集合框架图:
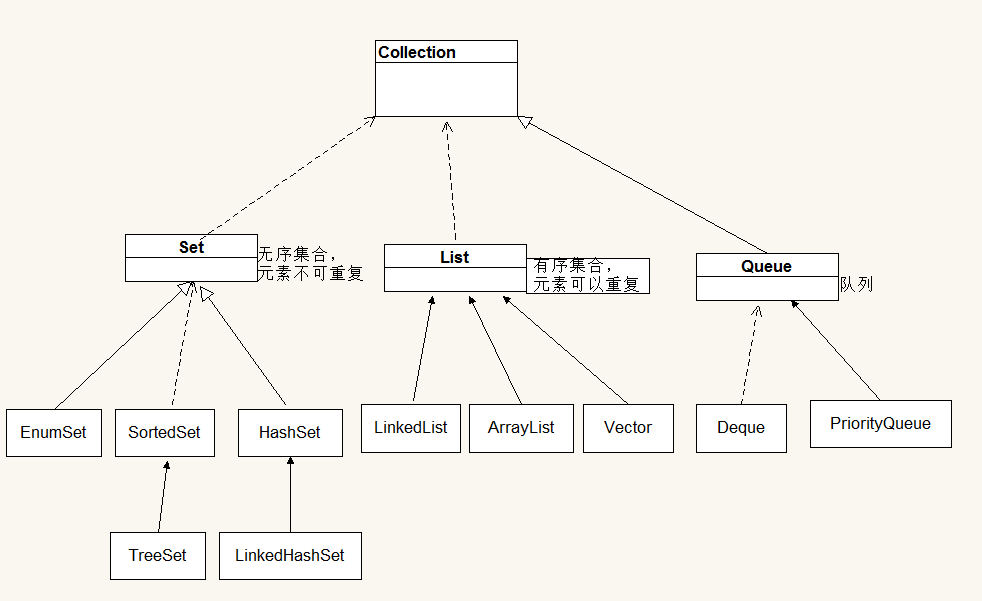
collection接口主要定义了一些操作集合元素的方法:
|
|
Ensures that this collection contains the specified element (optional operation).如果插入成功,返回true |
|
|
addAll Adds all of the elements in the specified collection to this collection (optional operation).改变返回true |
|
|
clear Removes all of the elements from this collection (optional operation). |
|
|
Returns true if this collection contains the specified element. |
|
|
containsAll Returns true if this collection contains all of the elements in the specified collection. |
|
|
Compares the specified object with this collection for equality. |
|
|
hashCode Returns the hash code value for this collection. |
。。。。。。具体可看文档
2.使用Iterator接口遍历几何元素
Iterrator接口隐藏了各种Collection实现类的细节,向应用程序提供了遍历Collection集合元素的统一编程接口。Iterator接口里定义了如下三个方法:
Boolean hashNext(): 如果被迭代的集合元素还没有被遍历,则返回true.
