这一段时间一直在学习关系型数据库,准备写一个小专题来总结一下这一段时间的学习结果。
一. 索引分类
还是写在前面,网上博客说了很多的索引类型,有些不知所云有些人云亦云,什么聚集索引,B+树索引,哈希索引,主键索引,唯一索引等等很多,一看是我看到的时候也是一脸懵逼,直到学习很多以后,才有了一些体系性的东西,故整理出来,希望帮助大家理解。
当然如果有谬误,也请批评指正。
1.1 从索引的组织形式:聚集索引和非聚集索引
1.1.1 聚集索引
聚集索引指的是索引的一种组织形式,而且是一种SQL规范。
聚集索引的定义:数据行在硬盘上的物理存储顺序和数据表中的逻辑存储顺序相同,一个表只能有一个聚集索引。
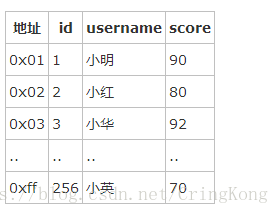
上图模拟了聚集索引的存储形式,如果我们在数据行id上建立聚集索引,那么整个表在磁盘上的存储顺讯,就是按照表中id的顺序进行存储。
同时也是因为这个原因,一张表上只能有一个聚集索引。
在Mysql中,InnoDB引擎默认按照主键索引进行聚集,当没有主键时,InnoDB会以唯一的非空索引来代替,如果没有主键也没有唯一的非空索引,InnoDB会生成一个隐藏的主键索引,然后在上面进行聚集。
所以主键(索引)的创建(聚集索引),尽量在建立表时创建,如果后续添加,数据库会根据聚集索引将磁盘的数据重新排列,以确保数据的物理存储顺序和索引列在表中的逻辑顺序相同。
聚集索引的查询过程。
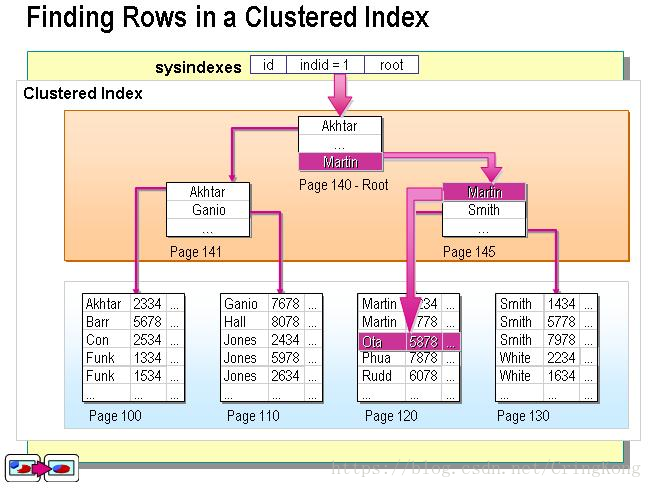
聚集索引的叶子结点就是对应的数据结点,可以直接查找到全部列的数据。
也就是说聚集索引的叶子结点存储结构就是数据在硬盘上的存储结构。
1.1.2 非聚集索引
非聚集索引和聚集索引很明显是相对立的概念。
非聚集索引的索引逻辑顺序和磁盘上存储的物理顺序不同,一个表可以有多个非聚集索引。
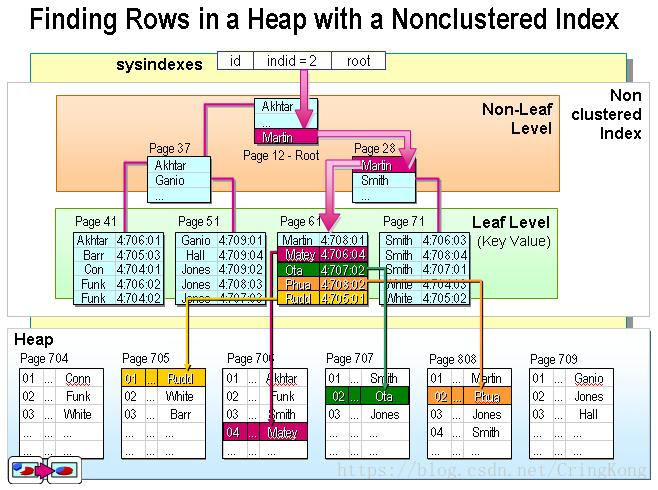
我们从上图可以看出,非聚集索引生成B+树的叶子结点,是建立索引的数据列和对应的数据行所在的地址。
也就是说如果建立非聚集索引,要查询建立索引列外的数据,需要进行二次检索。而聚集索引就不会出现这种情况,因为聚集索引的叶子结点就是全部的数据内容。
对于Mysql来说,我们平时对于某列或者多列建立的索引,就是非聚集索引,而InnoDB引擎中,因为必须有聚集索引,所以非聚集索中包括聚集索引的列(一般是主键列),InnoDB的二次查询,其实第二次是进行了聚集索引的检索查询。
1.2 从索引的底层数据结构来看:B+树索引和hash索引
1.2.1 B+树索引
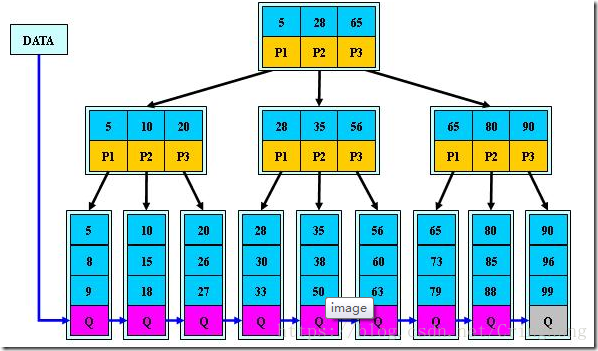
B+树是一种二叉查询树的变种,同时也是B树的升级版本。具体B树和B+树这种数据结构,我准备这几天整理一下发出来。
B+树索引就是基于B+树的一种索引方式,这种方式极大地减少了硬盘IO的次数,得益于B+树优良的性质,数据库只需要几次查询就能从大量数据中得到特定的存储数据。
数据库中的索引一般都是B+树索引,我上面提到的聚集索引和非聚集索引就是B+树索引。
对于Mysql来说,InnoDB和MyISAM引擎,建立的索引都是B+树类型的索引。B+树索引支持 =,>,<,IN,BETWEEN等条件查询方式。
