任何可以传输IP报文的技术,都可以用于组建Calico网络的交换结构,比如MPLS和以太网技术。
1 经典以太网在规模上遇到瓶颈
近些年业界的一个共识:当网络达到一定规模,经典以太网络已经不适合在生产环境部署了。大规模网络以太网故障的主要原因是:
- 大量的终端(end points)。每一个以太网交换机,必须学习去往同一个广播域内所有终端的路径,当终端的数量是带到十万级规模,就会成为一个十分困难的任务。
- 网络中高频率的翻动(churn)。私有云网络中大部分的终端是临时性的(比如虚机或者容器),存在大量的翻动(批量创建、删除虚拟机/容器,以及迁移带来的重复地址学习),学习这些路径信息会对大部分以太网交换机的控制平面处理机造成严重负担。
- 大量的广播流量。以太网中的终端依靠广播包去发现对等体及实现其他目的,这将导致每个数据包都会被复制给其它终端,造成广播风暴。
- 生成树。生成树是在以太网中防止环路的一种协议。它是在网络规模很小结构很简单的时代被设计出来。随着以太网络中链路和互联关系的增长,生成树协议变得十分脆弱。当以太网中的生成树失效时,将引起灾难性的结果,且难以排除和解决。
2 Calico如何改变经典以太网运行方式
Calico是如何被应用在二层以太网互联网络中的。最重要的是:以太网中是看不到直连IP路由器另一端的任何东西,它只能看到路由器自身。这就是为什么以太网交换机被ISP连接客户使用:客户处于一个与ISP互联的一个二层网络,只能看到ISP的路由器,而看不到其它任何ISP客户的节点。在Calico中有类似的作用。
为了解决第1节提到的问题,我们在Calico环境下重新讨论这些问题:
- 大量的终端(end points)。在Calico网络中,以太网互联网络只能看到路由器/宿主服务器,而不是真正的终端(VM/容器)。这样,在一个每台服务器中存在数十个VMs(或者几百个容器)的标准云模型里,以太网看到(需要去学习的)的节点数量减少了一到两个数量级。甚至在一个非常大的Pod中(号称两万台服务器),以太网络仍旧只需要学习几万个终端路径。这是在每个TOR交换机能力范围内的数量。
- 网络中高速的翻动(churn)。经典以太网数据中心中,一个终端被创建、销毁或者移动都会触发一次翻动事件。一个数十万终端大型数据中心,翻动事件的平均值是每秒发生数十次,而峰值可以达到每秒可数万次。而在Calico网络中,翻动是非常低的。只有在服务器、交换机或者物理链路的增加和减少时,才会导致一次翻动事件。
- 大量的广播流量。由于在Calico网络中的任何流量的第一跳(也是最后一跳)都是一个IP跳转,IP 跳转终止了广播流量。实际上,在以太网结构中能够唯一看到的广播流量是宿主服务器之间彼此定位的ARPs。
- 生成树。根据以太网结构架构选择的不同,甚至可以关闭生成树协议。然而,随着节点数量的减少,翻转事件的减少,大部分生成树的实施都可以在负载允许范围内执行。
综上,在二层以太网互联网上运行Calico网络,是可行并且实用的。
