转发自https://blog.csdn.net/lis_12/article/details/52805591
Python xlrd
转载请标明出处(http://blog.csdn.net/lis_12/article/details/52805591).
xlrd下载:python官网下载http://pypi.python.org/pypi/xlrd模块.
用处
python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库.
基本操作
open_workook(excelfilename)
返回的类型是’xlrd.book.Book’,包含的操作见下表,
book = open_workbook(filename)
| 操作 | 解释 |
|---|---|
| book.sheetnames() | 返回excel中所有sheets的名字 |
| book.sheet_by_index(sheet_index) | excel中的sheet索引从0开始,获取索引为sheet_index处的工作表对象 |
| book.sheet_by_name(sheet_name) | 返回名字为sheet_name的工作表对象 |
| book.sheets() | 返回excel中所有的sheets的对象,list类型 |
| book.sheet_loaded(sheet_name_or_index = ‘Sheet1’) | 如果加载了sheets为‘Sheet1’的单元,则返回True;否则返回False,如果execl中不存在名为Sheet1的单元则抛出XLRDError |
| book.unload_sheet(self, sheet_name_or_index) | 索引为index或者表名为name的工作表不能再使用 |
book.sheet_by_index(sheet_index)
返回的类型是sheet对象,class ‘xlrd.sheet.Sheet’,包含的基本操作如下.
sheet = book.sheet_by_index(sheet_index)
ps:
等价于book.sheet_by_name(sheet_name),book.sheets()[sheet_index]
sheet_name为sheet_index的名字
| 操作 | 返回值 | 解释 |
|---|---|---|
| sheet.name | str,sheet名字 | 获取工作表名称 |
| sheet.nrows | int,行数 | 获取工作表的行数 |
| sheet.ncols | int,列数 | 获取工作表的列数 |
| sheet.row(rowx) | list,xlrd.sheet.Cell | 获取rowx行的所有单元对象 |
| sheet.row_values(num) | list,第num行的值 | 获取工作表中第num行的内容 |
| sheet.row_slice(rowx, start_colx=0, end_colx=None) | list,xlrd.sheet.Cell | 获取rowx行中,strat_colx->end_colx内的单元 |
| sheet.row_types(rowx, start_colx=0, end_colx=None) | list | 获取rowx行中,strat_colx->end_colx内的单元类型 |
| sheet.get_rows() | generator | 所有行的生成器 |
| sheet.col(colx) | list,xlrd.sheet.Cell | 获取colx列的所有单元对象 |
| sheet.col_values(num) | list,第num列的值 | 获取工作表中第num列的内容 |
| sheet.col_slice(colx,start_rowx=0, end_rowx=None) | list,xlrd.sheet.Cell | 获取colx列中,strat_rowx->end_rowx内的单元 |
| sheet.col_types(colx,start_rowx=0, end_rowx=None) | list | 获取colx列中,strat_rowx->end_rowx内的单元类型 |
| sheet.cell(rowx,colx) | xlrd.sheet.Cell | 获取rowx行,colx列的单元对象 |
| sheet.cell_value(rowx,colx) | rowx行,colx列的值 | 获取rowx行,colx列的值 |
| sheet.celltype(rowx,colx) | 返回单元的类型 | 获取(rowx,colx)处的类型 |
| shell.put_cell(row, col, ctype, value, xf = 0) | None | 修改(row,col)处的值,ctype为单元类型,(只是修改程序中此处的值,不会影响原文件) |
单元类型(ctype):
0 empty,1 string,2 number,3 date,4 boolean,5 errorcell对象对象主要使用的属性是value(值)和ctype(类型),可利用cell.value来获取单元的值
xf 为扩展的格式,一般设为0即可
code,使用示例
学习最好的方法就是实践,最好自己动手操作下,不要直接复制代码….
