MQ是什么?RabbitMQ是什么?AMQP是什么?
消息队列( messagequeuing )使用消息将应用程序连接起来。这些消息通过像RabbitMQ 这样的消息代理服务器在应用程序之间路由。这就像是在应用程序之间放置一个邮局。
RabbitMQ是一个消息代理和队列服务器。
AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品、不同开发语言等条件的限制。Erlang中的实现有RabbitMQ
消息队列的工作方式(理解消息通信)
生产者 消费者代理服务器
生产者( producer)创建消息,然后发布(发送)到代理服务器( RabbitMQ )。生产者将信息发送给Exchange并带有一个routing key,消费者从队列中获取消息。
消息
什么是消息呢?消息包含两部分内容:有效载荷( payload )和标签( label )。有效载荷就是你想要传输的数据。标签描述了有效载荷,并且RabbitMQ 用它来决定谁将获得消息的拷贝。举例来说,不同于TCP 协议的是,当你明确指定发送方和接收方时, AMQP 只会用标签表述这条消息(一个交换器的名称和可选的主题标记),然后把消息交由Rabbit。 Rabbit会根据标签把消息发送给感兴趣的接收方。这种通信方式是一种“发后即忘”( fire-and-forget )的单向方式。
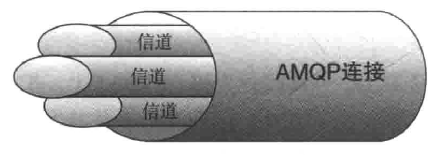
信道Channel
你必须首先连接到Rabbit ,才能消费或者发布消息。你在应用程序和Rabbit 代理服务器之间创建一条TCP 连接。一旦TCP 连接打开(你通过了认证),应用程序就可以创建一条AMQP 信道。信道是建立在“真实的” TCP 连接内的虚拟连接。AMQP 命令都是通过信道发送出去的。每条信道都会被指派一个唯一ID ( AMQP库会帮你记住ID 的)。不论是发布消息、订阅队列或是接收消息,这些动作都是通过信道完成的。你也许会问为什么我们需要信道呢?为什么不直接通过TCP 连接发送AMQP 命令呢?主要原因在于对操作系统来说建立和销毁TCP 会话是非常昂贵的开销。假设应用程序从队列消费消息,并根据服务需求合理调度线程。假设你只进行TCP 连接,那么每个线程都需要自行连接到Rabbit。也就是说高峰期有每秒成百上千条连接。这不仅造成TCP 连接的巨大浪费,而且操作系统每秒也就只能建立这点数量的连接。国此,你可能很快就碰到性能瓶颈了。如果我们为所有线程只使用一条TCP 连接以满足性能方面的要求,但又能确保每个线程的私密性,就像拥有独立连接一样的话,那不就非常完美吗?这就是要引人信道概念的原因。线程启动后,会在现成的连接上创建一条信道,也就获得了连接到Rabbit 上的私密通信路径,而不会给操作系统的TCP 械造成额外负担,如图2.2 所示。因此,你可以每秒成百上千次地创建信道而不会影响操作系统。在一条TCP 连接上创建多少条信道是没有限制的。把它想象成一束光纤电缆就可以了。
队列Queue
创建队列:消费者和生产者都能使用AMQP 的queue.declare 命令来创建队列。但是如果消费者在同一条信道上订阅了另一个队列的话,就无法再声明队列了。必须首先取消订阅,将信道置为“传输”模式。当创建队列时,要指定队列名称。如果不指定队列名称的话, Rabbit 会分配一个随机名称并在queue.declare 命令的响应中返回。
是该由生产者还是消费者来创建所需的队列呢?