二层以太网互联和三层IP互联都可以作为Calico网络实施基础,不同的是二层以太网互联则更没有那么多架构方面的因素需要考虑,而三层IP互联需要考虑的更多。
3 关于以太网拓扑的简要说明
本文以最常见的Spine/Leap二层以太网结构加以说明。
Calico是IP路由互联结构,可以使用ECMP在多条链路上负载分发流量(而不是使用如M-LAG等以太网技术)。凭借Calico宿主机上的ECMP负载均衡,仅需要在Calico节点运行IP路由(不需要引入其他技术),就能构建由多个独立leaf/spine平面组成的互联结构。这些平面可以完全独立运行,而不用共享同一个故障域。这将允许一个(或多个)平面以太网互连结构发生灾难性故障时,不会损失整个pod(故障只会减少pod的互连带宽),这是一种比起整个Pod范围发生IP或者以太网故障来说相对温和的故障情况。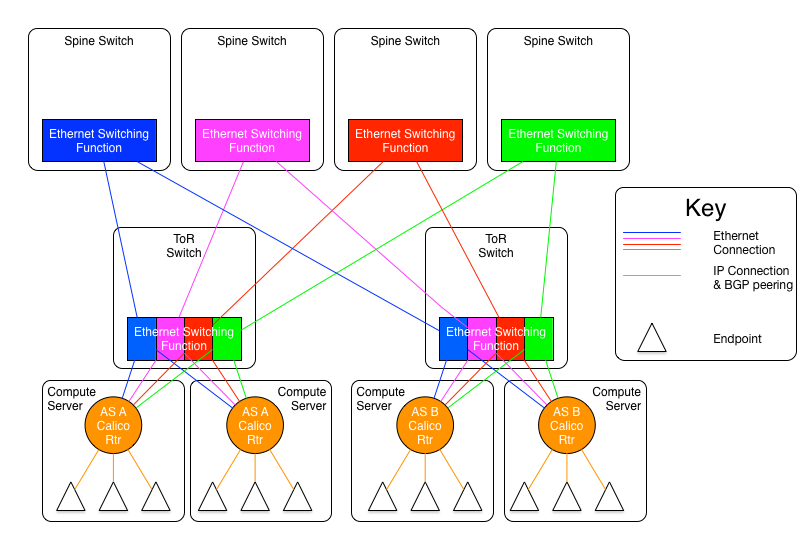
在上图所示模型中,endpoints对互联结构上发生的任何事情都无从感知。
在上图所示模型中,ToR被分成了四个逻辑交换机(使用VLAN),每台宿主机到ToR上的每个逻辑交换机都一条连接。我们使用蓝、绿、橙、红四种不同的颜色去标识这些逻辑交换机。每个颜色的逻辑交换机都是该颜色平面的成员,所以对应就有蓝、绿、橙、红四个平面。每个平面都有一个专用的spine交换机,每个ToR上对应颜色的逻辑交换机都会与相同颜色的spine交换机相连,不同颜色的逻辑交换机与spine交换机之间没有连接关系。
每个平面都是形成一个IP网络,蓝色平面可能是2001:db8:1000::/36,绿色平面可能是2001:db8:2000::/36,橙色和绿色则是2001:db8:3000::/36和2001:db8:4000::/36。
每个IP网络(交换平面)需要它自己的BGP路由反射器。同一平面内的路由反射器之间需要建立对等体关系,而不同平面的反射器则不需要。所以,四个平面组成的互联结构应该有四个全互联的路由反射器组。每个宿主机,边界路由器及其他三层设备,要求成为每个平面内至少一个路由发射器的客户端,最好是2个或者更多。
下图显示了路由反射器环境的互联结构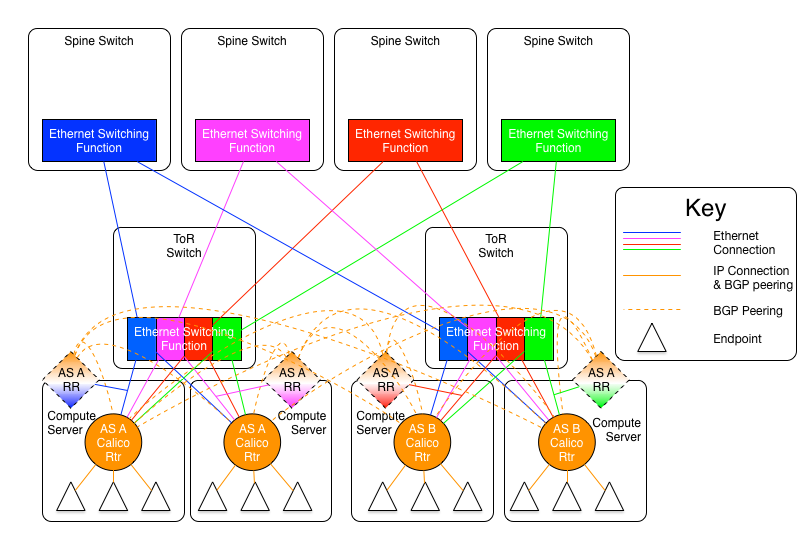
这些路由反射器可以是连接到spine交换机的专门的硬件(或者spine交换机自己启用路由反射器服务),也可以是连接到逻辑leaf交换机的物理/虚拟路由反射器。它可能是一个运行在宿主机上,拥有直连到当前平面连接的路由反射器,并且它不能通过vRouter进行路由,避免先有蛋还是先有鸡的问题。
当然还存在其他的物理和逻辑方案,这里仅仅是一个可行的例子。
逻辑配置使每个宿主机在每个平面的IP网络中都有一个IP地址,并在每个IP网络上宣告自己的endpoines。如果开启了ECMP,那么宿主机将使用所有平面进行流量的负载分担。
如果一个平面失效(如生成树故障),那么只会有一个平面停止转发,其余平面将继续正常运行。