线程(thread)技术早在60年代就被提出,但真正应用多线程到操作系统中去,是在80年代中期,solaris是这方面的佼佼者。传统的Unix也支持线程的概念,但是在一个进程(process)中只允许有一个线程,这样多线程就意味着多进程。现在,多线程技术已经被许多操作系统所支持,包括Windows/NT,当然,也包括Linux。
一、多线程是一种多人物并发的工作方式,具有以下几个优点?
1) 提高应用程序响应。这对图形界面的程序尤其有意义,当一个操作耗时很长时,整个系统都会等待这个操作,此时程序不会响应键盘、鼠标、菜单的操作,而使用多线程技术,将耗时长的操作(time consuming)置于一个新的线程,可以避免这种尴尬的情况。
2) 使多CPU系统更加有效。操作系统会保证当线程数不大于CPU数目时,不同的线程运行于不同的CPU上。
3) 改善程序结构。一个既长又复杂的进程可以考虑分为多个线程,成为几个独立或半独立的运行部分,这样的程序会利于理解和修改。
二、实例
线程是操作系统能够进行运算调度的最小单位(程序执行的最小单元),它被包含在进程之中,是进程中的实际运作单位,一个进程可以并发为多个线程,每条线程并行执行不同的任务(线程是进程中的一个实体,是被系统独立调度和分配的基本单元)
每一个进程启动时都会产生一个线程,即主线程,然后主线程回创建其他子线程
实例1
music和movie分别是俩个子线程,这两个进程可以同时执行,同时回执all over ,当1后再次执行music,当再过5s时,回执行movie这条语句
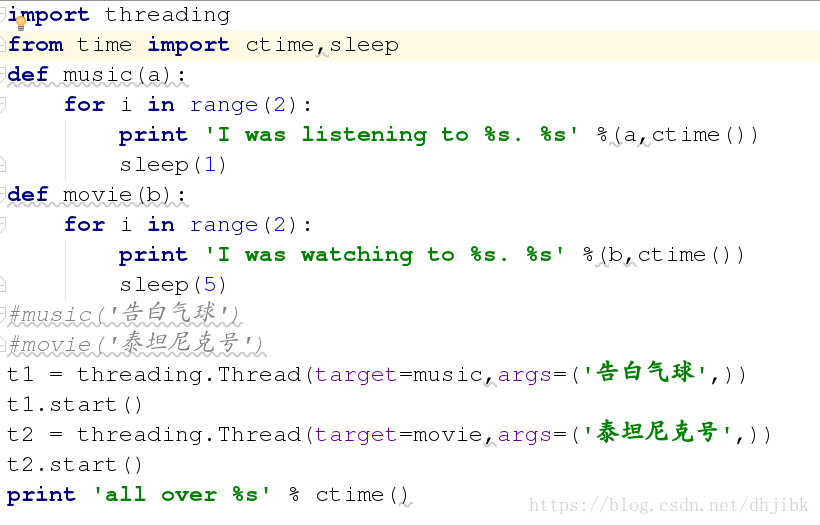
结果显示:

实例2:线程和函数建立关系
由于在python中的语句是单步执行的,编译一行解释一行,先是执行before语句再执行函数中的1,最后执行after语句。

结果显示如下:

如果我们将print ‘before‘语句写再函数的下面,那么先执行1,在执行after,最后执行before语句
如果将print ‘after’语句下在t1上面,那么将执行before,再执行after,最后执行1
实例3
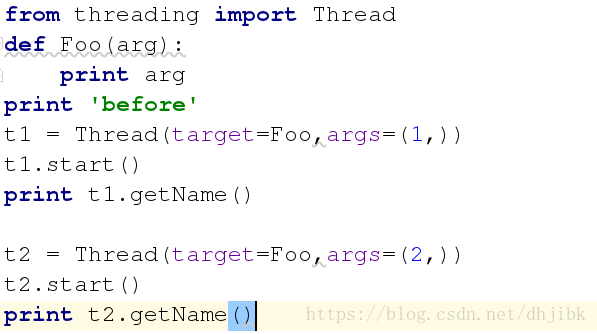
结果显示