Object next(): 返回集合里的下一个元素。
Void remove(): 删除集合里上一次next方法返回的元素。
**当使用Iterator迭代访问Collection集合元素时,Collection集合里的元素不能被改变,只有通过Iterator的remove方法删除上一次next方法返回的集合元素才可以;否则将引发java.util.Concurrent ModificationException异常。
接下来分别介绍list和set集合
一、List集合
List集合代表一个元素有序,可重复的集合,集合中每个元素都有对应的顺序索引。List接口中增加了一些根据索引操作元素的方法:
void add(int index,E element ) 在列表的指定位置插入该元素。
boolean addAll(int index,Collection c) 将集合c包含的所有元素都插入到List集合的index处。
Object get(int index) 返回集合index索引出的元素。
。。。。。详见
1.ListIterator接口:List额外提供的一个listIterator()方法,提供了专门操作List的方法。
ListIterator接口在Iterator的基础上增加了如下方法:
boolean hasPrevious(): 返回该迭代器关联的集合是否还有上一个元素。
Object previous(): 返回该迭代器的上一个元素。
void add((E e): 在指定位置插入一个元素。
示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
输出结果:
我是帅哥
帅哥是我
==========下面开始反向迭代===========
-------分隔符-------
帅哥是我
-------分隔符-------
我是帅哥
输出完成 (耗时 0 秒) - 正常终止
2.ArrayList实现类和Vector实现类:
ArrayList和Vector是基于数组实现的list类,所以ArrayList和Vector封装了一个动态的,允许再分配的Object[]数组,不指定的话长度默认为10。ArrayList和Vector对象使用initialCapacity参数来设置该数组的长度,当向集合添加大量元素时,可以使用ensureCapac(int minCapacity)方法一次性的增加initialCapacity。
ArrayList和Vector在用法上几乎完全相同,但Vector比较古老,方法名比较长,最好是不使用。ArrayList是线程不安全的,Vector是线程安全的,但这个完全可以手动将一个ArrayList变成线程安全的。
ArrayList示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
输出结果:
---------- java运行 ----------
[轻量级J2EE企业应用实战, Struts2权威指南, 基于J2EE的Ajax宝典]
轻量级J2EE企业应用实战
ROR敏捷开发最佳实践
Struts2权威指南
基于J2EE的Ajax宝典
size:4
[轻量级J2EE企业应用实战, ROR敏捷开发最佳实践, 基于J2EE的Ajax宝典]
1
[轻量级J2EE企业应用实战, Struts2权威指南, 基于J2EE的Ajax宝典]
[Struts2权威指南]
输出完成 (耗时 0 秒) - 正常终止
二、Queue集合
Queue用于模拟队列这种数据结构,先进先出。
Queue接口定义的方法如下:
boolean add(E e): 将指定的元素插入此队列(如果立即可行且不会违反容量限制),在成功时返回 true,如果当前没有可用的空间,则抛出 IllegalStateException。
E element(): 获取队列头部元素,但不删除该元素。
boolean offer(E e): 将指定的元素插入此队列,当使用有容量限制的队列时,此方法通常要优于add(E)。
E peek(): 获取但不移除此队列的头;如果此队列为空,则返回 null。
E poll(): 获取并移除此队列的头,如果此队列为空,则返回 null。
E remove(): 获取并移除此队列的头。
1.PriorityQueue实现类
PriorityQueue是一个比较标准的队列实现类,之所以说比较标准,而不是绝对标准,是因为PriorityQueue保存队列元素的顺序并不是按加入队列的顺序,而是按队列元素的大小进行重新排序。
示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
输出结果:
---------- java运行 ----------
[-3, 0, 9, 6]
-3
输出完成 (耗时 0 秒) - 正常终止
2.Deque接口与ArrayQueue实现类
Deque接口是Queue接口的子接口,它代表一个双端队列,Deque接口里定义了一些双端队列的方法,允许从两端来操作队列的元素。
Void addFirst(Object e):将指定元素插入该双端队列的开头。
Void addLast(Object e):将指定队列插入该双端队列的末尾。
Iterator descendingIterator():返回该双端队列对应的迭代器,该迭代器将以逆向顺序来迭代队列中的元素。
Object getFirst(): 获取但不删除队列的第一个元素。
详细参考api
ArrayQueue是Deque接口的典型实现类,他是一个基于数组实现的双端队列,底部也是采用动态的、可重新分配的Object[]数组存储集合元素。
示例:把ArrayQueue当”栈“使用
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
输出结果:
[Android, java EE, java]
Android
[Android, java EE, java]
Android
[java EE, java]
**在现在的程序中需要使用“栈”这种数据结构时,推荐使用ArrayDeque或LinkedList,而不是Stack。
3.LinkedList实现类
LinkedList实现了List接口和Deque接口(好像图上没有画出来。。。。。),因此他是一个List集合还可以被当成双端队列来使用。
LinkedList与ArrayList,ArrayDeque的实现机制完全不同,ArrayList、ArrayDeque内部以数组的形式来保存集合中的元素,因此随机访问集合元素时有较好的性能;而LinkedList内部以链表的形式来保存集合中的元素,因此随机访问性能较差,但是插入、删除元素时非常快。
