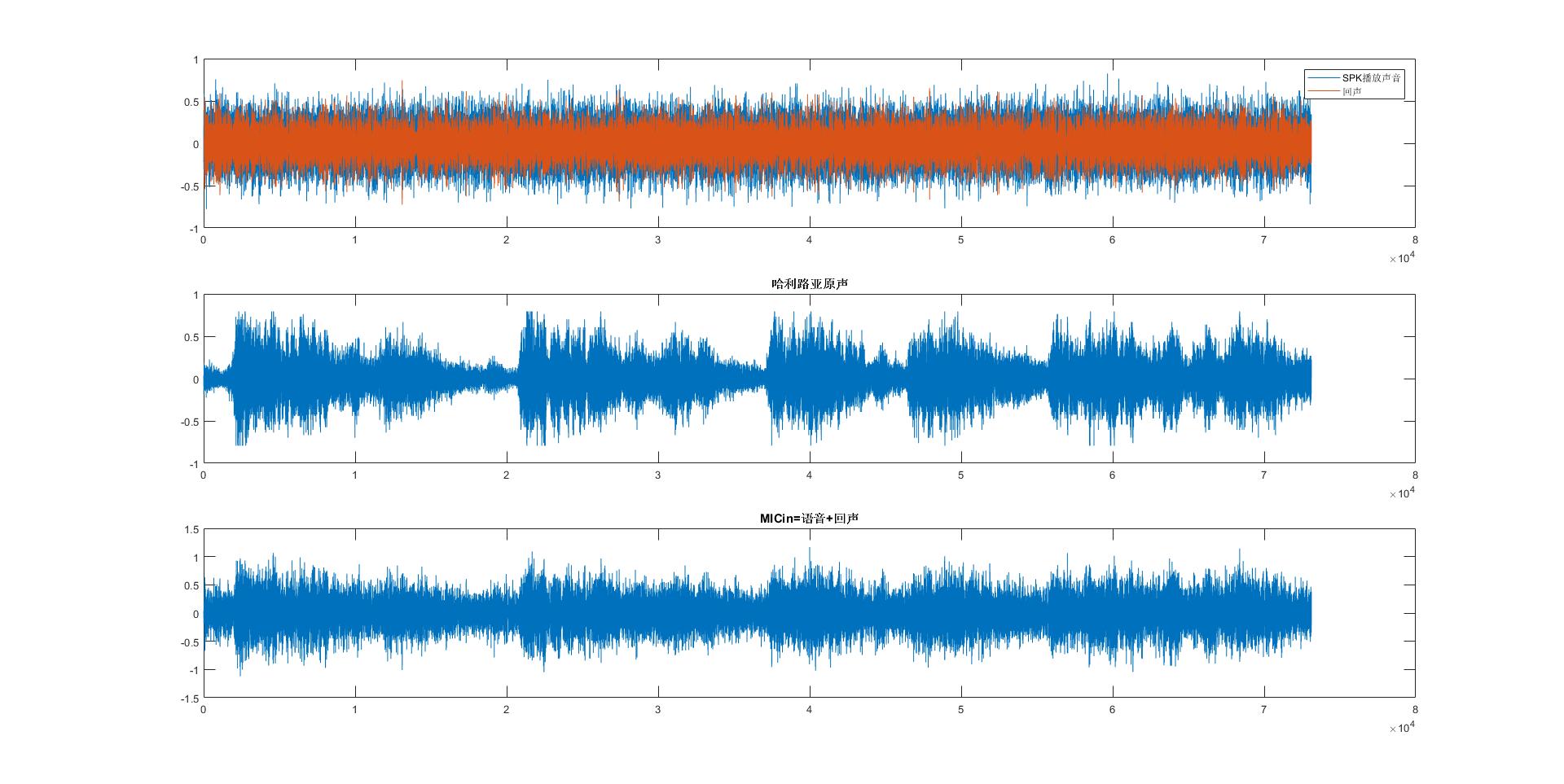
legend('SPK播放声音','回声');
subplot(2,1,2);
plot(MICin);
title('MICin=语音+回声')
sound(Secho,fs1);
pause(10);
sound(voice,fs1);
pause(10);
sound(MICin,fs1);
pause(10);执行结果,产生四个语音文件存放于Matlab的数据存放路径、播放生成的声音文件、绘制音频的波形
运行以上代码完毕后,产生实验所需要的准备数据,使用前面博客中提到的LMS滤波器对MICin中的数据进行分离,期望将MICin中的哈利路亚语音提取出来
clc
clear all
close all
[voice,fs1]=audioread('哈利路亚原声.wav');
[Sspk,fs2]=audioread('喇叭原声.wav');
[Secho,fs3]=audioread('喇叭回声.wav');
[MICin,fs4]=audioread('MICin的期望信号.wav');
figure;
subplot(2,1,1);
plot(Sspk);
axis([0 inf -1.5 1.5]);
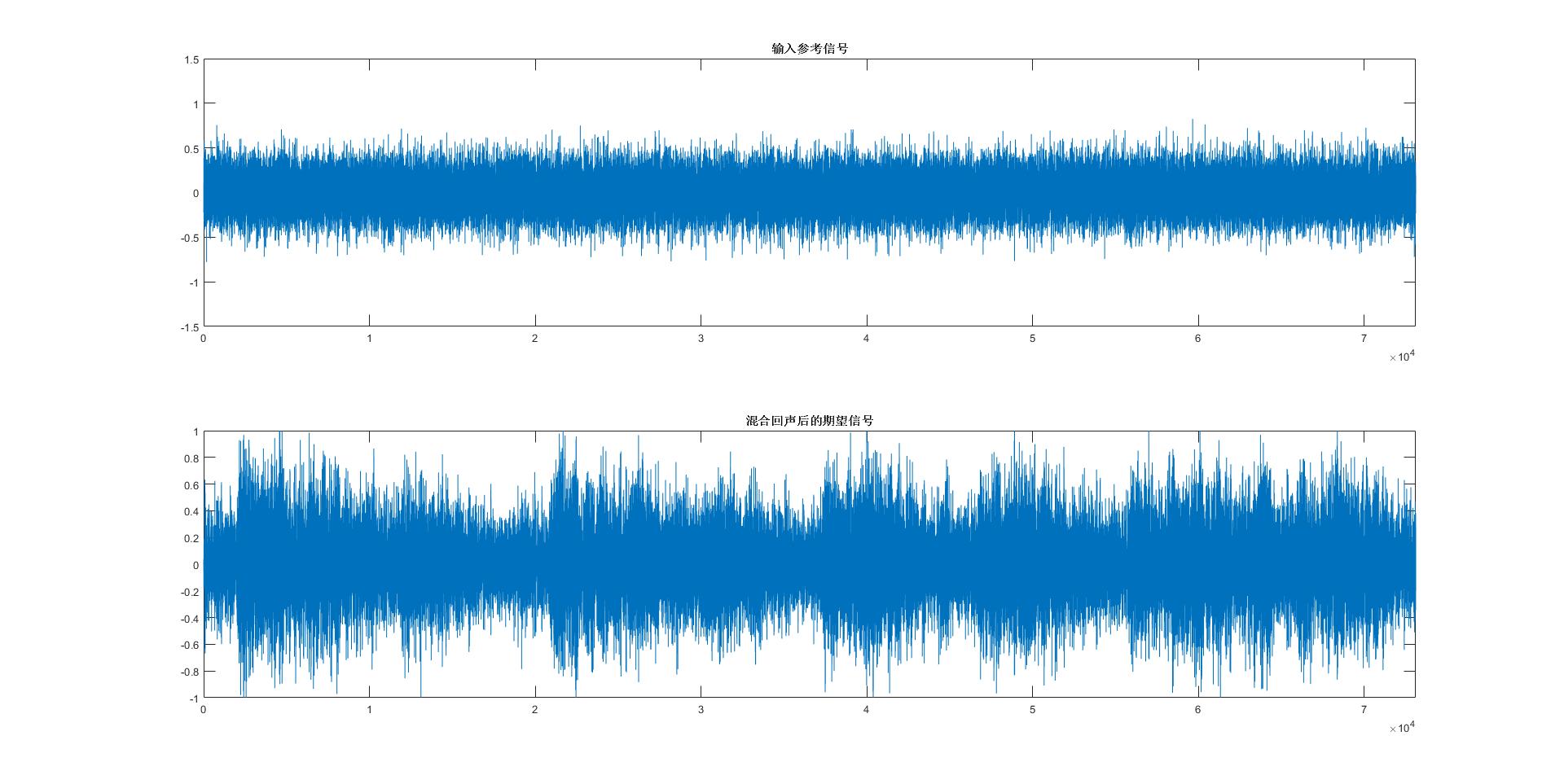
title('输入参考信号');
subplot(2,1,2);
plot(MICin);
axis([0 inf -1 1]);
title('混合回声后的期望信号');
n=max(size(Sspk)); % 信号中的1000个时间点
P=2; % LMS算法重复运算5次,用于评估五次运算产生的误差的平均水平
e=zeros(1,n); % 用于存放误差
ep=zeros(1,n); % 用于存放五十次运算累积的误差
ee=zeros(1,n); % 用于存放平方差
% x=zeros(1,n)'; % 滤波器产生的输出信号,为什么不用randn直接产生一个随机信号呢?效果应该是一样的
w=randn(1,n)'; % 产生一个随机信号用作参考,然后用x来拟合这个信号,并用前两个点初始化滤波器第一组权向量
%算法
h=waitbar(0,'计算进度');
steps = P;
for p=1:P
L=200; % 滤波器阶数,考虑到两个信号之间没有延时,且这里只是用来分离出输入的x信号,而且误差不做要求,因此不需要设置太高的阶数
u=0.0022; % 增益常数
