KeepAlive 与 Keep-Alive
前言
昨天被问到了HTTP中Keep-Alive的概念,看名字我只知道是保持连接用的,但是对于他怎么结束连接,为什么要用他这些就不是很清楚了,今天查了一下资料,然后总结一下吧。
然后发现keepalive是有两种的:
- TCP中的KeepAlive
- HTTP中的Keep-Alive
TCP中的KeepAlive概念
都知道TCP建立连接是需要三次握手的,过程如下:
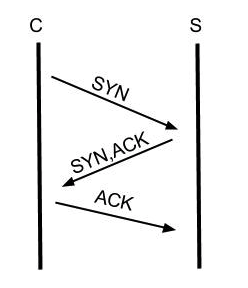
SYN/ACK这些都属于TCP的报文,等连接建立之后才会开始数据的传输,也就是这之后才会涉及到HTTP中的请求和应答的概念。也就是TCP/IP(OSI)模型中涉及到的分层的概念,HTTP属于应用层的东西,TCP是网络层的概念。
那么,假如TCP连接建立之后,如果应用程序一直不发送数据怎么办?或者很久才发一次,服务端该怎么处理呢?为了处理这种情况,TCP协议会过一段时间(可以设置)后去发送一个空报文给对方,若有响应则对方在线,保持连接;若没有反应,则进行重试,达到一定次数之后则认为连接已经丢失,没有必要再保持了。
上面这个过程就是TCP中KeepAlive的概念。
HTTP中的Keep-Alive
一个完整的HTTP事务如下:

事务包括链接建立/请求/响应/断开这几个过程,早期HTTP传输数据主要以文本为主,基本上一次请求就可以返回所有数据了,但是后面数据类型越来越复杂,一个链接可能就不行了,但是每次都重建TCP连接就有些浪费了,所以就有了HTTP中的Keep-Alive了。
HTTP1.0中默认关闭这个特性,需要在HTTP头中加入“Connection:Keep-Alive”开启;HTTP 1.1中默认启用,若加入“Connection:close”可关闭。
那么怎么判断数据是否已经传完呢?这里有2种方式:
- 使用消息首部字段Content-Length,意思就是加上一个长度,内容长度够了,则已经传完
- 没有Content-Length的时候(不容易判断数据大小的时候),可以使用“Transfer-Encoding:chunked”的方式来传输数据;即 chunk编码将数据分块传送,最后用一个长度为0的块表示结束
另外,需要注意:

总结
这些东西都属于在HTTP头部字段可以看到的,以前也看过,但是并没有深入,该反思。