excel名字为test.xlsx,内容如下:
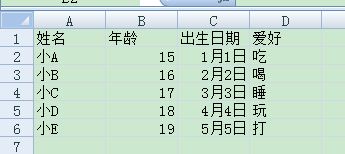
#!/usr/bin/python
# -*- coding: utf-8 -*-
import xlrd
def fun(filename = 'test.xlsx'):
global workbook,sheet1 #为了在IDLE中测试所加
workbook = xlrd.open_workbook(filename)
print workbook.sheet_names()#返回excel中所有的sheets的名字, [u'Sheet1', u'Sheet2', u'Sheet3']
print workbook.sheet_loaded('Sheet1')#如果加载了Sheet1的单元则返回True,其他为false,参数为索引或者sheet名称
#unload_sheet(self, sheet_name_or_index)调用此函数后,索引为index或者表名为name的工作表都不能再使用
sheets = workbook.sheets()
sheet1_index = workbook.sheet_by_index(0) # sheet索引从0开始
sheet1_name = workbook.sheet_by_name('Sheet1') #获取名字为Sheet1的工作表
print sheet1_index,(sheet1_index == sheets[0]) #<xlrd.sheet.Sheet object at 0x00000000037D6470> True
print sheet1_name #<xlrd.sheet.Sheet object at 0x00000000037D6470>
# sheet的名称,行数,列数
sheet1 = sheet1_index
print sheet1.name,sheet1.nrows,sheet1.ncols #Sheet1 6 4
# 获取整行和整列的值(数组)
rows = sheet1.row_values(3) # 获取第四行内容,值
cols = sheet1.col_values(1) # 获取第三列内容,值
print rows,type(rows) #[u'\u5c0fC', 17.0, 42432.0, u'\u7761'] <type 'list'>
for i in rows:
print i, #小C 17.0 42432.0 睡
print
for i in cols:
print i, #年龄 15.0 16.0 17.0 18.0 19.0
print
#获取单元格内容
print type(sheet1.cell(1,0))#<class 'xlrd.sheet.Cell'>
print sheet1.cell(1,0).value#单元格,小A
print sheet1.cell_value(1,0)#小A
print sheet1.row(3)[3].value# 睡
print type(sheet1.col(1)[0]),sheet1.col(1)[0].value#<class 'xlrd.sheet.Cell'> 年龄
#print help(sheet1.cell(1,0).ctype) type:0 empty,1 string,2 number, 3 date,4 boolean, 5 error
for i in range(4):
for j in range(4):
print sheet1.cell_type(i,j),#1 1 1 1 1 2 2 1 1 2 2 1 1 2 2 1
#cell对象
cell = sheet1.cell(1,0)
#print help(cell)
#put_cell
print sheet1.cell(2,1).value #16
sheet1.put_cell(2,1,2,100,0)
print sheet1.cell(2,1).value #100,但是不影响xlsx文件,里面内容不变
fun()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
参考网址
| 英文 | 解释 |
|---|---|
| sheet | 工作表 |
| workbook | 工作簿,工作手册,工作簿对象 |
| cell | 单元 |
| slice | 切片 |
转发自https://blog.csdn.net/lis_12/article/details/52805591
Python xlrd
转载请标明出处(http://blog.csdn.net/lis_12/article/details/52805591).
xlrd下载:python官网下载http://pypi.python.org/pypi/xlrd模块.
用处
python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库.
基本操作
open_workook(excelfilename)
返回的类型是’xlrd.book.Book’,包含的操作见下表,
book = open_workbook(filename)
| 操作 | 解释 |
|---|---|
| book.sheetnames() | 返回excel中所有sheets的名字 |
| book.sheet_by_index(sheet_index) | excel中的sheet索引从0开始,获取索引为sheet_index处的工作表对象 |
| book.sheet_by_name(sheet_name) | 返回名字为sheet_name的工作表对象 |
| book.sheets() | 返回excel中所有的sheets的对象,list类型 |
| book.sheet_loaded(sheet_name_or_index = ‘Sheet1’) | 如果加载了sheets为‘Sheet1’的单元,则返回True;否则返回False,如果execl中不存在名为Sheet1的单元则抛出XLRDError |
| book.unload_sheet(self, sheet_name_or_index) | 索引为index或者表名为name的工作表不能再使用 |
book.sheet_by_index(sheet_index)
返回的类型是sheet对象,class ‘xlrd.sheet.Sheet’,包含的基本操作如下.
