字典,文件,异常
字典
以代码示例
x={"a":"哈哈哈","b":"嘿嘿嘿","c":"h呵呵呵",1:"呦呦呦"}
print("输出a对应得值:",x["a"])
输出为
输出a对应得值: 哈哈哈可以看出[ ]包起来的是列表,()包起来的是元组{}包起来的就是字典了(个人好记这样说的)
所以x[“a”]即为索引值
同理我们可以得出以下代码
x=dict(a="哈哈哈",b="呵呵呵",c="嘿嘿嘿")
print(x)
print(x["a"])
x["b"]="啦啦啦啦"
print(x)
输出如下
{'a': '哈哈哈', 'b': '呵呵呵', 'c': '嘿嘿嘿'}
哈哈哈
{'a': '哈哈哈', 'b': '啦啦啦啦', 'c': '嘿嘿嘿'}所以可得出:(以上述代码示例)x为字典里面保存了abc,输出x即为字典的内容,而x[“a”]为索引,即为选择x里面为a代表的是什么,同时x[“b”]=”啦啦啦啦”即为改变x里面b代表的值,为啦啦啦啦,最后输出
同时字典也含有增加删除功能:
a=dict(x="喂喂喂",c="嘤嘤嘤",z=2)
print(a["x"])
print(a)
a["x"]="哈哈哈"
a["a"]=2
del a["c"]
print(a.pop("z"))
print(a)
输出为
喂喂喂
{'x': '喂喂喂', 'c': '嘤嘤嘤', 'z': 2}
2
{'x': '哈哈哈', 'a': 2}所以可以看出
a字典里面有“x”和“c”两个键,第一个print输出了x的内容第二个输出了全部,而a[“x”]则是更改了原本x的内容为“哈哈哈”,a[“a”]=2则是增加了一个叫a的键他的内容是2,而del a[“c”]则是删除了原本字典里面的“c”键,从而最后输出。print(a.pop(“z”))的意思是删除“z”键,并且输出删除的东西的内容
下面介绍一个可以创建,查看字典的方法
cc={}
print(cc.fromkeys((1,2,3),"a"))
输出
{1: 'a', 2: 'a', 3: 'a'}使用fromkeys构造了一个字典
同时可以用Items values Keys进行查看,代码如下
xx={1: 'a', 2: 'a', 3: 'a'}
for i in xx.values():
print(i)
for i in xx.keys():
print(i)
for i in xx.items():
print(i)
输出为
a
a
a
1
2
3
(1, 'a')
(2, 'a')
(3, 'a')
可以看出values输出的是索引值而keys输出的是索引items输出的是字典的内容
下面介绍清空字典
xx={1: 'a', 2: 'a', 3: 'a'}
print(xx.clear)
输出为
None所以只需要调用clear就可以清空字典
如果想复制字典有以下两种方法
xx={1: 'a', 2: 'a', 3: 'a'}
ccc=xx
z=xx.copy()
print(ccc)
print(z)
以上都可以输出xx
不过两者的区别是,ccc是直接赋值,z是复制文件
文件的读取
代码如下
f=open('E:\\python.txt')
print(f.read())
print(f.tell())
f.seek(47.0)
print(f.readline())以上代码输出为E盘下python的txt,f.read()为阅读此文件,f.seek() 为fileObject.seek(offset,[whence]) offset – 开始的偏移量,也就是代表需要移动偏移的字节数 whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。f.tell()为返回当前文件的内容的位置
文件的写入:代码如下
f1=open("E:\\haha.txt","w")
f1.write("我爱你")
f1.close()此时在E盘里面会有一个名字为haha的txt文件,打开后里面会有 我爱你 三个字
下面附上学习的一段代码
def save(boy,girl,count):
file_name_boy = "E:\\" + "boy" + str(count) + "txt"
file_name_girl = "E:\\" + "girl" + str(count) + "txt"
boy_file = open(file_name_boy, "w")
girl_file = open(file_name_girl, "w")
boy_file.writelines(boy)
girl_file.writelines(girl)
boy_file.close()
girl_file.close()
def split1(file_name):
f=open("E:\\python.txt")
boy=[]
girl=[]
count=1
for each_line in f:
if each_line[:6]!="======":
(role,line_spoken)=each_line.split(":",1)
if role=="小甲鱼":
boy.append(line_spoken)
if role=="小客服":
girl.append(line_spoken)
else :
save(boy,girl,count)
boy=[]
girl=[]
count=count+1
save(boy,girl,count)
f.close()
split1("python.txt")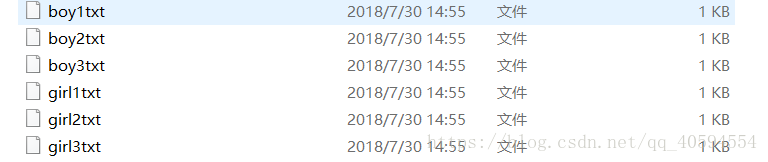
打开在E盘的python.txt文件,然后将此文件里面的数据读取,分别分在6个文件夹里面,其中使用了一个(role,line_spoken)=each_line.split(“:”,1)的方法下面介绍
str.split(str=”“, num=string.count(str)).