你首先需要想清楚消息的生产者能否承担得起丢失消息。发送出去的消息如果路由到了不存在的队列的话, Rabbit 会忽略它们。因此,如果你不能承担得起消息进入“黑洞”而丢失的话,你的生产者和消费者就都应该尝试去创建队列。另一方面,如果你能承担得起丢失消息,或者你实现一种方法来重新发布未处理的消息的话(我们会向你展现如何做到这一点儿你可以只让自己的消费者来声明队列。
如果尝试声明一个已经存在的队列会发生什么呢?只要声明参数完全匹配现存的队列的话, Rabbit 就什么都不做并成功返回就好像这个队列已经创建成功一样(如果参数不匹配的话,队列声明尝试会失败)。
订阅队列:消费者订阅队列时需要队列名称,并在创建绑定时也需要指定队列名称。
AMQP消息路由Exchange Queue Binding
AMQP消息路由必须有三部分:交换器、队列和绑定。生产者把消息发布到交换器上;消息最终到达队列,并被消费者接收;绑定决定了消息如何从路由器路由到特定的队列。
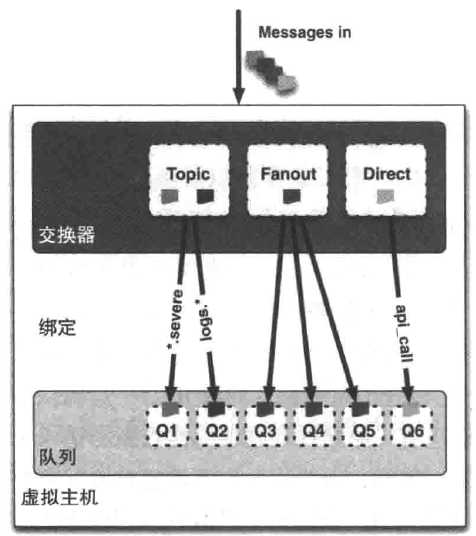
Direct:如果消息的routing key与binding的routing key直接匹配的话,消息将会路由到该队列上;
Topic:如果消息的routing key与binding的routing key符合通配符匹配的话,消息将会路由到该队列上;
Fanout:不管消息的routing key和参数表的头信息/值是什么,消息将会路由到所有队列上。
你可以只运行一个Rabbit ,然后按需启动或关闭vhost
消息不丢失的解决方案
解决某个消费者挂掉消息丢失的问题
消费者可以通过AMQP 的basic.ack 命令显式地向RabbitMQ 发送一个确认,或者在订阅到队列的时候就将auto_ack 参数设置为true 。当设置了auto_ack=true 时,一旦消费者接收消息,RabbitMQ 会自动视其确认了消息。
而当auto_ack=false时,需要消费者通过确认命令告诉RabbitMQ 它已经正确地接收了消息,同时RabbitMQ才能安全地把消息从队列中删除。
解决rabbitmq自己挂掉消息丢失的问题
RabbitMQ 确保持久性消息能从服务器重启中恢复的方式是,将它们写入磁盘上的一个持久化日志文件。当发布一条持久性消息到持久交换器上时, Rabbit 会在消息提交到日志文件后才发送响应。
消息队列解决了什么问题?