sheet = book.sheet_by_index(sheet_index)
ps:
等价于book.sheet_by_name(sheet_name),book.sheets()[sheet_index]
sheet_name为sheet_index的名字
| 操作 | 返回值 | 解释 |
|---|---|---|
| sheet.name | str,sheet名字 | 获取工作表名称 |
| sheet.nrows | int,行数 | 获取工作表的行数 |
| sheet.ncols | int,列数 | 获取工作表的列数 |
| sheet.row(rowx) | list,xlrd.sheet.Cell | 获取rowx行的所有单元对象 |
| sheet.row_values(num) | list,第num行的值 | 获取工作表中第num行的内容 |
| sheet.row_slice(rowx, start_colx=0, end_colx=None) | list,xlrd.sheet.Cell | 获取rowx行中,strat_colx->end_colx内的单元 |
| sheet.row_types(rowx, start_colx=0, end_colx=None) | list | 获取rowx行中,strat_colx->end_colx内的单元类型 |
| sheet.get_rows() | generator | 所有行的生成器 |
| sheet.col(colx) | list,xlrd.sheet.Cell | 获取colx列的所有单元对象 |
| sheet.col_values(num) | list,第num列的值 | 获取工作表中第num列的内容 |
| sheet.col_slice(colx,start_rowx=0, end_rowx=None) | list,xlrd.sheet.Cell | 获取colx列中,strat_rowx->end_rowx内的单元 |
| sheet.col_types(colx,start_rowx=0, end_rowx=None) | list | 获取colx列中,strat_rowx->end_rowx内的单元类型 |
| sheet.cell(rowx,colx) | xlrd.sheet.Cell | 获取rowx行,colx列的单元对象 |
| sheet.cell_value(rowx,colx) | rowx行,colx列的值 | 获取rowx行,colx列的值 |
| sheet.celltype(rowx,colx) | 返回单元的类型 | 获取(rowx,colx)处的类型 |
| shell.put_cell(row, col, ctype, value, xf = 0) | None | 修改(row,col)处的值,ctype为单元类型,(只是修改程序中此处的值,不会影响原文件) |
单元类型(ctype):
0 empty,1 string,2 number,3 date,4 boolean,5 errorcell对象对象主要使用的属性是value(值)和ctype(类型),可利用cell.value来获取单元的值
xf 为扩展的格式,一般设为0即可
code,使用示例
学习最好的方法就是实践,最好自己动手操作下,不要直接复制代码….
excel名字为test.xlsx,内容如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import xlrd
def fun(filename = 'test.xlsx'):
global workbook,sheet1 #为了在IDLE中测试所加
workbook = xlrd.open_workbook(filename)
print workbook.sheet_names()#返回excel中所有的sheets的名字, [u'Sheet1', u'Sheet2', u'Sheet3']
print workbook.sheet_loaded('Sheet1')#如果加载了Sheet1的单元则返回True,其他为false,参数为索引或者sheet名称
#unload_sheet(self, sheet_name_or_index)调用此函数后,索引为index或者表名为name的工作表都不能再使用
sheets = workbook.sheets()
sheet1_index = workbook.sheet_by_index(0) # sheet索引从0开始
sheet1_name = workbook.sheet_by_name('Sheet1') #获取名字为Sheet1的工作表
print sheet1_index,(sheet1_index == sheets[0]) #<xlrd.sheet.Sheet object at 0x00000000037D6470> True
print sheet1_name #<xlrd.sheet.Sheet object at 0x00000000037D6470>
# sheet的名称,行数,列数
sheet1 = sheet1_index
print sheet1.name,sheet1.nrows,sheet1.ncols #Sheet1 6 4
# 获取整行和整列的值(数组)
rows = sheet1.row_values(3) # 获取第四行内容,值
cols = sheet1.col_values(1) # 获取第三列内容,值
print rows,type(rows) #[u'\u5c0fC', 17.0, 42432.0, u'\u7761'] <type 'list'>
for i in rows:
print i, #小C 17.0 42432.0 睡
print
for i in cols:
print i, #年龄 15.0 16.0 17.0 18.0 19.0
print
#获取单元格内容
print type(sheet1.cell(1,0))#<class 'xlrd.sheet.Cell'>
print sheet1.cell(1,0).value#单元格,小A
print sheet1.cell_value(1,0)#小A
print sheet1.row(3)[3].value# 睡
print type(sheet1.col(1)[0]),sheet1.col(1)[0].value#<class 'xlrd.sheet.Cell'> 年龄
#print help(sheet1.cell(1,0).ctype) type:0 empty,1 string,2 number, 3 date,4 boolean, 5 error
for i in range(4):
for j in range(4):
print sheet1.cell_type(i,j),#1 1 1 1 1 2 2 1 1 2 2 1 1 2 2 1
#cell对象
cell = sheet1.cell(1,0)
#print help(cell)
#put_cell
print sheet1.cell(2,1).value #16
sheet1.put_cell(2,1,2,100,0)
print sheet1.cell(2,1).value #100,但是不影响xlsx文件,里面内容不变
fun()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
参考网址
| 英文 | 解释 |
|---|---|
| sheet | 工作表 |
| workbook | 工作簿,工作手册,工作簿对象 |
| cell | 单元 |
| slice | 切片 |