1、计数排序



# -*- coding: utf-8 -*- # @Time : 2018/07/31 0031 11:32 # @Author : Venicid def count_sort(li, max_num): count = [0 for i in range(max_num + 1)] for num in li: count[num] += 1 i = 0 for num, m in enumerate(count): for j in range(m): li[i] = num i += 1 import random data = [] for i in range(100000): data.append(random.randint(0,100)) count_sort(data, 100) print(data)
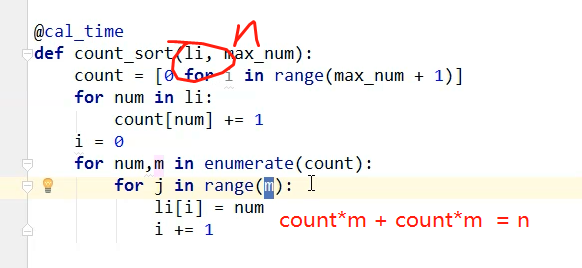
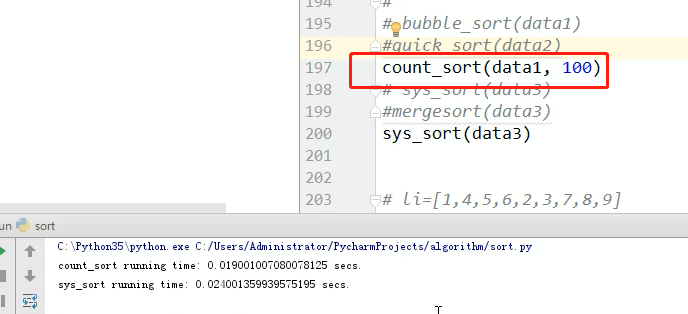
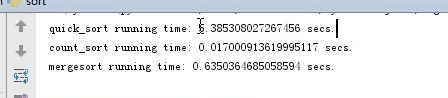
计数排序这么快,为什么不用计数排序呢?因为他是有限制的,你要知道列表中的最大数
如果一下来了一个很大的数,比如10000,那么占的空间就的这么大,
计数排序占用的空间和列表的范围有关系
解决这种问题的方法,可以用桶排序,都放进去可以在进行其他的排序。比如插入排序。
2、TOP10榜单:topk

(1)方式1:思路:插入排序 O(kn)
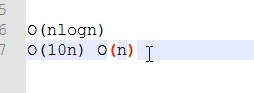







# -*- coding: utf-8 -*- # @Time : 2018/07/31 0031 11:59 # @Author : Venicid def insert(li, i): """一次insert""" tmp = li[i] j = i - 1 while j >= 0 and li[j] > tmp: li[j + 1] = li[j] j = j - 1 li[j + 1] = tmp def insert_sort(li): for i in range(1, len(li)): # 从第二个位置,即下标为1的元素开始向前插入 insert(li,i) def topk(li, k): top = li[0:k + 1] # top10, 多开辟一个存放,新进来的数据 insert_sort(top) for i in range(k + 1, len(li)): top[k] = li[i] insert(top, k) return top[:-1] # 去掉最后一个 import random data = list(range(20)) topk_ = random.shuffle(data) print(data) print(topk(data, 10))