开发人员,想要解决的这个问题就是处理庞大的实时信息,并把它们快速路由到众多的消费者。我们要在不阻塞消息生产者的情况下做到这一点,同时也无须让生产者知道最终消费者是谁。RabbitMQ 帮助我们轻松解决这些常见问题,并用一种基于标准的方法来确保应用程序之间相互通信。
rabbitmq支持的语言很多
Python
Java
Ruby
PHP
C#
JavaScript
Go
Elixir
Objective-C
Swift
SpringAMQP
异步处理
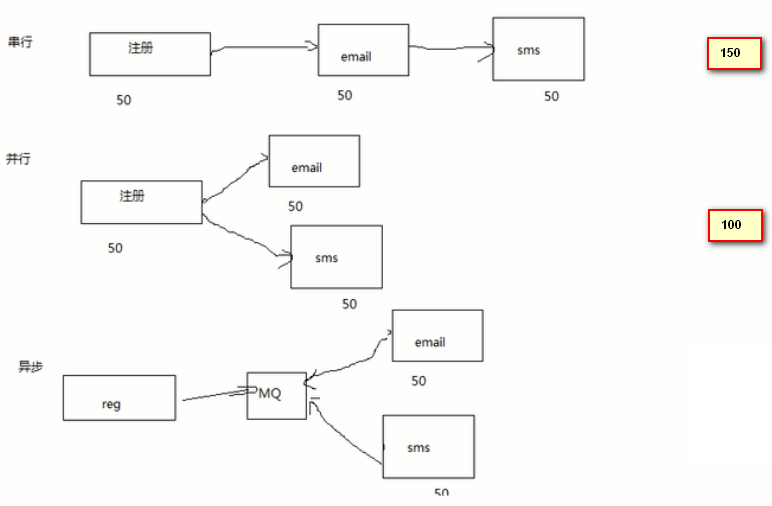
email和sms系统异步消费mq中的消息,与直接发送Email或sms所花费的时间相比,发送消息给队列所花
费的时间少很多
应用解耦
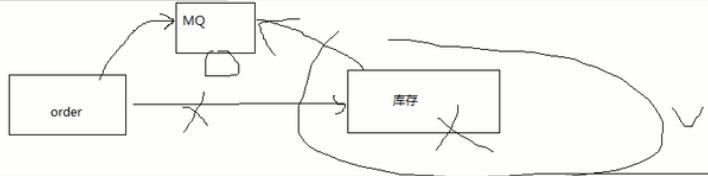
商品订单服务要访问库存服务,如果库存服务挂掉了,那么订单服务无法使用了。
如果加入一个MQ,order服务通过mq订阅库存服务,即便库存服务停掉了,再上线后可以继续处理order服务的请求
流量削锋
(秒杀用的很多)
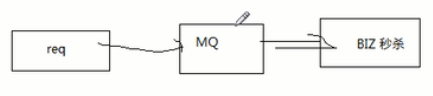
大数据日志收集消息中间件应用场景
(大数据)某个广告位uv,pv,ip,浏览器
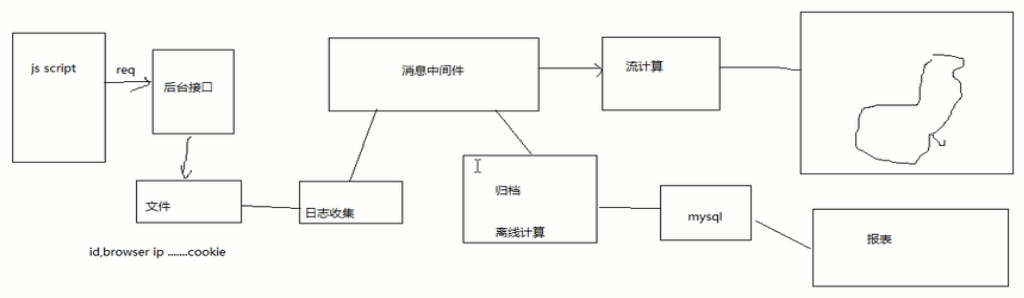
1. js script发送req内容到后台收集接口,如baidu hm.js--百度统计的JS脚本
2. 后台接口接收到数据,异步的写(因为数据量大,不能写到数据库中,因为有行锁)到文件中
3. 对日志文件进行收集,有td-agent(多个进程),logstash等日志收集组件
4. 发送到消息中间件datahoop kafka
5. 两个方向
一是流计算,显示实时值,显示到一个大屏幕上
二是归档,导入到数据库中,方便进行离线计算,如生成报表等
消息中间件在搜索系统DIH中的应用
DIH:data import handler
需求:
实现数据增删改在搜索系统中的实时更新效果?
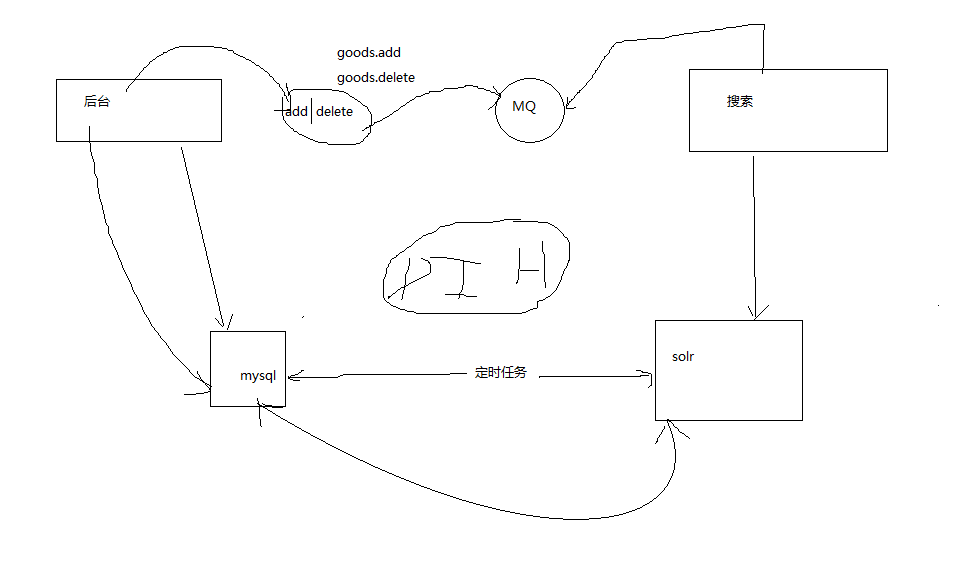
mysql中的内容一般通过定时任务,如每天指定时间更新到solr中,如何实现伪实时的效果呢?
搜索程序消费mq中的消息,直接更新solr,这样每当增删改操作之后,solr都会对应修改,实现伪实时效果
商城整合RabbitMQ
后台管理系统修改、新增商品、删除要通知到其他系统,其他系统要接受到消息,完成自己的业务逻辑。
后台系统:发送消息到交换机。
前台系统:接受消息,更新、删除的消息。
搜索系统:接受消息,新增、更新、删除的消息。