1.2.2 hash索引
hash索引是基于hash表的一种索引,至于哈希表,参考哈希表这篇博文。
Mysql中支持hash索引的数据库引擎有memory引擎。
hash索引只支持 =的条件,对于那些范围查询,根据哈希表的性质,明显是不支持使用hash索引进行查询的。
1.2 从索引的建立方式:主键索引,唯一索引,普通索引,组合索引和全文索引
- 主键索引:主键索引很明显就是主键约束的实现方式,这种索引要求建立索引的内容不能相同而且不能为空。在Mysql中主键索引默认是聚集索引,因此查询速度更快。
- 唯一索引:唯一索引是唯一性约束的实现方式,这种索引要求建立索引的内容不能相同但可以为空,在Mysql中,建立唯一索引和添加唯一性约束效果是一致的。唯一索引可以是聚集索引(InnoDB中),也可以是非聚集索引。
- 普通索引:普通索引就是我们平常建立在数据上的索引,一般是非聚集索引,在InnoDB中普通索引中含有主键索引的内容和建立索引的数据内容。
- 组合索引:组合索引是多列共同建立的索引,要建立符合最左前缀原则的组合索引。
- 全文索引:全文索引是针对文本内容建立的索引,要指定索引的长度,通过
LIKE条件查询时可以使用,但是要满足不能有前导模糊查询的情况。
二.查询时会使用索引的情况
SQL什么条件会使用索引?
当字段上建有索引时,通常以下情况会使用索引:
INDEX_COLUMN = ?
INDEX_COLUMN > ?
INDEX_COLUMN >= ?
INDEX_COLUMN < ?
INDEX_COLUMN <= ?
INDEX_COLUMN between ? and ?
INDEX_COLUMN in (?,?,…,?)
INDEX_COLUMN like ?||’%’(后导模糊查询,这个是针对全文索引)
T1. INDEX_COLUMN=T2. COLUMN1(两个表通过索引字段关联)
三. 查询时不会使用索引的情况

四. 推荐建立索引的列

五. 最左前缀原则
所谓最左前缀原则指的是,建立组合索引时,例如
ALTER TABLE `table_name` ADD INDEX index_name (`col1`, `col2`, `col3` ) 那么查询时,如果 WHERE col1 = 1 AND col2=2这种条件语句查询,可以使用组合索引进行查询。
但是如果WHERE col2 = 2 AND col3 = 3这种条件语句,就不会使用组合索引查询。
也就是说要满足从左向右的索引顺序进行匹配,如果没有左面的列而有右面的列,那么就不满足最左前缀原则。
你可以认为联合索引是闯关游戏的设计
例如你这个联合索引是state/city/zipCode
那么state就是第一关 city是第二关, zipCode就是第三关
你必须匹配了第一关,才能匹配第二关,匹配了第一关和第二关,才能匹配第三关
你不能直接到第二关的
索引的格式就是第一层是state,第二层才是city
索引是因为B+树结构 所以查找快 如果单看第三列 是非排序的。
多列索引是先按照第一列进行排序,然后在第一列排好序的基础上再对第二列排序,如果没有第一列的话,直接访问第二列,那第二列肯定是无序的,直接访问后面的列就用不到索引了。
参考资料: