(一)非结构化的处理和网络爬虫
1、网络爬虫,简单的就是将网页里面有用的数据爬取下来,将非结构化的网页数据转化成结构化的信息,并且将信息保存下来。
(二)网络爬虫的架构
1、爬虫的架构

(三)安装python以及所需库
(1)安装python本,可以根据自己的选择来安装python的版本,本文选择的是3.5.2。安装包的位置
链接:https://pan.baidu.com/s/1aOxYqT7XI6RbaCr-eJNMAQ 密码:8zc2
(2)安装python的所需要的包:
1、requests
是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到。可以说,Requests 完全满足如今网络的需求。
安装的的方式

如果提示pip不是内部或外部命令, 也不是可运行的程序或批处理文件。
解决办法:先到python的安装目录下面Python\Scripts文件下面,查看是否有pip文件

如果有的话,再到环境变量配置里面查找path路径,查看是否有上面的Python\Scripts路径,没有加上即可。加完环境变量之后,便可进行安装。
2、BeautifulSoup
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。
官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
安装的方式

from bs4 import BeautifulSoup
3、jupyter notebook
是一个交互式的笔记本,支持运行超过40种编程语言。本文中,我们将介绍Jupyter notebook的主要特点,了解为什么它能成为人们创造优美的可交互式文档和教育资源的一个强大工具。(当然也可以使用其他的IDE来写python,这个根据大家的喜好来。例如:Eclipse with PyDev Sublime Text PyCharm Wing,这几个编辑器都是小编用过的,用起来都还行)
安装的方式

使用的方式,是在控制台窗口输入jupyter notebook按下enter键

之后

点击new,python3出现编辑页面
一些jupyter的基本操作,可在网上查询一下。
4、pandas和sqlite3
Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
SQLite 是一个软件库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。SQLite 是在世界上最广泛部署的 SQL 数据库引擎。SQLite 源代码不受版权限制。
这两个库提供实现保存数据方法以及存储数据库。
安装的方式与上述相同使用pip install pandas
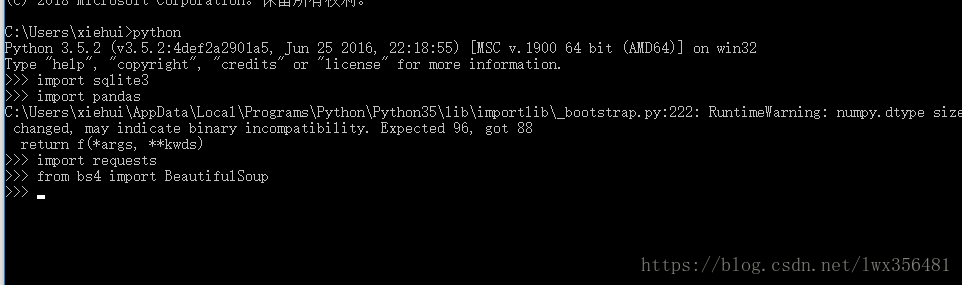
(四)验证上述安装库是否可用,用控制台输入python,开始python编程。然后导入刚才安装的库,如果没有报错,则库安装成功。
本文根据自己的学习所总结的一些内容,如有不足之处,请多多指教。
版权声明: 原创文章,如需转载,请注明出处! https://blog.csdn.net/lwx356481/article/details/81032229