wL=zeros(L,n); % 产生一个权向量矩阵
for i=(L+1):n % 计算权向量矩阵中第三组权向量到最后一组权向量相关的变量,根据x和e=x-y求下一个y,没有d(n)
X=Sspk(i-L:1:(i-1)); % 更新滤波器的参考矢量X(n)
y(i)=X'*wL(:,i); % 根据x计算i时刻输出信号
e(i)=MICin(i)-y(i); % 计算i时刻误差信号
wL(:,(i+1))=wL(:,i)+2*u*e(i)*X; % 更新i时刻滤波器的权向量
ee(i)=e(i)^2; % 更新平方差
end
ep=ep+ee; % 平方差累积
waitbar(p/steps);
end
close(h);
eq=ep/P; % 五十次重复计算平方差求均值
a1L=-wL(2,1:n); % a1在LMS算法下值的变化,wL矩阵中第一行的1到n个数,权向量矩阵第一行
a2L=-wL(1,1:n); % a2在LMS算法下值的变化 ,wL矩阵中第二行的1到n个数,权向量矩阵第二行
%画图
figure;
subplot(3,2,1);
plot(Sspk);
hold on
plot(y);
axis([0 inf -1.5 1.5]);
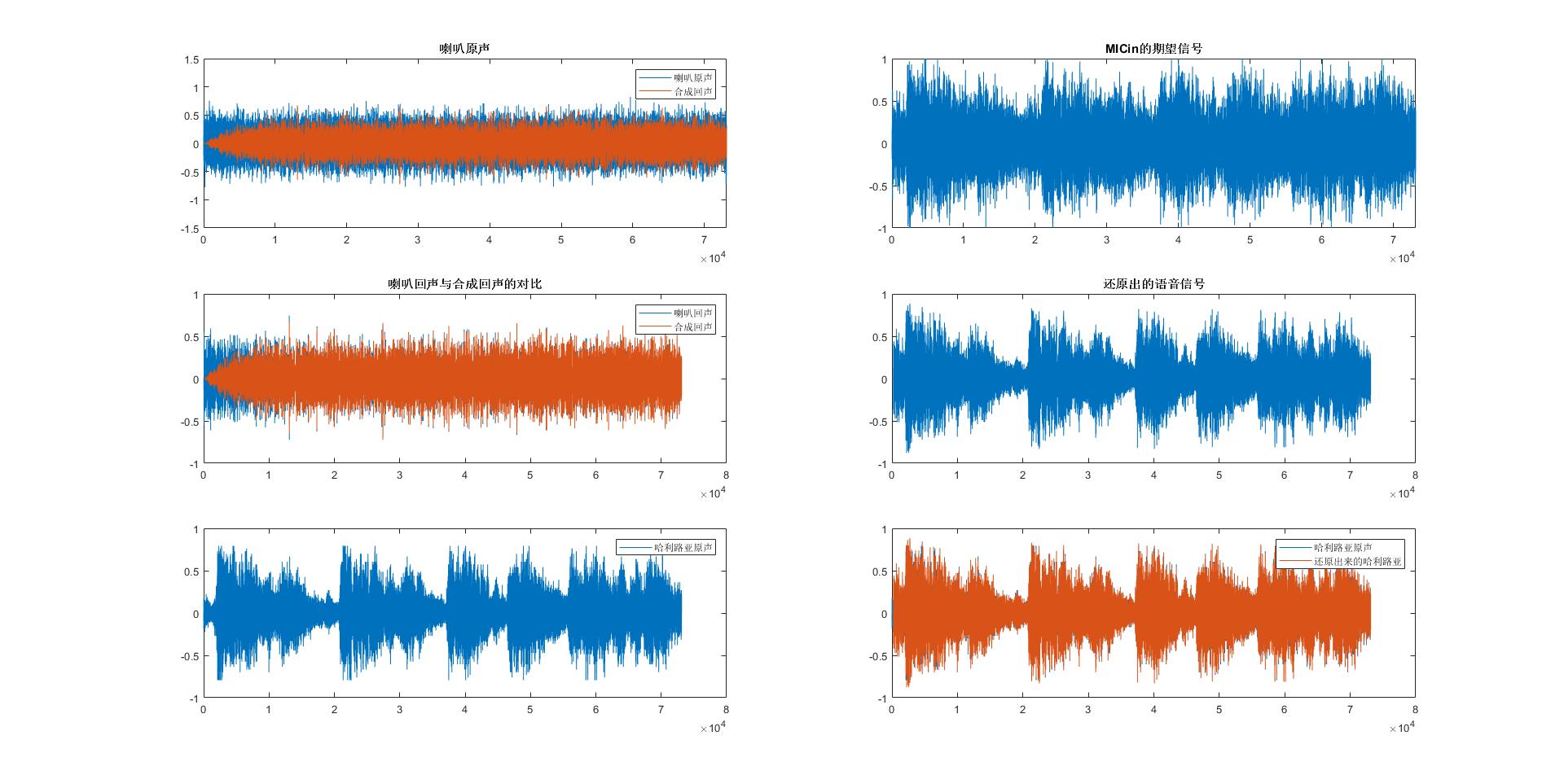
legend('喇叭原声','合成回声');
title('喇叭原声'); % 根据w产生的随机信号x
subplot(3,2,2);
plot(MICin);
axis([0 inf -1 1]);
title('MICin的期望信号');
subplot(3,2,3);
plot(Secho);
hold on
plot(y);
legend('喇叭回声','合成回声');
title('喇叭回声与合成回声的对比'); % 根据w产生的随机信号x
subplot(3,2,4);
plot(e);
title('还原出的语音信号'); % 五十次运算误差求均值
subplot(3,2,5);
plot(Secho);
hold on
plot(y);
legend('SPK回声信号','合成SPK回声信号')
subplot(3,2,6);
plot(voice);
hold on;
plot(e);
legend('哈利路亚原声','还原出来的哈利路亚');
sound(MICin,fs1)
pause(10)
sound(e,fs1);执行以上代码,播放回声消除后的音频文件、绘制音频数据波形