str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num – 分割次数。
他是返回分割后的字符串列表
代码示例如下
str = "asd \nqwe \nzxc"
print(str.split( ))
print(str.split(' ', 1 ))
输出为
['asd', 'qwe', 'zxc']
['asd', '\nqwe \nzxc']
文件模块:
import os
import time
print("工作目录:"+os.getcwd())#查看当前工作目录
print(os.listdir('E:\\'))#查看指定目录
os.mkdir("E:\\A")#在E盘下创建一个名为A的目录
os.mkdir("E:\\A\\B")#在E盘的A目录下创建一个B目录
os.remove("E:\\haha.txt")#删除E盘下的名为haha.txt的文件
os.rmdir("E:\\A\\B")#删除A目录下的B目录
os.chdir("E:\\")#将工作界面转换到E盘
os.rename("A","B")#将工作界面的A文件夹名字改为B
print(os.system("calc"))#运行系统命令(这个的意思是打开计算机)
print(os.path.basename("E:\\a\\b\\c.avi"))#去掉路径返回文件名
print(os.path.dirname("E:\\a\\b\\c.avi"))#去掉文件名返回路径
print(os.path.join("C:\\","A","B"))#合成为一个路径
print(os.path.split("E:\\a\\sea.avi"))#分离文件名和路径
print(os.path.splitext("E:\\a\\sea.avi"))#分离文件名与扩展名
print(time.localtime(os.path.getatime("E:\\B")))#返回文件创建时间
#为注释下面介绍一个包
import pickle
x=[1,5,8,3,8,"dasdas"]
f=open("E:\\B\\LALA.pickle","wb")
pickle._dump(x,f)
f.close()
f1=open("E:\\B\\LALA.pickle","rb")
c=pickle.load(f1)
print(c)上述代码的意思是,有为x的一个列表,创建一个名为LALA.pickle的文件,然后使用pickle._dump(x,f)将列表放在文件里面,然后关闭文件,再打开LALA.pickle,将其复制到c,输出c为[1,5,8,3,8,”dasdas”],这样我们就可以将大量的数据保存下来,再使用了
异常处理
try
检测范围
except Exception[as reason]
出现异常(Exception)后的处理代码
try:
f=open("我要打开这个")
print(f.read())
f.close()
except:
print("不好意思,找不到")
#try语句一旦被检查到异常,剩下的语句将不会被执行
try:
f=open("我要打开这个")
print(f.read())
f.close()
except OSError as reason:
print("不好意思,找不到,但是错误是:",str(reason))
这两个输出为:
不好意思,找不到
不好意思,找不到,但是错误是: [Errno 2] No such file or directory: '我要打开这个'try
检测范围
except Exception[as reason]:
出现异常(Exception)后的处理代码
finally:
无论如何都会被执行的代码 如下
try:
f=open("我要打开这个")
print(f.read())
f.close()
except:
print("不好意思,找不到")
#try语句一旦被检查到异常,剩下的语句将不会被执行
finally:
f=open("E:\\C.txt","w")
f.write("我要打开这个")
f = open("E:\\C.txt", "r")
print(f.read())
f.close()
输出为
不好意思,找不到
我要打开这个
上述代码创建了一个在E盘下的txt文档,然后输入了“我要打开这个”,然后read这个文档,输出如上