Conv2D函数
Keras的Conv2D类有很多参数,哪些是重要的?应该保留哪些默认值?
tensorflow.keras.layers.Conv2D(filters, kernel_size, strides=(1, 1),
padding='valid', data_format=None, dilation_rate=(1, 1),
activation=None, use_bias=True, kernel_initializer='glorot_uniform',
bias_initializer='zeros', kernel_regularizer=None,
bias_regularizer=None, activity_regularizer=None,
kernel_constraint=None, bias_constraint=None)参数1:filter
您可能需要根据(1)数据集的复杂性和(2)神经网络的深度来调整确切的值,建议您从[32,64,128]范围内的过滤器开始,然后逐渐增加最多为[256、512、1024]。

示例:这是设计CNN架构的常见做法。
model.add(Conv2D(32, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
...
model.add(Conv2D(64, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
...
model.add(Conv2D(128, (3, 3), padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
...
model.add(Activation("softmax"))参数2:kernel_size
首先必须是一个奇数整数,何时使用多大的尺寸?如果输入图像大于128×128,则可以选择使用大于3的内核大小来(1)学习更大的空间过滤器(2)帮助减小体积。如果图像小于128×128,则考虑使用1×1和3×3。

其他网络(例如VGGNet)专门使用(3 * 3)的过滤器。更先进的网络体系结构,如RESNET和SqueezeNet设计的结构,是在网络内部,局部采用不同的尺度(局部特征1×1 ,3×3 ,和5×5 ),然后结合输出。


参数3:strides
通常默认参数是(1 ,1 )但是有时可能会将其增加到(2 ,2 )以帮助减小输出的大小(因为滤波器的步长较大)。
参数4:padding
padding参数接收两个值,valid 或 same,默认值为valid,一般通常将其设置为same,然后通过以下两种方法之一来减小体积的空间尺寸:1、最大池化 2、交叉卷积

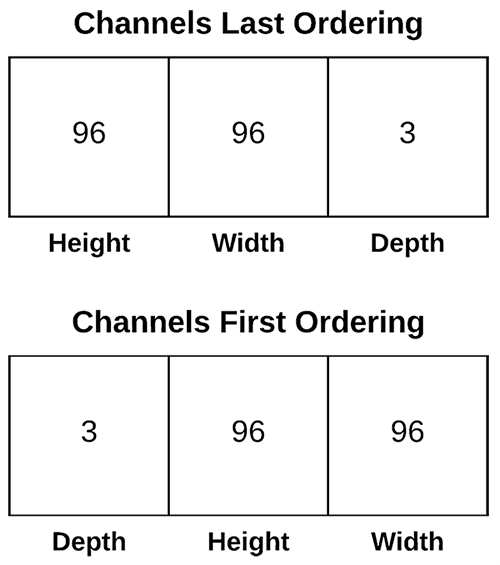
参数5:data_format
可选值是Channels_last 或者
Channels_first
参数6:dilation_rate
使用此参数的一般情况:
- 您正在使用更高分辨率的图像,但是细粒度的细节仍然很重要
- 您正在使用较少的参数构建网络

参数7: activation
允许您提供一个字符串,该字符串指定要在执行卷积后应用的激活函数的名称。
model.add(Conv2D(32, (3, 3), activation="relu"))
# 等同于
model.add(Conv2D(32, (3, 3)))
model.add(Activation("relu"))参数8: use_bias
参数控制是否将偏移量添加到卷积层。
参数:kernel_initializer和bias_initializer
参数:kernel_regularizer,bias_regularizer和activity_regularizer
当使用大型数据集和深度神经网络时,通常必须使用正则化。通常,遇到应用L1或L2正则化的情况—如果发现过拟合的迹象,在网络上使用L2正则化。应用的正则化量是需要针对自己的数据集进行调整的超参数,0.0001-0.001区间是一个比较适合的初始值。
from tensorflow.keras.regularizers import l2
...
model.add(Conv2D(32, (3, 3), activation="relu"),
kernel_regularizer=l2(0.0005))参数:kernel_constraint和bias_constraint
一般为默认值