(2)方式2:堆的应用:nlogk

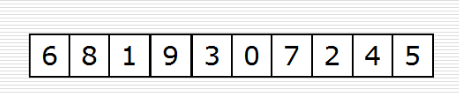
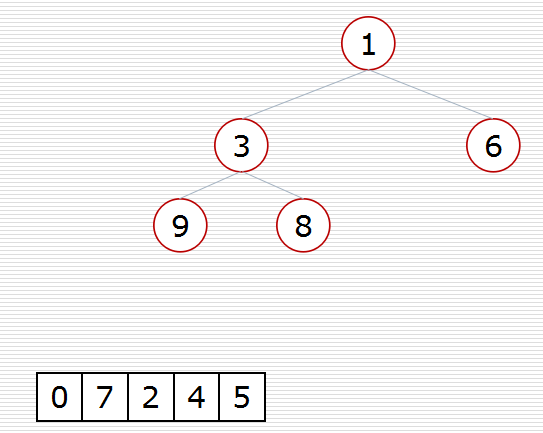
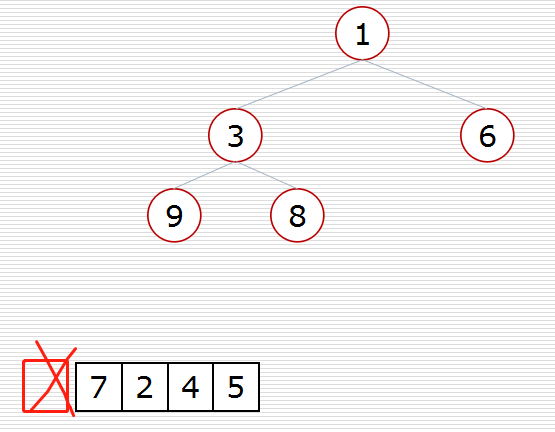
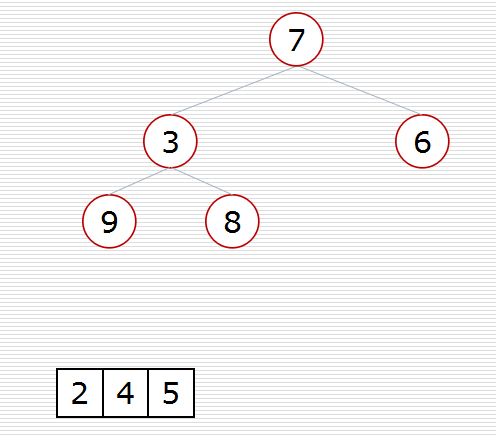
def sift(data, low, high): """调整""" i = low # 父亲的位置 j = 2 * i + 1 # 孩子的位置 tmp = data[i] # 原省长退休 while j <= high: # 孩子在堆里 if j + 1 <= high and data[j] < data[j + 1]: # if右孩子存在且右孩子更大 # if j + 1 <= high and data[j] > data[j + 1]: # if右孩子存在且右孩子更大 j += 1 if data[j] > tmp: # 孩子比最高领导大 # if data[j] < tmp: # 孩子比最高领导大 data[i] = data[j] # 孩子上移一层 i = j # 孩子成为新父亲 j = 2 * i + 1 # 新孩子 else: break data[i] = tmp # 省长放到对应的位置上(村民/叶子节点) def topn(li, n): heap = li[0:n] # 建堆 for i in range(n // 2 - 1, -1, -1): sift(heap, i, n - 1) # 遍历 for i in range(n, len(li)): if li[i] < heap[0]: # if li[i] > heap[0]: heap[0] = li[i] sift(heap, 0, n - 1) for i in range(n - 1, -1, -1): # i指向堆的最后 heap[0], heap[i] = heap[i], heap[0] # 领导退休,刁民上位 sift(heap, 0, i - 1) # 调整出新领导 return heap import random data = list(range(20)) topk_ = random.shuffle(data) print(data) print(topn(data, 10))

3、heapq实现堆排序


python官方文档
https://docs.python.org/3/library/index.html



# -*- coding: utf-8 -*- # @Time : 2018/07/31 0031 15:07 # @Author : Venicid import heapq import random h = [] data = list(range(10000)) random.shuffle(data) # heapq.heappush(h,1) # [1] # 生成小栈堆 for num in data: heapq.heappush(h, num) print(h) #[0, 1, 2, 4, 3, 5, 7, 8, 6, 17, # 出数 for i in range(len(h)): print(heapq.heappop(h)) # top最大 top最小的 print(heapq.nsmallest(10, data)) print(heapq.nlargest(10, data))