实例4:子线程和主线程同时存在,当子线程执行完时,才会同时死亡

结果显示

实例5:子线程和主线程同时存在时,让主线程等子线程10s,没有执行完的继续在后台执行
通过setDaemon(true)来设置线程为“守护线程”;将一个用户线程设置为守护线程的方式是在 线程对象创建 之前 用线程对象的setDaemon方法。
生命周期:守护进程(Daemon)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。也就是说守护线程不依赖于终端,但是依赖于系统,与系统“同生共死”。那Java的守护线程是什么样子的呢。当JVM中所有的线程都是守护线程的时候,JVM就可以退出了;如果还有一个或以上的非守护线程则JVM不会退出

结果显示:注意这里,执行完主线程时,等待子线程10s,这里的10s包含主线程执行的1s,后面再执行子线程的东西,可以当执行了10s后,子线程还是没有执行完,继续在后台执行,而这里执行显示子线程和主线程执行了10s的结果

实例6

结果显示

三、操作系统(生产者和消费者之间的关系)
1、多线程能干什么?
生产者消费者问题:(经典)
一直生产 一直消费 中间有阀值 避免供求关系不平衡
线程安全问题,要是线程同时来,听谁的
锁:一种数据结构 队列:先进线出 栈:先进后出
2、生产者消费者的优点(为什么经典的设计模式)
1.解耦(让程序各模块之间的关联性降到最低)
假设生产者和消费者是两个类,如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合),
如果将来消费者的代码发生变换,可能会影响到生产者,而如果两者都依赖于某个缓冲区,两者之间不直接依赖,
耦合也就相应降低了
生活中的例子:我们 邮筒 邮递员
举个例子,我们去邮局投递信件,如果不使用邮筒(也就是缓冲区),你必须得把信直接交给邮递员,有同学会说,
直接交给邮递员不是挺简单的嘛,其实不简单,你必须得认识邮递员,才能把信给他(光凭身上的制服,万一有人假冒呢???),
这就产成你和邮递员之间的依赖了(相当于生产者消费者强耦合),万一哪天邮递员换人了,
你还要重新认识一下(相当于消费者变化导致修改生产者代码),而邮筒相对来说比较固定,
你依赖它的成本就比较低(相当于和缓冲区之间的弱耦合)
2.支持并发
生产者消费者是两个独立的并发体,他们之间是用缓冲区作为桥梁连接,生
产者之需要往缓冲区里丢数据,就可以继续生产下一个数据,而消费者者只需要从缓冲区里拿数据即可,
这样就不会因为彼此速度而发生阻塞
接着上面的例子:如果我们不使用邮筒,我们就得在邮局等邮递员,直到他回来了,我
们才能把信给他,这期间我们啥也不能干(也就是产生阻塞),或者邮递员挨家挨户的问(产生论寻)
3.支持忙闲不均
如果制造数据的速度时快时慢,缓冲区的好处就体现出来了,当数据制造快的时候,
消费者来不及处理,未处理的数据可以暂时存在缓冲区中,等生产者的速度慢下来,
消费者再慢慢处理
情人节信件太多了,邮递员一次处理不了,可以放在邮筒中,下次在来取
实例7

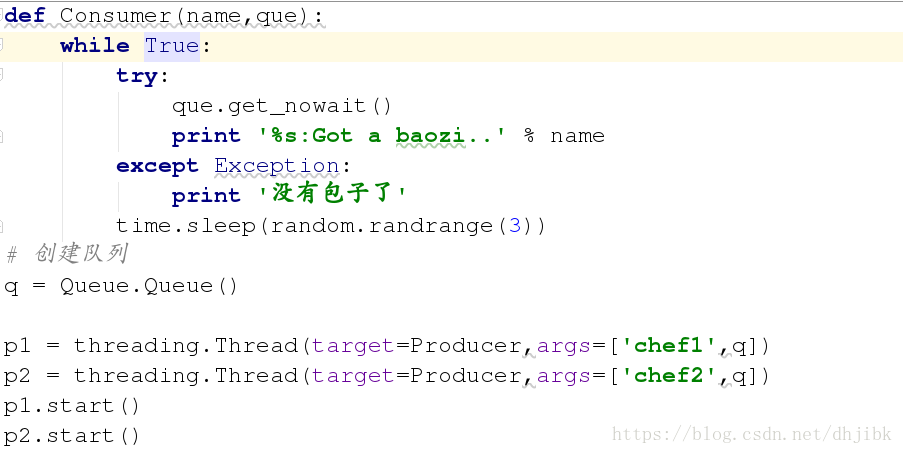

结果显示


实例8:事件驱动


结果显示

实例9:异步



结果显示