示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
输出结果:
Android
J2EE
Java
Android
Java
Android
[J2EE, Java]
Java
[J2EE]
**上面的代码分别示范了双端队列,栈的用法,所以LinkedList是一个功能非常强大的集合类。
4.各种线性表的性能分析:
| 实现机制 |
随机访问排名 |
迭代操作排名 |
插入操作排名 |
删除操作排名 |
|
| 数组 |
连续内存区保存元素 |
1 |
不支持 |
不支持 |
不支持 |
| ArrayList/ArrayDeque |
以数组保存元素 |
2 |
2 |
2 |
2 |
| Vector |
以数组保存元素 |
3 |
3 |
3 |
3 |
| LinkedList |
链表保存元素 |
4 |
1 |
1 |
1 |
示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
|
输出结果:
ArrayList集合添加元素的时间:446
LinkedList集合添加元素的时间:16
迭代ArrayList集合元素的时间:11
迭代LinkedList集合元素的时间:12
**可以看出LinkedList添加元素特别快,是ArrayList的几十倍,但遍历时不相上下。用foreach遍历LinkedList也比ArrayList快。
java中的集合到这里基本上总结完啦。。。
下篇会总结下操作集合的工具类:Collections,用它可以方便的把集合变成线程安全的。
二、set集合
Set集合的方法与Collection基本上完全一样,它没有提供额外的方法。实际上Set就是Collection,只是行为略有不同(Set不允许包含重复元素)。
Set判断两个对象是否相同是根据equals方法。也就是说,只要两个对象用equals方法方法比较返回false,Set就会接受这两个对象。
1.HashSet是Set的典型实现,HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。
特点:不能保证元素的排列顺序;不是同步的,不是线程安全;集合值可以是null。
HashSet集合判断两个元素的相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值也相等。
示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
|
输出:[B@1, B@1, C@2, A@659e0bfd, A@2a139a55]
可以看出HashSet把A,B当成两个对象,C只有一个。
2.LinkedHashSet类
LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起 来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
输出:[第二个, 第一个] 可以看到顺序是按插入顺序排列的。
3.TreeSet类
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序 和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0。向TreeSet中添加的应该是同一个类的对象,且最好是不可变对象。
1.自然排序
自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现了该接口的对象就可以比较大小。
obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是 负数,则表明obj1小于obj2。
如果我们将两个对象的equals方法总是返回true,则这两个对象的compareTo方法返回应该返回0
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
|
输出结果:
/*
---------- java运行 ----------
[R(count属性:-3), R(count属性:-2), R(count属性:5), R(count属性:9)]
[R(count属性:20), R(count属性:-2), R(count属性:5), R(count属性:-2)] //这里改变之后并没有重新排序,所以TreeSet中最好放不可改变的对象。
[R(count属性:20), R(count属性:-2), R(count属性:5), R(count属性:-2)] //删除-2失败,因为属性被改变
[R(count属性:20), R(count属性:-2), R(count属性:-2)] //没有改变的5可以删除
输出完成 (耗时 0 秒) - 正常终止*/
2.定制排序
自然排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(T o1,T o2)方法,该方法用于比较o1和o2的大小:如果该方法返回正整数,则表示o1大于o2;如果方法返回0,则表示o1等于o2,如果该方法返回负整数,则表示o1小于o2。
如果需要定制排序,则需要在创建TreeSet集合时提供一个Comparator对象与该TreeSet集合关联,由Comparator对象负责几何元素的排序逻辑:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
|
输出结果·(降序):[M age:9, M age:5, M age:-3]
4.各Set实现类比较:
HashSet和TreeSet是set的两个典型实现,HashSet的性能比TreeSet好(特别是最常用的添加,查询元素等操作).只有当需要一个保持排序的Set时,才应该使用TreeSet,否则使用HashSet
LinkedHashSet:对于普通的插入删除操作,比HashSet慢,遍历会更快。
另外:Set的三个实现类HashSet,TreeSet和EnemSet都是线程不安全的,如果有多个线程访问一个Set集合,则必须手动保持同步:
可用Collections的工具类:例如:
SortedSet s = Collections.synchronizedSortedSet(new TreeSet(…));
Set集合终于总结完啦。
转载请注明出处:http://www.cnblogs.com/jycboy/p/javalist.html