TCP IP协议是流协议,对上层协议来讲是没有边界的,主机A发送两个消息M1和M2,如下图所示:
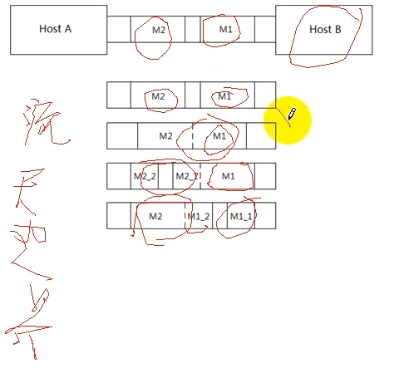
主机A发送了M1和M2,主机B在接收时有4种情况:
1、先收了M1,又收了M2
2、M1、M2一起收到了
3、M1和M2的一部分一起收到的,又收到了M2的一部分
4、先收到了M1的一部分,然后M1的下一部分和M2一起收到
说明:
tcp字节流无边界
udp消息是基于数据报的,是有边界的,可以不处理
对等方一次读操作,不能保证完全把消息读完
对方接收数据包的个数是不确定的
应用程序发数据时,先把数据写到socket的缓冲区里面,缓冲区的大小也是有规定的,当缓冲区写到一定程度,这时候TCP IP协议开始往对等方发数据。IP层有MSS最大数据报限制,如果数据包大于了MSS,则IP层会对数据分片,到对等方再进行组合。在链路层有MTU最大传输单元限制。
产生粘包的原因:
1、套接字本身有缓冲区(发送缓冲区、接受缓冲区)
2、tcp传送端的mss大小限制
3、链路层的MTU限制,如果数据包大于MTU,则要在IP层进行分片,导致消息分割
4、tcp的流量控制和拥塞控制,也可能导致粘包
5、tcp延迟发送机制
我们前几篇博客中的read函数是有bug的,但是我们的实验都是在局域网(在一个机器上)进行的,包传输较快,所以没有凸显出来。也就是在局域网上传输较快,先发送的包也先接收到了,没有出现粘包的现象。但是在公网传输时,延迟较大,如果我们不对流式数据包不进行处理,这时可能就会出现我们上面说的粘包现象了。真正的商用软件一定会进行粘包处理。
包之间没有边界,我们可以人为的造边界。
目前有两种处理方法:
1、在包之间加\r\n,ftp就是这样处理的。
2、在包之间加自定义报文。例如,在报文头之前加4个字节,指示后面的报文大小。